Clear Sky Science · sv
Metainlärd dynamisk hierarkisk fusion för robust flerstegsobjektsklassificering
Varför smartare syn är viktigt
Moderna kameror och sensorer matar datorer med en strid ström visuella data, från självkörande bilar till medicinska avbildningar. Ändå kan även kraftfulla visionsystem stöta på problem när ljusförhållanden ändras, objekt visas i ovanliga vinklar eller bilder kommer från en ny källa. Denna studie introducerar ett sätt för bildigenkänningsmodeller att anpassa sina inre funktioner till varje enskild bild de ser, i syfte att ge mer tillförlitliga beslut utan att göra dem långsammare.
Att betrakta bilder i många skalor
Datorseendesystem ser inte ett foto på samma sätt som vi gör. De delar upp det i många lager av funktioner, från enkla kanter och färger till komplexa former som hjul eller ansikten. Traditionella modeller måste bestämma i förväg hur dessa lager ska kombineras till en slutlig gissning, med hjälp av fasta regler inlärda under träning. Dessa regler fungerar bra när nya bilder liknar träningsdata, men de kan misslyckas när detaljer skiftar, till exempel olika texturer, kameraprofiler eller subtila skillnader mellan liknande objekt.
Från fasta regler till flexibla beslut
Författarna föreslår Meta Learned Dynamic Hierarchical Fusion, eller MDHF, som ersätter fasta fusionsregler med en inlärd beslutsmakare som justerar sig i farten. I stället för att binda sig till ett enda sätt att blanda information från alla lager lär sig MDHF en överordnad policy som kan välja olika kombinationer för varje inmatningsbild. Under träning utsätts systemet för många artificiella stil- och brusstörningar, vilket lär det hur man väljer bra fusionsstrategier över varierande förhållanden. Vid testtid kan det reagera på varje ny bild i ett enda genomlopp, utan extra finjustering eller långsamma anpassningssteg.
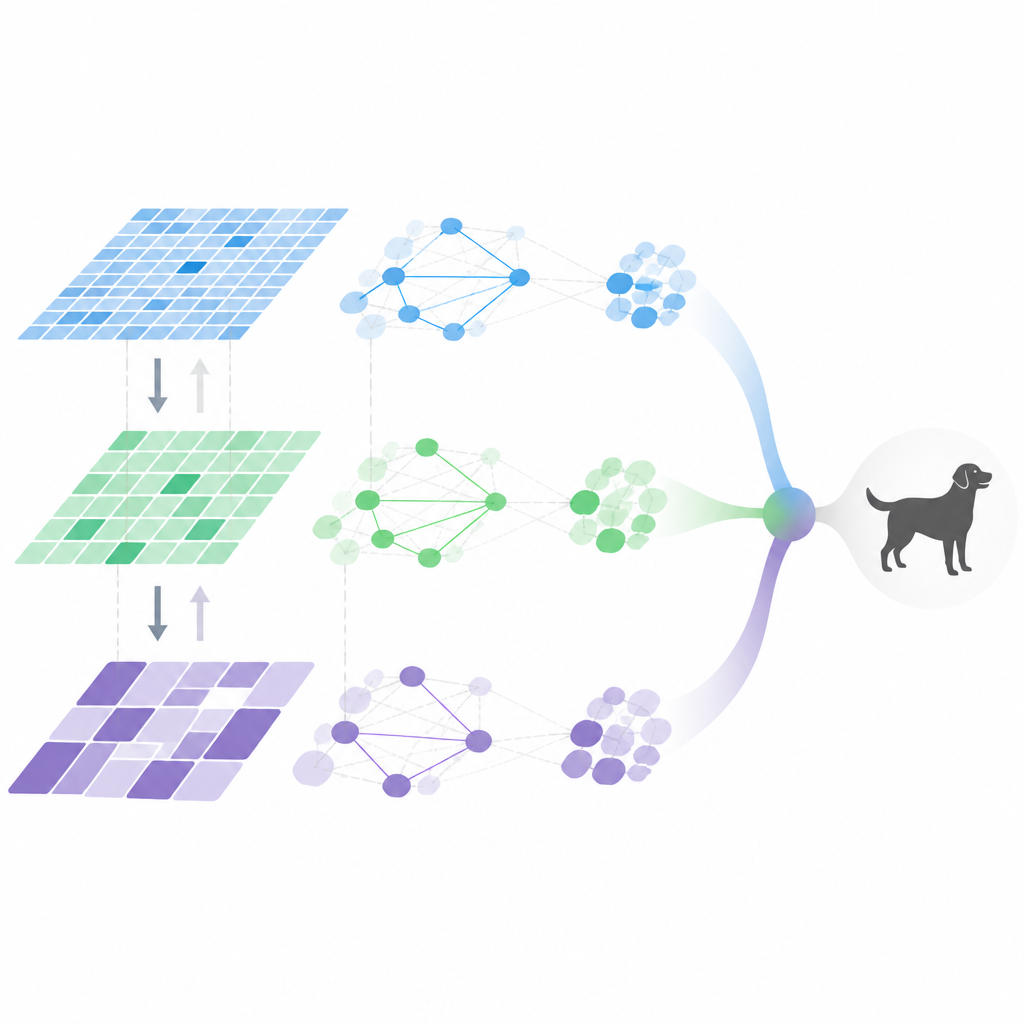
Inuti den adaptiva visionspipelinjen
MDHF kombinerar flera idéer för att uppnå detta flexibla beteende. Först bygger den flerskaliga funktioner med specialkonvolutioner som kan justera var de provtar i bilden, och fångar detaljer i olika storlekar. En metainlärd uppmärksamhetsmodul avgör sedan vilka kanaler och skalor som ska betonas för varje bild, styrd av en prior inlärd över många träningsuppgifter. Därefter flödar information både uppåt och nedåt i funktionshierarkin, så att fina detaljer och högre nivåns betydelse kan förstärka varandra istället för att försvinna. Slutligen modelleras relationer mellan funktioner med en gles graf, som behåller endast de viktigaste kopplingarna, vilket minskar beräkningsmängden samtidigt som centrala interaktioner fångas.
Prestanda i verkliga och stressade miljöer
Forskarna testade MDHF på fem bilddatamängder som täcker enkla objekt, storskalig igenkänning, finförgrenade bil- och husdjurskategorier samt en utmanande uppsättning med klassobalans. I samtliga matcherade eller överträffade MDHF femton konkurrerande metoder, ofta med betydligt färre parametrar än transformerbaserade modeller och snabbare inferens. Dess styrkor syns tydligast på finförgrenade uppgifter, där systemet måste uppfatta små, provspecifika ledtrådar som subtila skillnader i bildelar eller djuransikten. MDHF visar också stark motståndskraft när bilder korruptas av brus, oskärpa eller kontrastförändringar, och när de utsätts för noggrant utformade adversariella attacker; den bevarar en stor del av sin noggrannhet där andra modeller försämras kraftigt.
När flexibilitet har gränser
Även om MDHF anpassar sig väl till många skift utforskar författarna också var det har svårt. När bilder skiljer sig alltför mycket från allt som skådats under metaträning, till exempel extrema vyer eller uppgifter som främst beror på textur snarare än struktur, sjunker prestandan för alla metoder, inklusive MDHF. Mycket lågdrivna enheter kan också uppleva att dess krav är krävande, trots att den är mer effektiv än många avancerade baslinjer. Dessa analyser hjälper till att definiera när dynamisk fusion är mest användbar och var fortsatt arbete behövs.
Vad detta betyder för vardaglig AI
För en icke-specialist är huvudbudskapet att detta arbete förvandlar en rigid del av visionsystem till något mer likt en inlärd handbok som kan välja strategier på plats. I stället för att alltid kombinera visuella ledtrådar på samma sätt lär sig MDHF hur man mixar dem annorlunda för varje bild samtidigt som prediktionstakten hålls praktisk. Detta leder till bättre noggrannhet, särskilt för knepiga, finförgrenade skillnader och under brusiga eller skiftade förhållanden, och pekar mot framtida AI-system som kan anpassa sin inre beslutsprocess till den föränderliga värld de ser.
Citering: Patra, P.K., Mahapatra, A. Meta-learned dynamic hierarchical fusion for robust multi-scale object classification. Sci Rep 16, 15613 (2026). https://doi.org/10.1038/s41598-026-47008-5
Nyckelord: datorseende, funktionsfusion, meta-inlärning, objektsklassificering, robust igenkänning