Clear Sky Science · en
Meta-learned dynamic hierarchical fusion for robust multi-scale object classification
Why smarter vision matters
Modern cameras and sensors feed computers a flood of visual data, from self driving cars to medical scans. Yet even powerful vision systems can stumble when the lighting changes, objects appear at odd angles, or images come from a new source. This study introduces a way for image recognition models to adapt their inner workings to each picture they see, aiming for more reliable decisions without slowing them down.
Looking at pictures at many scales
Computer vision systems do not see a photo the way we do. They break it into many layers of features, from simple edges and colors to complex shapes like wheels or faces. Traditional models must decide in advance how to combine these layers into a final guess, using fixed rules learned during training. Those rules work well when new images look like the training data, but they can fail when details shift, such as different textures, camera styles, or subtle differences between similar objects.
From fixed rules to flexible decisions
The authors propose Meta Learned Dynamic Hierarchical Fusion, or MDHF, which replaces fixed fusion rules with a learned decision maker that adjusts on the fly. Instead of committing to one way of mixing information from all layers, MDHF learns a higher level policy that can choose different combinations for each input image. During training, the system is exposed to many artificial shifts in style and noise, teaching it how to pick good fusion strategies across varied conditions. At test time, it can respond to each new image in a single pass, without any extra fine tuning or slow adjustment steps.
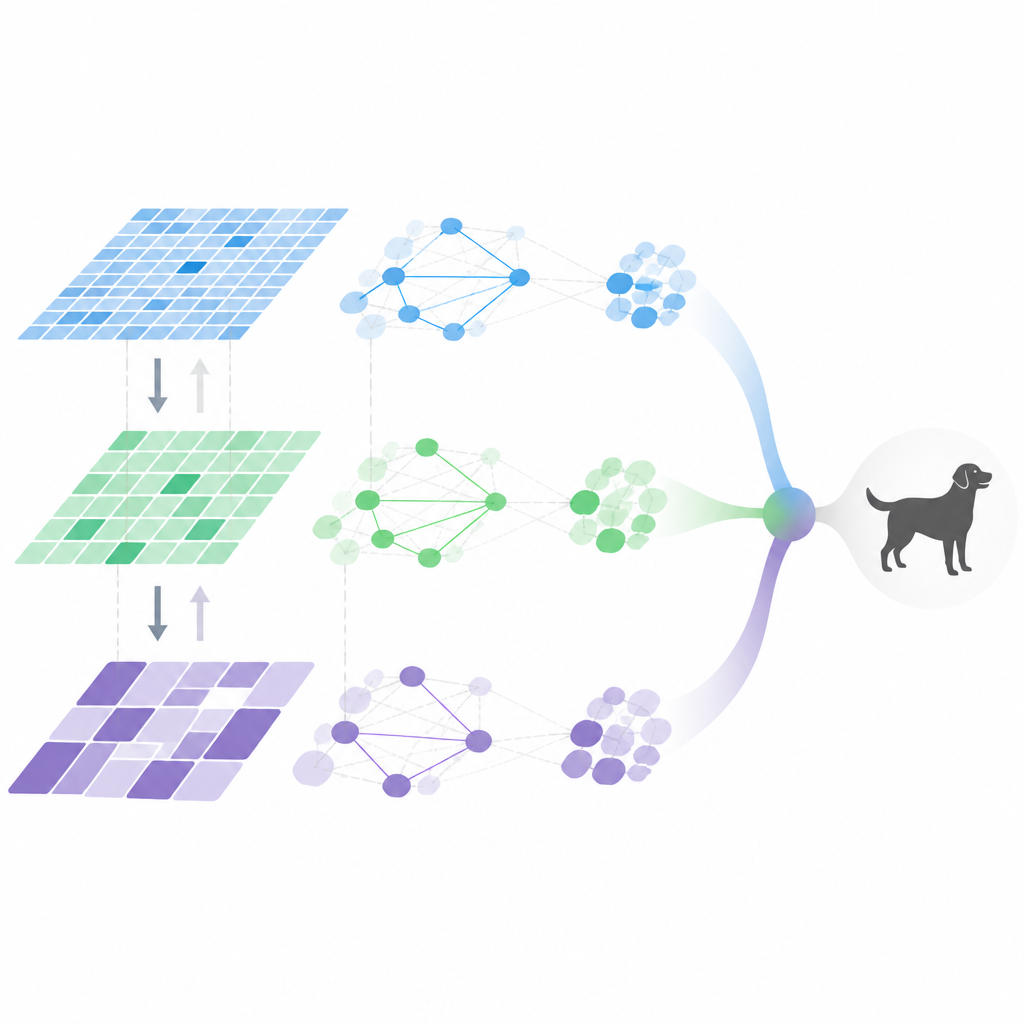
Inside the adaptive vision pipeline
MDHF combines several ideas to achieve this flexible behavior. First, it builds multi scale features using special convolutions that can adjust where they sample in the image, capturing details at different sizes. A meta learned attention module then decides which channels and scales to emphasize for each picture, guided by a prior learned across many training tasks. Next, information flows both up and down the feature hierarchy, so that fine details and high level meaning can reinforce each other instead of fading away. Finally, relationships among features are modeled with a sparse graph, keeping only the most important connections, which reduces the amount of computation while still capturing key interactions.
Performance in real and stressful settings
The researchers tested MDHF on five image datasets that cover simple objects, large scale recognition, fine grained car and pet categories, and a challenging set with class imbalance. Across all of them, MDHF matched or exceeded fifteen competing methods, often with far fewer parameters than transformer based models and faster inference. Its strengths are most visible on fine grained tasks, where the system must notice small, sample specific cues such as subtle differences in car parts or animal faces. MDHF also shows strong resilience when images are corrupted by noise, blur, or contrast changes, and when attacked by carefully designed adversarial changes; it preserves a large fraction of its accuracy where other models degrade sharply.
When flexibility has limits
Although MDHF adapts well to many shifts, the authors also explore where it struggles. When images differ too much from anything seen during meta training, such as extreme viewpoints or tasks that depend mainly on texture rather than structure, performance drops for all methods, including MDHF. Very low power devices may also find its requirements demanding, even though it is more efficient than many advanced baselines. These analyses help define when dynamic fusion is most helpful and where further work is needed.
What this means for everyday AI
For a non specialist, the main message is that this work turns a rigid part of vision systems into something more like a learned playbook that can pick strategies on the spot. Instead of always combining visual clues in the same way, MDHF learns how to mix them differently for each image while keeping prediction speed practical. This leads to better accuracy, especially for tricky, fine grained differences and under noisy or shifted conditions, and points toward future AI systems that can adapt their inner decision process to the changing world they see.
Citation: Patra, P.K., Mahapatra, A. Meta-learned dynamic hierarchical fusion for robust multi-scale object classification. Sci Rep 16, 15613 (2026). https://doi.org/10.1038/s41598-026-47008-5
Keywords: computer vision, feature fusion, meta learning, object classification, robust recognition