Clear Sky Science · de
Meta-gelerntes dynamisches hierarchisches Fusionsverfahren für robuste multiskalige Objekterkennung
Warum schlauere Wahrnehmung wichtig ist
Moderne Kameras und Sensoren liefern Computern eine Flut visueller Daten, von selbstfahrenden Autos bis zu medizinischen Scans. Dennoch können leistungsfähige Sichtsysteme ins Straucheln geraten, wenn sich die Beleuchtung ändert, Objekte aus ungewöhnlichen Blickwinkeln erscheinen oder Bilder aus einer neuen Quelle stammen. Diese Studie stellt eine Methode vor, mit der Bilderkennungsmodelle ihre internen Abläufe für jedes einzelne Bild anpassen können, um verlässlichere Entscheidungen zu treffen, ohne dabei langsamer zu werden.
Bilder in vielen Skalen betrachten
Computervisionssysteme sehen ein Foto nicht so wie wir. Sie zerlegen es in viele Schichten von Merkmalen, von einfachen Kanten und Farben bis zu komplexen Formen wie Rädern oder Gesichtern. Traditionelle Modelle müssen im Voraus entscheiden, wie diese Schichten zu einer endgültigen Vorhersage kombiniert werden, mithilfe fester Regeln, die während des Trainings gelernt werden. Diese Regeln funktionieren gut, wenn neue Bilder dem Trainingsdatensatz ähneln, können jedoch versagen, wenn sich Details verschieben – etwa durch unterschiedliche Texturen, Kamerastile oder subtile Unterschiede zwischen ähnlichen Objekten.
Von festen Regeln zu flexiblen Entscheidungen
Die Autoren schlagen Meta Learned Dynamic Hierarchical Fusion (MDHF) vor, die feste Fusionsregeln durch einen gelernten Entscheidungsmechanismus ersetzt, der sich on-the-fly anpasst. Anstatt sich auf eine einzige Art der Informationsmischung aus allen Schichten festzulegen, lernt MDHF eine übergeordnete Strategie, die für jedes Eingabebild unterschiedliche Kombinationen wählen kann. Während des Trainings wird das System vielen künstlichen Stil- und Rauschverschiebungen ausgesetzt, wodurch es lernt, in unterschiedlichsten Bedingungen gute Fusionsstrategien auszuwählen. Bei der Prüfung kann es auf jedes neue Bild in einem einzigen Durchgang reagieren, ohne zusätzliches Feintuning oder langsame Anpassungsschritte.
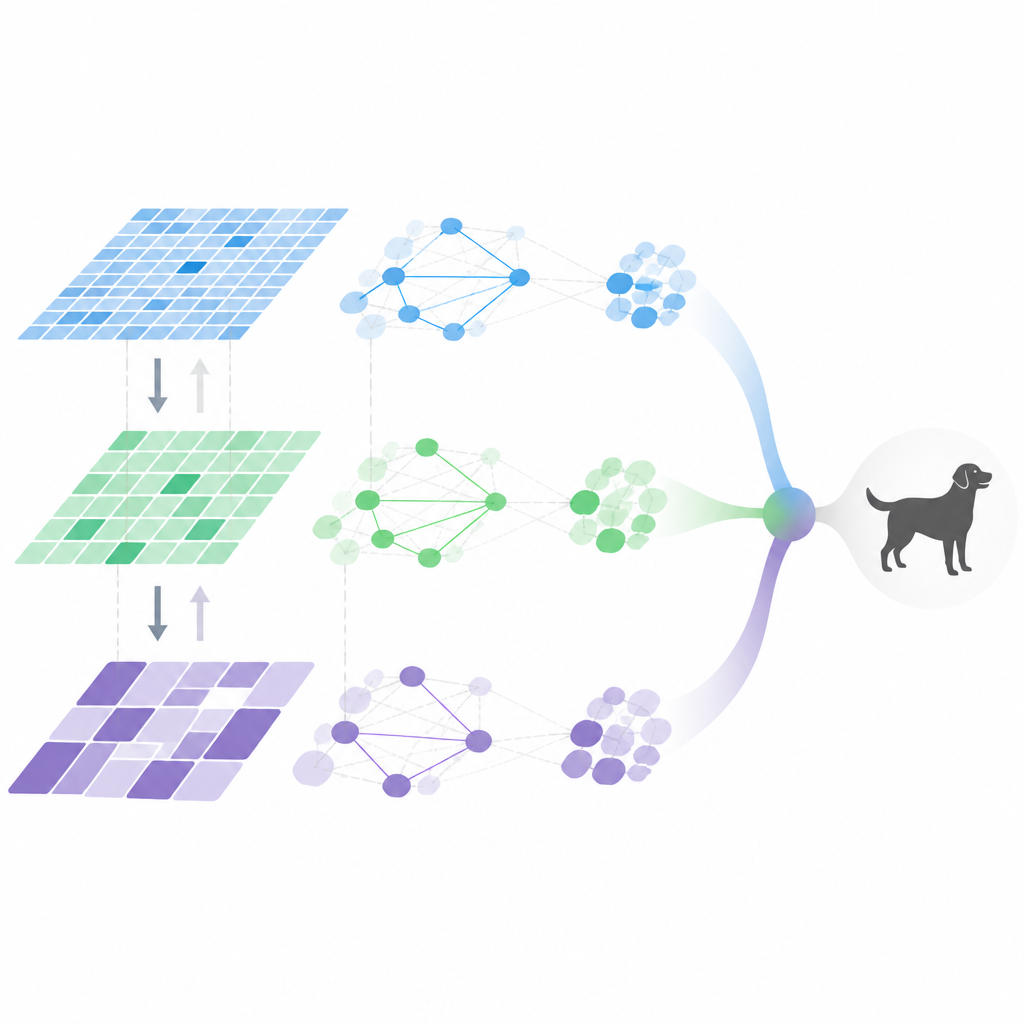
Im Inneren der adaptiven Wahrnehmungspipeline
MDHF kombiniert mehrere Ideen, um dieses flexible Verhalten zu erreichen. Zuerst erzeugt es multiskalige Merkmale mithilfe spezieller Faltungen, die anpassen können, wo sie im Bild abtasten, und so Details in unterschiedlichen Größen erfassen. Ein meta-gelerntes Aufmerksamkeitsmodul entscheidet dann, welche Kanäle und Skalen für jedes Bild hervorgehoben werden sollen, geleitet durch ein während vieler Trainingsaufgaben erlerntes Vorwissen. Anschließend fließt Information sowohl aufwärts als auch abwärts durch die Merkmalshierarchie, sodass feine Details und höhere Bedeutungsebenen sich gegenseitig verstärken können, statt zu verblassen. Schließlich werden Beziehungen zwischen Merkmalen durch einen sparsamen Graphen modelliert, der nur die wichtigsten Verbindungen beibehält, wodurch die Rechenmenge reduziert wird, ohne die Schlüsselinteraktionen zu verlieren.
Leistung in realen und belastenden Szenarien
Die Forschenden testeten MDHF auf fünf Bilddatensätzen, die einfache Objekte, großmaßstäbliche Erkennung, fein granulare Auto- und Haustierkategorien sowie eine herausfordernde, klassenunausgeglichene Sammlung abdecken. Über alle Datensätze hinweg erreichte MDHF Werte, die mit fünfzehn konkurrierenden Methoden mithalten konnten oder diese übertrafen, oft mit deutlich weniger Parametern als transformer-basierte Modelle und mit schnellerer Inferenz. Seine Stärken zeigen sich besonders bei fein granulierten Aufgaben, bei denen das System kleine, musterspezifische Hinweise erkennen muss, wie subtile Unterschiede an Autoteilen oder Tiergesichtern. MDHF zeigt außerdem hohe Widerstandsfähigkeit, wenn Bilder durch Rauschen, Unschärfe oder Kontraständerungen gestört werden, und bei gezielten adversarialen Manipulationen; es bewahrt einen großen Teil seiner Genauigkeit, wo andere Modelle stark einbrechen.
Wo Flexibilität ihre Grenzen hat
Obwohl MDHF sich in vielen Verschiebungen gut anpasst, untersuchen die Autoren auch, wo es Schwierigkeiten hat. Wenn Bilder zu stark von allem abweichen, was während des Meta-Trainings gesehen wurde – etwa extreme Blickwinkel oder Aufgaben, die hauptsächlich von Textur statt von Struktur abhängen – geht die Leistung bei allen Methoden, einschließlich MDHF, zurück. Sehr stromarme Geräte könnten zudem seine Anforderungen als belastend empfinden, auch wenn MDHF effizienter ist als viele fortgeschrittene Baselines. Diese Analysen helfen zu bestimmen, wann dynamische Fusion besonders nützlich ist und wo weitere Arbeit nötig ist.
Was das für den Alltag der KI bedeutet
Für Nicht-Fachleute lautet die Kernbotschaft: Diese Arbeit verwandelt einen starren Teil von Sichtsystemen in etwas, das eher einem gelernten Handbuch gleicht, das vor Ort Strategien auswählen kann. Anstatt visuelle Hinweise immer auf dieselbe Weise zu kombinieren, lernt MDHF, sie für jedes Bild unterschiedlich zu mischen und die Vorhersagegeschwindigkeit praktisch zu halten. Das führt zu besserer Genauigkeit, insbesondere bei schwierigen, fein differenzierten Unterschieden und unter verrauschten oder verschobenen Bedingungen, und weist in Richtung künftiger KI-Systeme, die ihren inneren Entscheidungsprozess an die sich verändernde Welt anpassen.
Zitation: Patra, P.K., Mahapatra, A. Meta-learned dynamic hierarchical fusion for robust multi-scale object classification. Sci Rep 16, 15613 (2026). https://doi.org/10.1038/s41598-026-47008-5
Schlüsselwörter: Computer Vision, Merkmalsfusion, Meta-Learning, Objektklassifikation, robuste Erkennung