Clear Sky Science · it
Fusione gerarchica dinamica meta-apresa per una classificazione multi-scala robusta degli oggetti
Perché una visione più intelligente conta
Le moderne fotocamere e sensori forniscono ai computer un flusso enorme di dati visivi, dalle auto a guida autonoma alle scansioni mediche. Tuttavia anche i sistemi di visione più potenti possono inciampare quando cambia l'illuminazione, gli oggetti appaiono da angolazioni strane o le immagini provengono da una nuova sorgente. Questo studio introduce un modo per i modelli di riconoscimento delle immagini di adattare il loro funzionamento interno a ogni singola immagine che osservano, mirando a decisioni più affidabili senza rallentarle.
Osservare le immagini a molte scale
I sistemi di visione artificiale non vedono una foto come la vediamo noi. La scompongono in molti livelli di caratteristiche, da semplici contorni e colori a forme complesse come ruote o volti. I modelli tradizionali devono decidere in anticipo come combinare questi livelli in un'ipotesi finale, usando regole fisse apprese durante l'addestramento. Quelle regole funzionano bene quando le nuove immagini somigliano ai dati di addestramento, ma possono fallire quando i dettagli cambiano, ad esempio per texture diverse, stili di fotocamera o sottili differenze tra oggetti simili.
Dalle regole fisse a decisioni flessibili
Gli autori propongono Meta Learned Dynamic Hierarchical Fusion, o MDHF, che sostituisce le regole di fusione fisse con un decisore appreso che si adatta istantaneamente. Invece di impegnarsi in un unico modo di mescolare le informazioni provenienti da tutti gli strati, MDHF apprende una politica di livello superiore che può scegliere combinazioni diverse per ogni immagine in ingresso. Durante l'addestramento, il sistema è esposto a molte variazioni artificiali di stile e rumore, insegnandogli come scegliere buone strategie di fusione in condizioni variegate. In fase di test può rispondere a ogni nuova immagine in un singolo passaggio, senza alcuna messa a punto extra o fasi di adattamento lente.
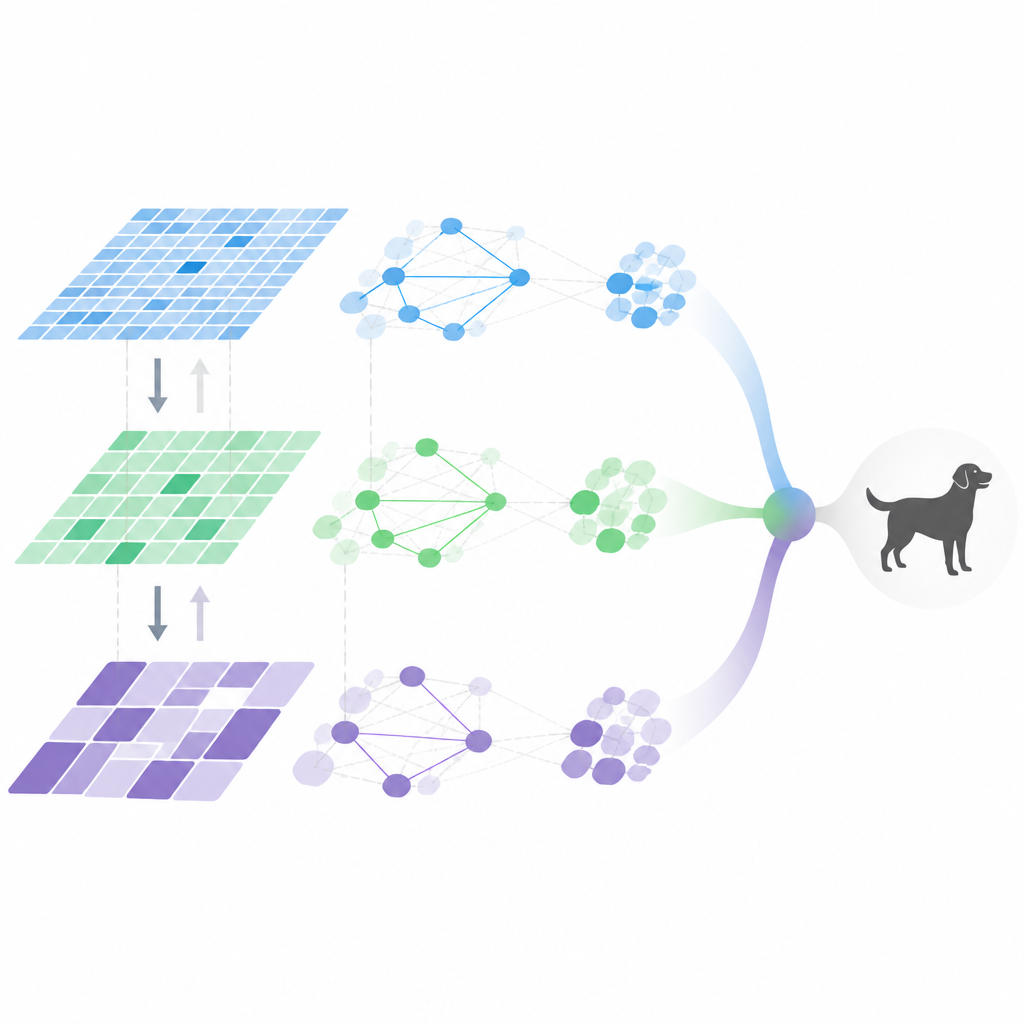
All'interno della pipeline di visione adattiva
MDHF combina diverse idee per ottenere questo comportamento flessibile. Innanzitutto costruisce caratteristiche multi-scala usando convoluzioni speciali che possono adattare i punti di campionamento nell'immagine, catturando dettagli a diverse dimensioni. Un modulo di attenzione meta-apreso decide poi quali canali e scale enfatizzare per ciascuna immagine, guidato da un priore appreso su molti compiti di addestramento. Successivamente, l'informazione fluisce sia verso l'alto sia verso il basso nella gerarchia delle caratteristiche, così che i dettagli fini e il significato di alto livello possano rafforzarsi a vicenda invece di affievolirsi. Infine, le relazioni tra caratteristiche sono modellate con un grafo sparso, mantenendo solo le connessioni più importanti, il che riduce la quantità di calcolo pur cogliendo le interazioni chiave.
Prestazioni in contesti reali e stressanti
I ricercatori hanno testato MDHF su cinque dataset di immagini che coprono oggetti semplici, riconoscimento su larga scala, categorie fine-grained di auto e animali domestici e un set sfidante con squilibrio di classi. In tutti questi casi, MDHF ha eguagliato o superato quindici metodi concorrenti, spesso con molti meno parametri rispetto ai modelli basati su transformer e con inferenza più veloce. I suoi punti di forza sono più evidenti nei compiti fine-grained, dove il sistema deve notare piccoli indizi specifici del campione come sottili differenze in parti di auto o nei volti degli animali. MDHF mostra anche forte resilienza quando le immagini sono corrotte da rumore, sfocatura o variazioni di contrasto, e quando sono sottoposte ad attacchi avversari progettati; conserva una larga frazione della sua accuratezza laddove altri modelli degradano rapidamente.
Quando la flessibilità incontra dei limiti
Anche se MDHF si adatta bene a molte variazioni, gli autori esplorano anche i casi in cui fatica. Quando le immagini differiscono troppo da quanto visto durante il meta-addestramento, come punti di vista estremi o compiti che dipendono principalmente dalla texture anziché dalla struttura, le prestazioni calano per tutti i metodi, incluso MDHF. Anche dispositivi a bassissima potenza possono trovare le sue esigenze impegnative, sebbene sia più efficiente di molte baseline avanzate. Queste analisi aiutano a definire quando la fusione dinamica è più utile e dove sono necessari ulteriori sviluppi.
Cosa significa questo per l'IA di tutti i giorni
Per un non specialista, il messaggio principale è che questo lavoro trasforma una parte rigida dei sistemi di visione in qualcosa di più simile a un playbook appreso che può scegliere strategie sul momento. Invece di combinare sempre gli indizi visivi nello stesso modo, MDHF impara come mescolarli diversamente per ogni immagine mantenendo la velocità di predizione pratica. Questo conduce a una migliore accuratezza, specialmente per differenze fini e in condizioni rumorose o variate, e indica la direzione per futuri sistemi di IA che possono adattare il loro processo decisionale interno al mondo in continuo cambiamento che osservano.
Citazione: Patra, P.K., Mahapatra, A. Meta-learned dynamic hierarchical fusion for robust multi-scale object classification. Sci Rep 16, 15613 (2026). https://doi.org/10.1038/s41598-026-47008-5
Parole chiave: visione artificiale, fusione di caratteristiche, meta-apprendimento, classificazione degli oggetti, riconoscimento robusto