Clear Sky Science · pl
Generatywny autoenkoder z perturbacją i odzyskiwaniem dla heterogenicznych grafów z brakującymi atrybutami
Dlaczego nieuporządkowane dane w sieciach mają znaczenie
Od rekomendacji filmów po wyszukiwarki naukowe i odkrywanie leków — wiele współczesnych narzędzi opiera się na sieciach łączących różne typy obiektów: ludzi, artykuły, firmy, filmy czy białka. Te sieci, nazywane heterogenicznymi grafami, nie tylko zapisują, kto jest połączony z kim, lecz także dołączają do każdego węzła informacje opisowe, takie jak opis fabuły filmu czy tagi restauracji. W praktyce dużą część tych danych brakuje lub są one zaszumione, co po cichu obniża jakość przewidywań opartych na takich grafach. Artykuł przedstawia nowy sposób trenowania modeli na takich niedoskonałych grafach, aby lepiej radziły sobie z brakami i błędami w danych.
Sieci łączące wiele rodzajów obiektów
W przeciwieństwie do prostych sieci społecznych, gdzie każdy węzeł to osoba, a każda krawędź to przyjaźń, heterogeniczne grafy łączą kilka typów węzłów i relacji. Graf naukowy może łączyć autorów, artykuły i konferencje; serwis recenzji może wiązać użytkowników, firmy i opinie. Do każdego węzła dołączone są atrybuty: słowa kluczowe artykułu, preferencje użytkownika czy streszczenie filmu. Gdy te atrybuty są niekompletne lub uszkodzone, standardowe metody grafowe mają trudności z nauką wiarygodnych wewnętrznych reprezentacji węzłów. To z kolei szkodzi zadaniom następczym, takim jak klasyfikacja dziedziny artykułu, grupowanie podobnych firm czy rekomendacje filmów. Wcześniejsze podejścia zwykle próbowały jednorazowo uzupełnić brakujące atrybuty za pomocą ustalonych reguł, a następnie trenowały modele na tej jedynej, „oczyszczonej” wersji danych.
Od maskowania do kontrolowanych zakłóceń
Nowsze metody traktują brakujące informacje jako wyzwanie treningowe: celowo ukrywają fragmenty atrybutów węzłów (proces zwany maskowaniem) i uczą model je rekonstruować. Strategia „maskuj-i-odzyskaj” pomaga modelowi zrozumieć kontekst, ale większość istniejących rozwiązań używa ustalonych lub prostych losowych schematów maskowania. Pokazują one modelowi tylko wąski zakres wzorców braków i nie potrafią wiernie naśladować sposobu, w jaki dane realnie ulegają degradacji. Co gorsza, jeśli zbyt wcześnie ukryje się zbyt dużo informacji, trening może stać się niestabilny, podczas gdy zbyt małe maskowanie nie buduje odporności. Autorzy argumentują, że brakujące atrybuty zachowują się raczej jak losowe, zależne od kontekstu zakłócenia, które wchodzą w interakcje ze strukturą wielotypową grafu, i że należy je modelować w sposób bardziej elastyczny i kontrolowany.
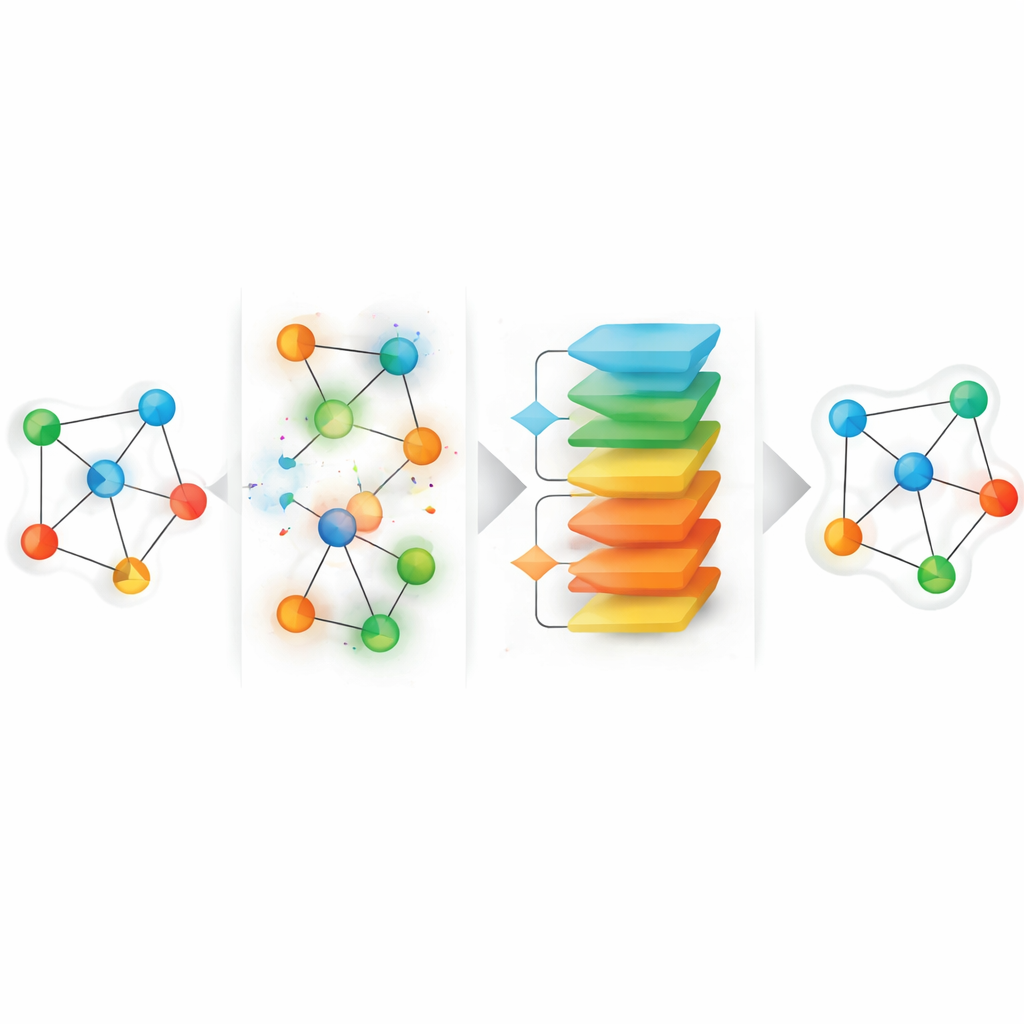
Perturbacja i odzyskiwanie jako spojrzenie na brakujące dane
Proponowane ramy, nazwane HGGAE, zaczynają od nowej perspektywy: traktują brakujące atrybuty jako wynik procesu perturbacji, który celowo zakłóca cechy i połączenia, a następnie uczą się odwracać te perturbacje. HGGAE najpierw tworzy „zaszumione widoki” grafu przez selektywne zastępowanie lub modyfikowanie atrybutów węzłów oraz lekkie zmiany wzorców połączeń wzdłuż różnych typów ścieżek. Moduł uczony przypisuje każdemu węzłowi wagę ważności i wykorzystuje ją do decydowania, które węzły zakłócać i w jakim stopniu. Na początku treningu system głównie perturbuje mniej ważne węzły, stawiając łatwiejsze zadania odzyskiwania. W miarę postępu treningu stopniowo zwiększa trudność i zaczyna zakłócać bardziej informacyjne węzły. Taki harmonogram przypominający program nauczania pozwala modelowi się ustabilizować przed stawieniem czoła trudniejszym zadaniom rekonstrukcji, a jednocześnie lepiej odzwierciedla niepewny, nierównomierny charakter realnych braków danych.
Utrzymywanie modelu uczciwym i wydajnym
Samo dodanie szumu nie wystarczy; należy także zapobiegać znacznemu odejściu modelu od realistycznych wzorców. Dlatego HGGAE zawiera komponent przeciwstawny: oddzielna sieć uczy się rozróżniać reprezentacje pochodzące z czystych wejść od tych wygenerowanych po perturbacji. Główny model jest trenowany nie tylko do rekonstrukcji atrybutów i wzorców strukturalnych, lecz także do oszukiwania tego dyskryminatora, popychając swoje wewnętrzne reprezentacje z powrotem w stronę „rzeczywistego” manifoldu danych nawet przy silnie zakłóconych wejściach. Aby utrzymać obliczenia w ryzach dla dużych grafów, metoda oblicza błędy rekonstrukcji tylko dla węzłów, które rzeczywiście zostały perturbowane w danym kroku treningowym, zamiast dla każdego węzła. To podejście z rzadkimi celami skupia naukę na najbardziej informatywnych pozycjach, pozostawiając jednocześnie koszt obliczeniowy zdominowany przez standardowy przebieg po całym grafie.
Potwierdzenie korzyści na realnych benchmarkach
Aby przetestować HGGAE, autorzy użyli czterech standardowych zbiorów danych heterogenicznych grafów reprezentujących artykuły naukowe, autorów, filmy i firmy, wszystkie z celowo niekompletnymi atrybutami. Oceniali klasyfikację węzłów (przewidywanie etykiet takich jak dziedzina badań czy kategoria firmy) oraz klastrowanie (grupowanie podobnych węzłów) przy różnych ilościach oznaczonych danych. W tych zadaniach HGGAE konsekwentnie dorównywał lub przewyższał silne metody bazowe. Zyski były szczególnie duże w rzadkim i zaszumionym zbiorze filmowym, gdzie poprawił jeden istotny wskaźnik trafności o około osiem punktów procentowych. Dodatkowe eksperymenty pokazują, że zarówno harmonogram perturbacji oparty na programie nauczania, jak i mechanizm perturbuj-i-odzyskaj są kluczowe: usunięcie ich lub zastąpienie stałymi maskami prowadzi do wyraźnego spadku wydajności.
Co to oznacza dla codziennych aplikacji grafowych
Dla czytelników główny wniosek jest taki, że zamiast ukrywać lub prymitywnie łatkować brakujące informacje w złożonych sieciach, silniejsze może być aktywne symulowanie, jak atrybuty ulegają degradacji i trenowanie modeli do ich naprawy w kontrolowany sposób. Traktując brakujące dane jako etapowy proces perturbacji i kierując odzyskiwanie wskazaniami strukturalnymi oraz kontrolą adversarialną, HGGAE uczy reprezentacji węzłów, które pozostają wiarygodne nawet gdy grafy rzeczywiste są nieuporządkowane. Przekłada się to na lepsze przewidywania i bardziej sensowne grupowania w systemach opartych na sieciach społecznych, naukowych czy biznesowych, gdzie niekompletne dane są raczej regułą niż wyjątkiem.
Cytowanie: Wang, Q., Shao, X. & Huang, X. A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing. Sci Rep 16, 13538 (2026). https://doi.org/10.1038/s41598-026-44190-4
Słowa kluczowe: heterogeniczne grafy, brakujące atrybuty, autoenkoder grafowy, uczenie reprezentacji, uczenie samonadzorowane