Clear Sky Science · pl
Meta-nauczona dynamiczna hierarchiczna fuzja dla odpornej klasyfikacji obiektów w wielu skalach
Dlaczego mądrzejszy wzrok ma znaczenie
Nowoczesne kamery i sensory dostarczają komputerom potok wizualnych danych — od samochodów autonomicznych po skany medyczne. Nawet zaawansowane systemy wzrokowe potrafią jednak zawieźć, gdy zmienia się oświetlenie, obiekty pojawiają się pod nietypowymi kątami lub obrazy pochodzą z nowego źródła. W tej pracy przedstawiono sposób, w jaki modele rozpoznawania obrazów mogą dostosowywać swoje wewnętrzne działanie do każdego widzianego obrazu, dążąc do bardziej niezawodnych decyzji bez spowalniania działania.
Patrzenie na obrazy w wielu skalach
Systemy wizji komputerowej nie widzą zdjęcia tak jak my. Dzielą je na wiele warstw cech, od prostych krawędzi i kolorów po złożone kształty, takie jak koła czy twarze. Tradycyjne modele muszą wcześniej zdecydować, jak połączyć te warstwy w końcowe przypuszczenie, stosując stałe reguły wyuczone w trakcie treningu. Takie reguły działają dobrze, gdy nowe obrazy przypominają dane treningowe, ale zawodzą, gdy szczegóły się zmieniają — na przykład w przypadku różnych tekstur, stylów kamer czy subtelnych różnic między podobnymi obiektami.
Od stałych reguł do elastycznych decyzji
Autorzy proponują Meta Learned Dynamic Hierarchical Fusion, w skrócie MDHF, które zastępuje stałe reguły łączenia decydentem uczonym, działającym w locie. Zamiast przyjmować jeden sposób mieszania informacji ze wszystkich warstw, MDHF uczy wyższego poziomu polityki, który może wybierać różne kombinacje dla każdego obrazu wejściowego. W czasie treningu system jest eksponowany na wiele sztucznych przesunięć stylu i szumu, ucząc się wybierać dobre strategie fuzji w zróżnicowanych warunkach. W fazie testowej potrafi reagować na każdy nowy obraz w pojedynczym przebiegu, bez dodatkowego strojenia czy powolnych kroków dostosowawczych.
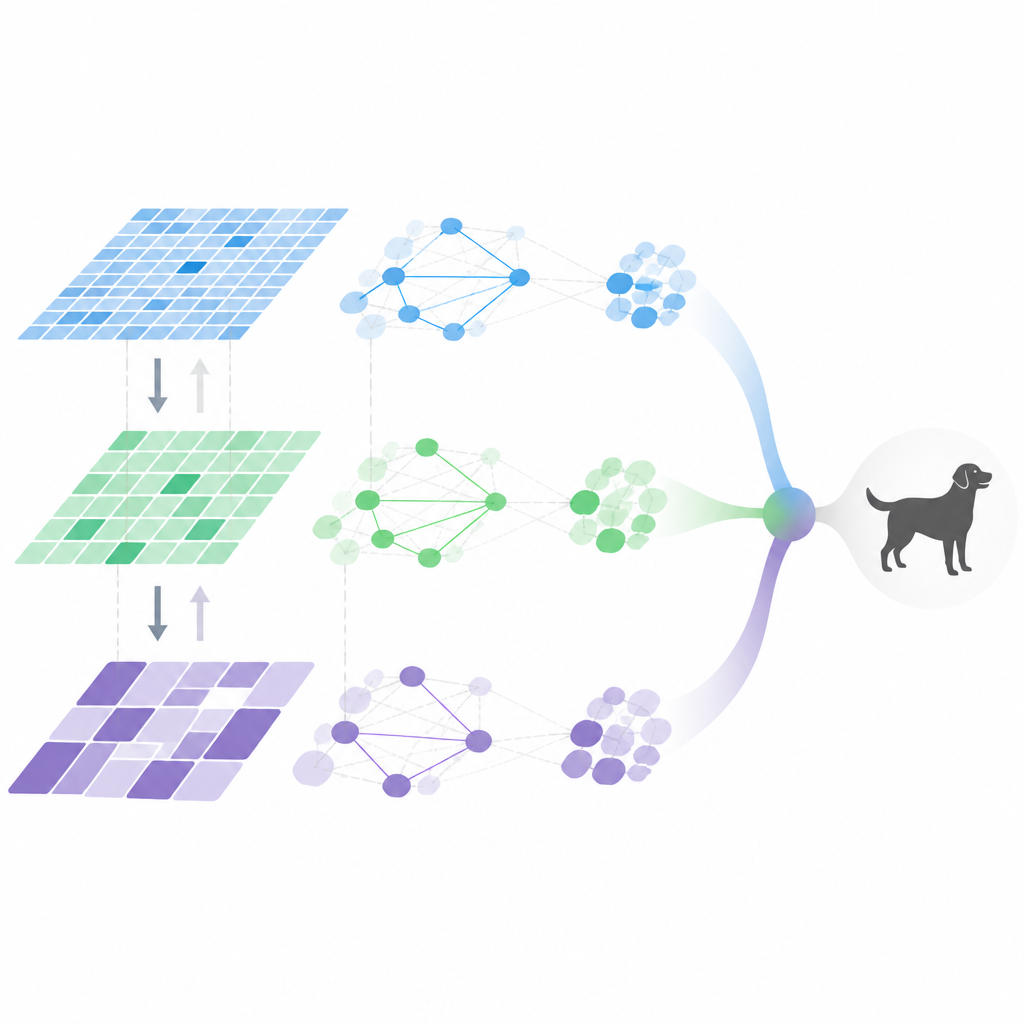
Wewnątrz adaptacyjnego potoku wzrokowego
MDHF łączy kilka pomysłów, aby osiągnąć tę elastyczność. Po pierwsze, buduje cechy wieloskalowe, wykorzystując specjalne konwolucje, które mogą dostosowywać miejsca próbkowania w obrazie, uchwytując detale o różnych rozmiarach. Następnie meta-nauczony moduł uwagi decyduje, które kanały i skale podkreślić dla każdego obrazu, kierowany uprzednim doświadczeniem zdobytym w wielu zadaniach treningowych. Dalej informacja przepływa w górę i w dół hierarchii cech, tak by drobne szczegóły i wysokopoziomowe znaczenie wzajemnie się wzmacniały, zamiast zanikać. Wreszcie relacje między cechami modelowane są za pomocą rzadkiego grafu, zachowującego jedynie najważniejsze połączenia, co zmniejsza ilość obliczeń przy jednoczesnym uchwyceniu kluczowych interakcji.
Wyniki w rzeczywistych i stresujących warunkach
Naukowcy przetestowali MDHF na pięciu zbiorach obrazów obejmujących proste obiekty, rozpoznawanie w dużej skali, szczegółowe kategorie samochodów i zwierząt domowych oraz trudny zbiór z niezbalansowanymi klasami. We wszystkich przypadkach MDHF dorównywał lub przewyższał piętnaście konkurencyjnych metod, często mając znacznie mniej parametrów niż modele oparte na transformerach i zapewniając szybsze wnioskowanie. Jego zalety są najbardziej widoczne w zadaniach drobnoziarnistych, gdzie system musi wychwycić małe, specyficzne wskazówki, takie jak subtelne różnice w częściach samochodu czy rysach twarzy zwierząt. MDHF wykazuje też dużą odporność na uszkodzenia obrazów przez szum, rozmycie czy zmiany kontrastu oraz na celowo zaprojektowane ataki adwersarialne; zachowuje dużą część swojej dokładności tam, gdzie inne modele gwałtownie tracą wydajność.
Gdy elastyczność ma granice
Chociaż MDHF dobrze adaptuje się do wielu przesunięć, autorzy badają też obszary, w których ma trudności. Gdy obrazy różnią się zbyt bardzo od tego, co widziano podczas meta-treningu — na przykład ekstremalne punkty widzenia lub zadania zależne głównie od tekstury zamiast struktury — wydajność spada dla wszystkich metod, w tym MDHF. Bardzo niskoprądowe urządzenia mogą również uznać jego wymagania za uciążliwe, mimo że jest bardziej efektywny niż wiele zaawansowanych baz. Te analizy pomagają określić, kiedy dynamiczna fuzja jest najbardziej użyteczna i gdzie potrzebne są dalsze prace.
Co to oznacza dla codziennej sztucznej inteligencji
Dla osoby niespecjalistycznej główne przesłanie jest takie, że praca ta zamienia sztywny element systemów wzrokowych w coś bardziej przypominającego wyuczony zestaw zasad, potrafiący dobierać strategie na bieżąco. Zamiast zawsze łączyć wskazówki wzrokowe w ten sam sposób, MDHF uczy się mieszać je inaczej dla każdego obrazu, zachowując jednocześnie praktyczną prędkość predykcji. Prowadzi to do lepszej dokładności, zwłaszcza przy trudnych, drobnoziarnistych różnicach oraz w warunkach zaszumionych czy przesuniętych, i wskazuje kierunek dla przyszłych systemów AI, które potrafią dostosować swój wewnętrzny proces decyzyjny do zmieniającego się świata, który obserwują.
Cytowanie: Patra, P.K., Mahapatra, A. Meta-learned dynamic hierarchical fusion for robust multi-scale object classification. Sci Rep 16, 15613 (2026). https://doi.org/10.1038/s41598-026-47008-5
Słowa kluczowe: wizja komputerowa, fuzja cech, meta-nauka, klasyfikacja obiektów, odporne rozpoznawanie