Clear Sky Science · es
Fusión jerárquica dinámica meta-aprendida para clasificación de objetos multi-escala robusta
Por qué importa una visión más inteligente
Las cámaras y los sensores modernos proporcionan a los ordenadores un aluvión de datos visuales, desde vehículos autónomos hasta exploraciones médicas. Aun así, incluso los sistemas de visión potentes pueden fallar cuando cambia la iluminación, los objetos aparecen en ángulos extraños o las imágenes provienen de una fuente nueva. Este estudio introduce una forma para que los modelos de reconocimiento de imágenes adapten su funcionamiento interno a cada fotografía que procesan, con el objetivo de tomar decisiones más fiables sin ralentizarlas.
Mirar las imágenes a muchas escalas
Los sistemas de visión por computador no ven una foto como lo hacemos nosotros. La descomponen en muchas capas de características, desde bordes y colores simples hasta formas complejas como ruedas o rostros. Los modelos tradicionales deben decidir de antemano cómo combinar estas capas en una predicción final, usando reglas fijas aprendidas durante el entrenamiento. Esas reglas funcionan bien cuando las imágenes nuevas se parecen a los datos de entrenamiento, pero pueden fallar cuando cambian los detalles, como diferentes texturas, estilos de cámara o diferencias sutiles entre objetos similares.
De reglas fijas a decisiones flexibles
Los autores proponen Meta Learned Dynamic Hierarchical Fusion, o MDHF, que reemplaza las reglas de fusión fijas por un tomador de decisiones aprendido que se ajusta sobre la marcha. En lugar de comprometerse con una única forma de mezclar la información de todas las capas, MDHF aprende una política de nivel superior que puede elegir distintas combinaciones para cada imagen de entrada. Durante el entrenamiento, el sistema se expone a muchos cambios artificiales de estilo y ruido, enseñándole a elegir buenas estrategias de fusión en condiciones variadas. En la prueba, puede responder a cada nueva imagen en una sola pasada, sin ajustes lentos ni afinamientos adicionales.
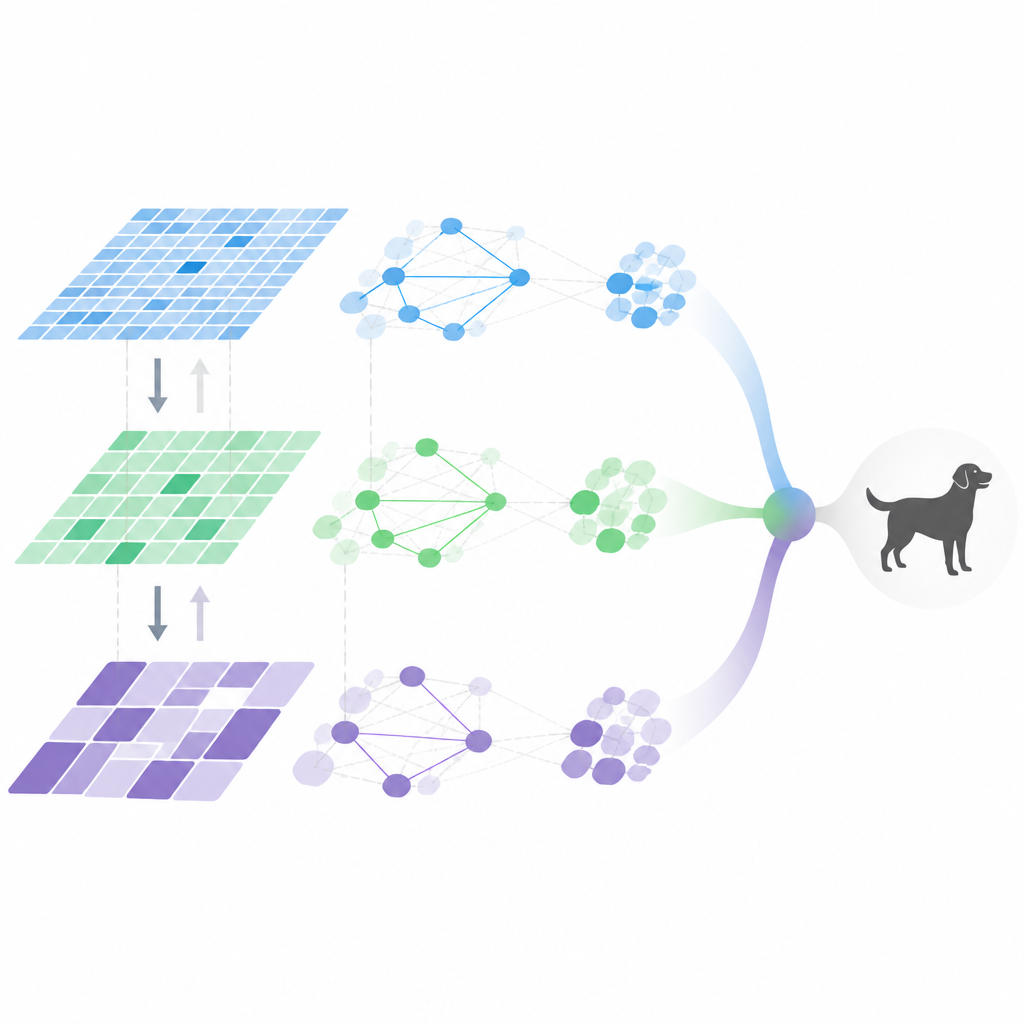
Dentro de la canalización de visión adaptativa
MDHF combina varias ideas para lograr este comportamiento flexible. Primero, construye características multi-escala usando convoluciones especiales que pueden ajustar dónde muestrean en la imagen, capturando detalles a diferentes tamaños. Un módulo de atención meta-aprendido decide entonces qué canales y escalas enfatizar para cada imagen, guiado por un conocimiento previo aprendido a partir de muchas tareas de entrenamiento. A continuación, la información fluye tanto hacia arriba como hacia abajo en la jerarquía de características, de modo que los detalles finos y el significado de alto nivel pueden reforzarse entre sí en lugar de desvanecerse. Finalmente, las relaciones entre características se modelan con un grafo disperso, conservando solo las conexiones más importantes, lo que reduce la cantidad de cómputo mientras captura las interacciones clave.
Rendimiento en escenarios reales y exigentes
Los investigadores probaron MDHF en cinco conjuntos de datos de imágenes que abarcan objetos simples, reconocimiento a gran escala, categorías finas de coches y mascotas, y un conjunto desafiante con desequilibrio de clases. En todos ellos, MDHF igualó o superó a quince métodos competidores, a menudo con muchos menos parámetros que los modelos basados en transformadores y con inferencia más rápida. Sus fortalezas son más visibles en tareas de detalle fino, donde el sistema debe notar pistas pequeñas y específicas de cada muestra, como diferencias sutiles en piezas de coches o en rostros de animales. MDHF también muestra una fuerte resiliencia cuando las imágenes se corrompen por ruido, desenfoque o cambios de contraste, y cuando son atacadas mediante alteraciones adversarias cuidadosamente diseñadas; conserva una gran parte de su precisión en escenarios donde otros modelos se degradan bruscamente.
Cuando la flexibilidad tiene límites
Aunque MDHF se adapta bien a muchos cambios, los autores también exploran dónde tiene dificultades. Cuando las imágenes difieren demasiado de todo lo visto durante el metaentrenamiento, como puntos de vista extremos o tareas que dependen principalmente de la textura en lugar de la estructura, el rendimiento cae para todos los métodos, incluido MDHF. Los dispositivos de muy baja potencia también pueden encontrar exigentes sus requerimientos, aunque es más eficiente que muchas líneas base avanzadas. Estos análisis ayudan a definir cuándo la fusión dinámica es más útil y dónde se necesita trabajo adicional.
Qué significa esto para la IA cotidiana
Para un público no especializado, el mensaje principal es que este trabajo convierte una parte rígida de los sistemas de visión en algo más parecido a un manual aprendido que puede elegir estrategias al instante. En lugar de combinar siempre las pistas visuales de la misma manera, MDHF aprende a mezclarlas de forma distinta para cada imagen manteniendo una velocidad de predicción práctica. Esto conduce a una mejor precisión, especialmente en diferencias finas y complejas y en condiciones ruidosas o desplazadas, y apunta hacia futuros sistemas de IA que puedan adaptar su proceso interno de decisión al mundo cambiante que observan.
Cita: Patra, P.K., Mahapatra, A. Meta-learned dynamic hierarchical fusion for robust multi-scale object classification. Sci Rep 16, 15613 (2026). https://doi.org/10.1038/s41598-026-47008-5
Palabras clave: visión por computador, fusión de características, metaaprendizaje, clasificación de objetos, reconocimiento robusto