Clear Sky Science · fr
Fusion hiérarchique dynamique méta-apprise pour une classification d'objets multi-échelle robuste
Pourquoi une vision plus intelligente compte
Les caméras et capteurs modernes alimentent les ordinateurs d'un flot de données visuelles, des véhicules autonomes aux scanners médicaux. Pourtant, même des systèmes de vision puissants peuvent trébucher lorsque l'éclairage change, que les objets apparaissent sous des angles inhabituels ou que les images proviennent d'une nouvelle source. Cette étude présente un moyen pour les modèles de reconnaissance d'images d'adapter leur fonctionnement interne à chaque image qu'ils voient, visant des décisions plus fiables sans les ralentir.
Observer les images à plusieurs échelles
Les systèmes de vision par ordinateur ne voient pas une photo comme nous. Ils la décomposent en nombreuses couches de caractéristiques, des bords et couleurs simples jusqu'aux formes complexes comme des roues ou des visages. Les modèles traditionnels doivent décider à l'avance comment combiner ces couches pour aboutir à une prédiction finale, en utilisant des règles fixes apprises durant l'entraînement. Ces règles fonctionnent bien lorsque les nouvelles images ressemblent aux données d'entraînement, mais elles peuvent échouer quand les détails changent, par exemple en raison de textures différentes, de styles d'appareils ou de variations subtiles entre objets similaires.
Des règles fixes à des décisions flexibles
Les auteurs proposent Meta Learned Dynamic Hierarchical Fusion, ou MDHF, qui remplace les règles de fusion fixes par un décideur appris capable de s'ajuster à la volée. Plutôt que de s'engager dans une seule manière de mélanger l'information provenant de toutes les couches, MDHF apprend une politique de niveau supérieur qui peut choisir différentes combinaisons pour chaque image d'entrée. Pendant l'entraînement, le système est exposé à de nombreux changements artificiels de style et de bruit, lui apprenant à sélectionner de bonnes stratégies de fusion dans des conditions variées. Au moment du test, il peut répondre à chaque nouvelle image en une seule passe, sans ajustement supplémentaire ni étape d'optimisation lente.
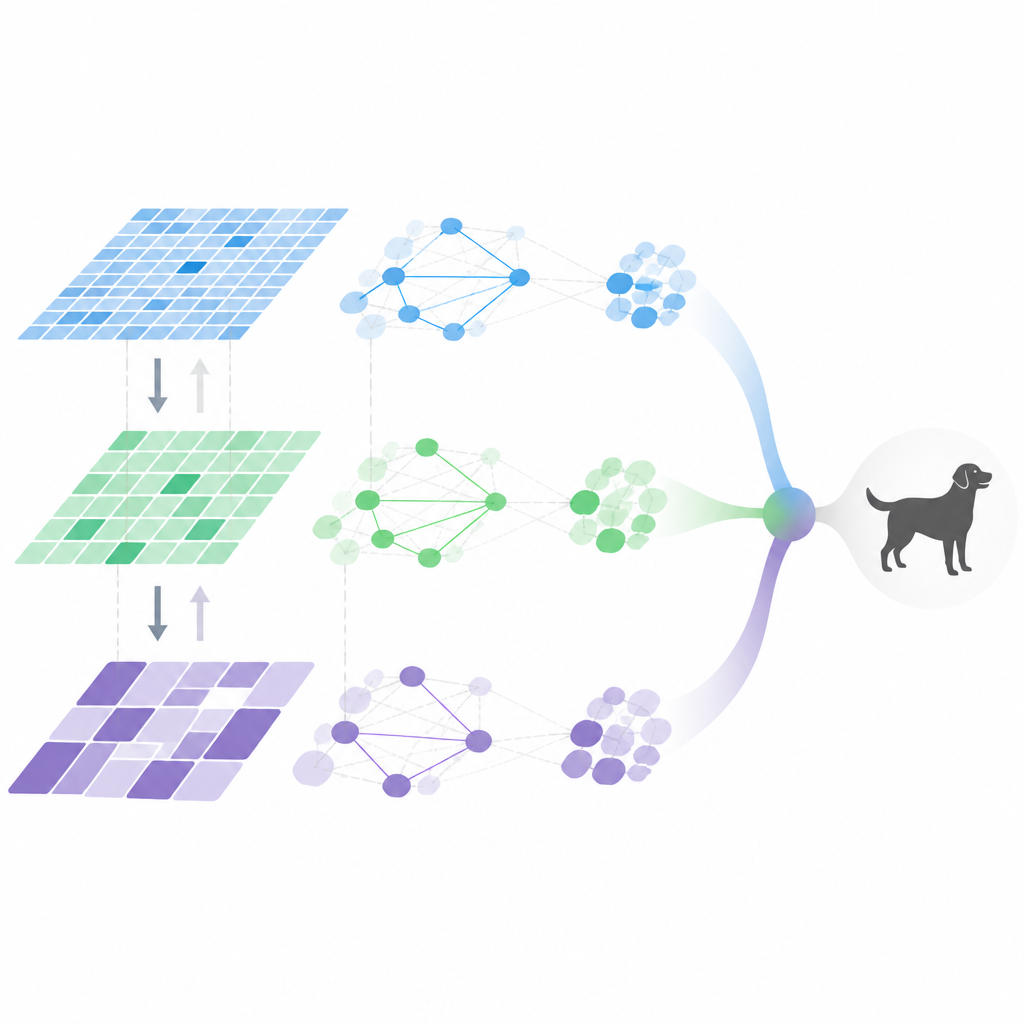
À l'intérieur du pipeline visuel adaptatif
MDHF combine plusieurs idées pour obtenir ce comportement flexible. D'abord, il construit des caractéristiques multi-échelle en utilisant des convolutions particulières qui peuvent ajuster où elles échantillonnent dans l'image, capturant des détails à différentes tailles. Un module d'attention méta-appris décide ensuite quels canaux et quelles échelles mettre en valeur pour chaque image, guidé par un a priori appris sur de nombreuses tâches d'entraînement. Ensuite, l'information circule à la fois vers le haut et vers le bas de la hiérarchie des caractéristiques, de sorte que les détails fins et le sens de haut niveau peuvent se renforcer mutuellement au lieu de s'estomper. Enfin, les relations entre caractéristiques sont modélisées par un graphe parcimonieux, ne conservant que les connexions les plus importantes, ce qui réduit la quantité de calcul tout en capturant les interactions clés.
Performances en conditions réelles et difficiles
Les chercheurs ont évalué MDHF sur cinq jeux de données d'images couvrant des objets simples, la reconnaissance à grande échelle, des catégories fines de voitures et d'animaux de compagnie, ainsi qu'un ensemble difficile avec déséquilibre de classes. Sur l'ensemble de ces tests, MDHF a égalé ou dépassé quinze méthodes concurrentes, souvent avec beaucoup moins de paramètres que les modèles basés sur des transformeurs et avec une inférence plus rapide. Ses points forts sont particulièrement visibles sur les tâches fines, où le système doit remarquer de petits indices propres à l'exemplaire, comme des différences subtiles dans des pièces de voiture ou des traits faciaux d'animaux. MDHF montre également une grande résilience lorsque les images sont corrompues par du bruit, du flou ou des changements de contraste, et lorsqu'elles sont attaquées par des modifications adversariales soigneusement conçues ; il conserve une large part de son exactitude là où d'autres modèles se dégradent fortement.
Quand la flexibilité a des limites
Bien que MDHF s'adapte bien à de nombreux changements, les auteurs explorent aussi ses points faibles. Lorsque les images diffèrent trop de tout ce qui a été vu pendant la méta-formation, comme des points de vue extrêmes ou des tâches qui dépendent principalement de la texture plutôt que de la structure, la performance chute pour toutes les méthodes, y compris MDHF. Les appareils très basse consommation peuvent aussi trouver ses exigences contraignantes, même s'il est plus efficace que de nombreuses références avancées. Ces analyses aident à définir quand la fusion dynamique est la plus utile et où des travaux supplémentaires sont nécessaires.
Ce que cela signifie pour l'IA du quotidien
Pour un non-spécialiste, le message principal est que ce travail transforme une partie rigide des systèmes de vision en quelque chose qui ressemble davantage à un manuel appris, capable de choisir des stratégies sur le moment. Plutôt que de toujours combiner les indices visuels de la même manière, MDHF apprend à les mélanger différemment pour chaque image tout en maintenant une vitesse de prédiction pratique. Cela conduit à une meilleure précision, notamment pour des différences fines et délicates et en présence de bruit ou de changements, et ouvre la voie à des systèmes d'IA futurs capables d'adapter leur processus décisionnel interne au monde changeant qu'ils observent.
Citation: Patra, P.K., Mahapatra, A. Meta-learned dynamic hierarchical fusion for robust multi-scale object classification. Sci Rep 16, 15613 (2026). https://doi.org/10.1038/s41598-026-47008-5
Mots-clés: vision par ordinateur, fusion de caractéristiques, méta-apprentissage, classification d'objets, reconnaissance robuste