Clear Sky Science · zh
一种用于属性缺失的异构图的扰动—恢复生成自编码器
为什么网络中混乱的数据很重要
从电影推荐到学术搜索引擎再到药物发现,许多现代工具都依赖将不同事物相连的网络:人、论文、商家、影片或蛋白质。这些被称为异构图的网络不仅记录谁与谁相连,还为每个节点附加描述性信息,例如电影的剧情简介或餐馆的标签。实际上,这些信息大多不完整或含噪,这会悄然削弱基于这些网络所做预测的质量。本文提出了一种在此类不完美图上训练模型的新方法,使其能更好地应对数据中的空缺与错误。
多类事物构成的网络
不同于每个节点都是人且每条边都是友谊的简单社交网络,异构图混合了多种节点和边类型。学术图可能连接作者、论文和会议;点评网站的图可能关联用户、商家和评论。每个节点带有属性:论文的关键词、用户的偏好或电影的摘要。当这些属性不完整或被损坏时,标准图方法难以学到节点的可靠内部表示。进而会损害后续任务,如对论文领域的分类、相似商家的聚类或电影推荐。早期方法通常尝试一次性填补缺失属性,使用固定规则,然后在这个单一的“清理后”数据版本上训练模型。
从遮掩到受控扰动
较新的方法将缺失信息视为一个训练挑战:它们故意隐藏节点属性的部分内容(称为掩码),并教模型重建被隐藏的部分。这种“掩码与恢复”策略帮助模型理解上下文,但大多数现有设计采用固定或简单的随机掩码方案。它们只让模型接触到有限范围的缺失模式,无法真实地模拟现实世界数据如何退化。更糟的是,如果过早地隐藏太多信息,训练可能变得不稳定,而掩码太少则无法建立稳健性。作者认为,缺失属性更像是与网络多类型结构相互作用的随机、依赖上下文的扰动,需要以更灵活且可控的方式建模。
将缺失数据视作扰动—恢复过程
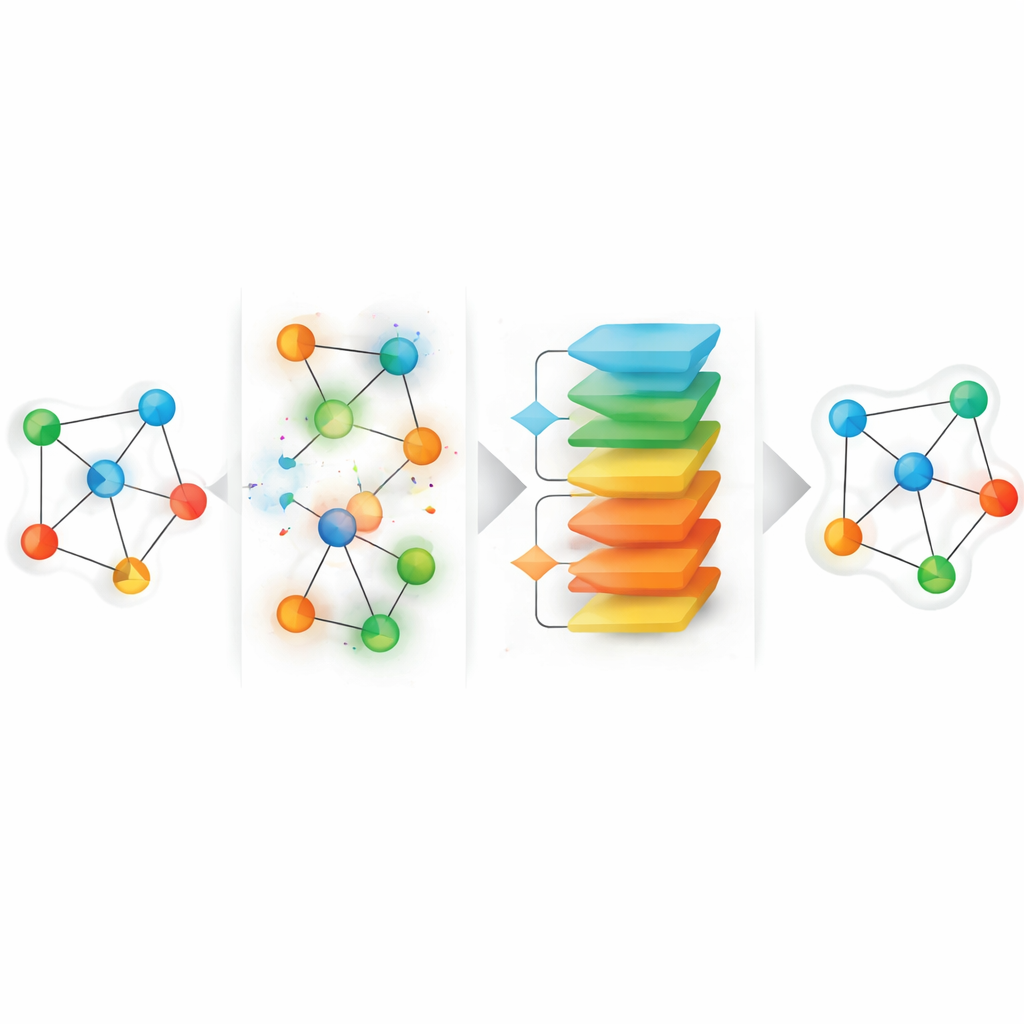
所提出的框架称为 HGGAE,从一个新的视角出发:将缺失属性看作是一个有意扰动特征和连接的扰动过程的结果,然后学习如何撤销这些扰动。HGGAE 首先通过有选择地替换或修改节点属性并沿着不同类型的路径略微改变连接模式来构建图的“噪声视图”。一个可训练模块会为每个节点分配重要性分数,并据此决定哪些节点该被扰动以及扰动程度。在训练早期,系统主要扰动不太重要的节点,提出较容易的恢复任务。随着训练推进,它逐渐增加难度,开始扰动更有信息量的节点。这样的课程式安排允许模型在面对更困难的重建问题之前先稳定下来,同时更好地反映真实缺失数据的不确定性与不均匀性。
让模型保持可靠且高效
仅仅加入噪声还不够;还必须阻止模型偏离真实模式。为此,HGGAE 包含一个对抗组件:一个独立网络学习区分来源于干净输入的表示与扰动后生成的表示。主模型的训练不仅要重建属性和结构模式,还要骗过这个判别器,将其内部表示即便在输入严重扰动的情况下也拉回到“真实”数据流形上。为在大图上保持计算可控,该方法仅在每次训练步骤实际扰动的节点上计算重建误差,而不是对每个节点都计算。这个稀疏目标设计将学习重点放在最有信息的位置,同时总体计算成本仍由一次标准的全图传递主导。
在真实基准上证明效果
为评估 HGGAE,作者使用了四个标准的异构图数据集,代表论文、作者、电影和商家,且都有人为设置的不完整属性。他们在不同标注量下评估节点分类(预测如研究领域或商家类别的标签)和聚类(将相似节点分组)任务。在这些任务中,HGGAE 一贯达到或超过强基线方法的水平。在一个稀疏且噪声较多的电影数据集上,增益尤为显著,使某项关键准确率指标提高了约八个百分点。额外实验表明,基于课程的扰动调度与扰动—恢复机制都至关重要:去掉它们或用固定掩码替代会导致明显的性能下降。
对日常图应用的意义
对读者来说,主要结论是:与其在复杂网络中隐藏或粗糙地修补缺失信息,不如主动模拟属性如何出错并以受控方式训练模型去修复它们。通过将缺失数据视为分阶段的扰动过程,并用结构线索与对抗性检验来引导恢复,HGGAE 学到的节点表示即便在现实世界图数据混乱的情况下也能保持可靠。这转化为更好的预测与更有意义的分组,适用于构建在社交、学术或商业网络之上的系统,这些系统中不完整数据往往是常态而非例外。
引用: Wang, Q., Shao, X. & Huang, X. A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing. Sci Rep 16, 13538 (2026). https://doi.org/10.1038/s41598-026-44190-4
关键词: 异构图, 属性缺失, 图自编码器, 表示学习, 自监督学习