Clear Sky Science · pt
Fusão hierárquica dinâmica meta-aprendida para classificação robusta de objetos em múltiplas escalas
Por que uma visão mais inteligente importa
Câmeras e sensores modernos alimentam computadores com um dilúvio de dados visuais, de carros autônomos a exames médicos. Ainda assim, mesmo sistemas de visão poderosos podem falhar quando a iluminação muda, objetos aparecem em ângulos estranhos ou imagens vêm de uma fonte nova. Este estudo apresenta uma forma de fazer modelos de reconhecimento de imagem adaptarem seu funcionamento interno a cada imagem que veem, visando decisões mais confiáveis sem torná-los mais lentos.
Observando imagens em muitas escalas
Sistemas de visão computacional não veem uma foto do mesmo modo que nós. Eles a decompõem em muitas camadas de características, desde bordas e cores simples até formas complexas como rodas ou rostos. Modelos tradicionais precisam decidir antecipadamente como combinar essas camadas em uma hipótese final, usando regras fixas aprendidas durante o treinamento. Essas regras funcionam bem quando novas imagens se parecem com os dados de treino, mas podem falhar quando os detalhes mudam, como texturas diferentes, estilos de câmera ou diferenças sutis entre objetos semelhantes.
De regras fixas a decisões flexíveis
Os autores propõem Meta Learned Dynamic Hierarchical Fusion, ou MDHF, que substitui regras de fusão fixas por um tomador de decisão aprendido que se ajusta em tempo real. Em vez de se comprometer com uma única forma de misturar informações de todas as camadas, o MDHF aprende uma política de nível superior que pode escolher combinações distintas para cada imagem de entrada. Durante o treinamento, o sistema é exposto a muitas perturbações artificiais de estilo e ruído, ensinando-o a escolher boas estratégias de fusão em condições variadas. Na fase de teste, ele pode responder a cada nova imagem em uma única passada, sem afinações extras ou etapas lentas de ajuste.
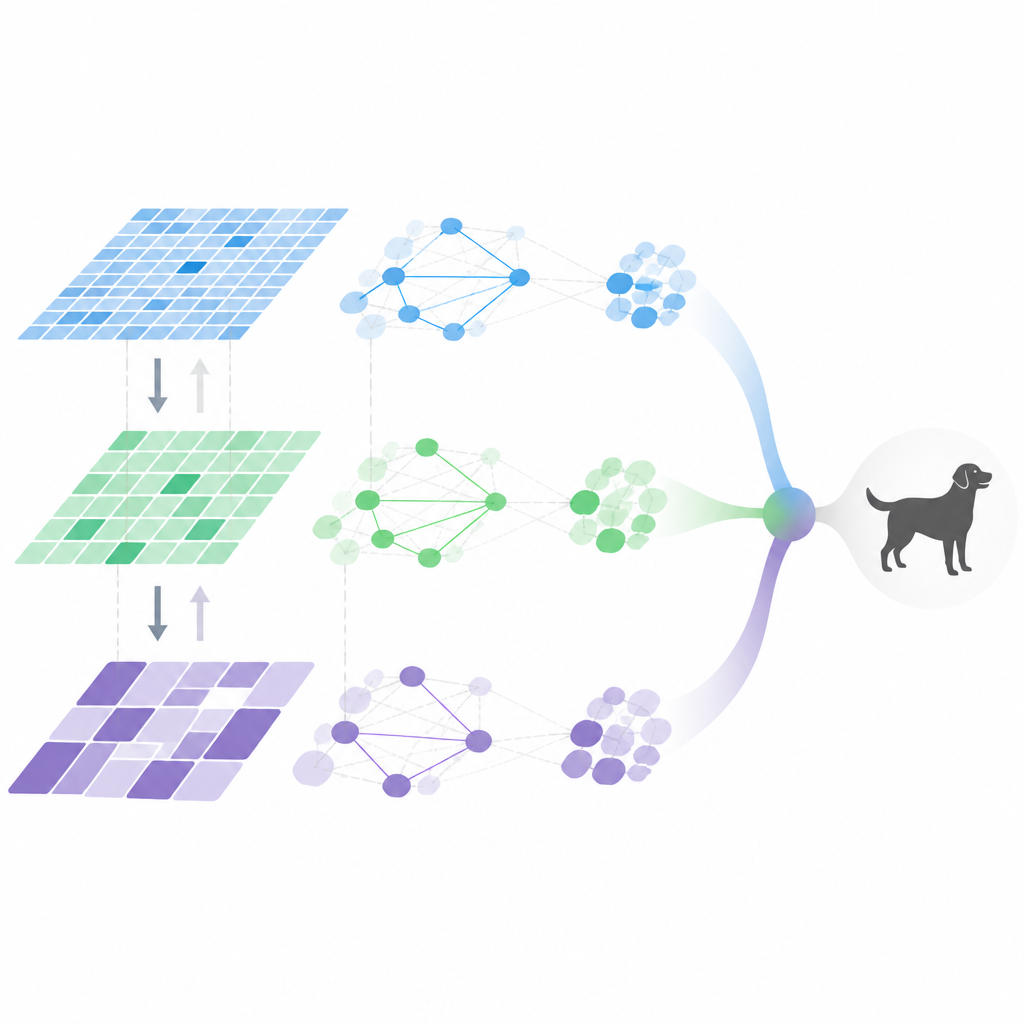
Dentro do pipeline de visão adaptativa
O MDHF combina várias ideias para alcançar esse comportamento flexível. Primeiro, constrói características em múltiplas escalas usando convoluções especiais que podem ajustar onde amostram na imagem, capturando detalhes em tamanhos variados. Um módulo de atenção meta-aprendido decide então quais canais e escalas enfatizar para cada imagem, guiado por um prior aprendido ao longo de muitas tarefas de treinamento. Em seguida, a informação flui tanto para cima quanto para baixo na hierarquia de características, de modo que detalhes finos e significados de alto nível possam reforçar-se mutuamente em vez de se diluírem. Finalmente, relações entre características são modeladas com um grafo esparso, mantendo apenas as conexões mais importantes, o que reduz a quantidade de cálculo enquanto ainda captura interações-chave.
Desempenho em cenários reais e estressantes
Os pesquisadores testaram o MDHF em cinco conjuntos de imagens que cobrem objetos simples, reconhecimento em grande escala, categorias finas de carros e animais de estimação, e um conjunto desafiador com desequilíbrio de classes. Em todos eles, o MDHF igualou ou superou quinze métodos concorrentes, muitas vezes com bem menos parâmetros que modelos baseados em transformers e inferência mais rápida. Seus pontos fortes são mais visíveis em tarefas de granularidade fina, onde o sistema precisa notar pistas pequenas e específicas da amostra, como diferenças sutis em peças de carro ou faces de animais. O MDHF também mostra forte resiliência quando imagens são corrompidas por ruído, desfoque ou mudanças de contraste, e quando atacadas por alterações adversariais cuidadosamente projetadas; ele preserva uma grande fração de sua acurácia onde outros modelos degradam drasticamente.
Quando a flexibilidade tem limites
Embora o MDHF se adapte bem a muitas mudanças, os autores também exploram onde ele enfrenta dificuldades. Quando as imagens diferem demais de tudo visto durante a meta-treinamento, como pontos de vista extremos ou tarefas que dependem principalmente de textura em vez de estrutura, o desempenho cai para todos os métodos, inclusive o MDHF. Dispositivos de muito baixa potência também podem achar suas exigências elevadas, mesmo sendo mais eficiente que várias linhas de base avançadas. Essas análises ajudam a definir quando a fusão dinâmica é mais útil e onde são necessários trabalhos adicionais.
O que isso significa para a IA do dia a dia
Para um público não especialista, a mensagem principal é que este trabalho transforma uma parte rígida dos sistemas de visão em algo mais parecido com um manual aprendido, capaz de escolher estratégias na hora. Em vez de sempre combinar pistas visuais da mesma maneira, o MDHF aprende a misturá-las de forma diferente para cada imagem, mantendo a velocidade de predição prática. Isso leva a melhor acurácia, especialmente para diferenças difíceis e de granularidade fina e sob condições ruidosas ou deslocadas, e aponta para futuros sistemas de IA capazes de adaptar seu processo decisório interno ao mundo em mudança que observam.
Citação: Patra, P.K., Mahapatra, A. Meta-learned dynamic hierarchical fusion for robust multi-scale object classification. Sci Rep 16, 15613 (2026). https://doi.org/10.1038/s41598-026-47008-5
Palavras-chave: visão computacional, fusão de características, meta aprendizagem, classificação de objetos, reconhecimento robusto