Clear Sky Science · pt
Um autoencoder generativo de perturbação-recuperação para grafos heterogêneos com atributos ausentes
Por que dados bagunçados em redes importam
De recomendações de filmes a motores de busca acadêmicos e descoberta de fármacos, muitas ferramentas modernas dependem de redes que conectam diferentes tipos de entidades: pessoas, artigos, empresas, filmes ou proteínas. Essas redes, chamadas grafos heterogêneos, não apenas registram quem está ligado a quem, mas também associam informações descritivas a cada nó, como a sinopse de um filme ou as etiquetas de um restaurante. Na prática, grande parte dessas informações está faltando ou é ruidosa, o que enfraquece silenciosamente a qualidade das previsões feitas sobre essas redes. Este artigo apresenta uma nova forma de treinar modelos nesses grafos imperfeitos para que lidem melhor com lacunas e erros nos dados.
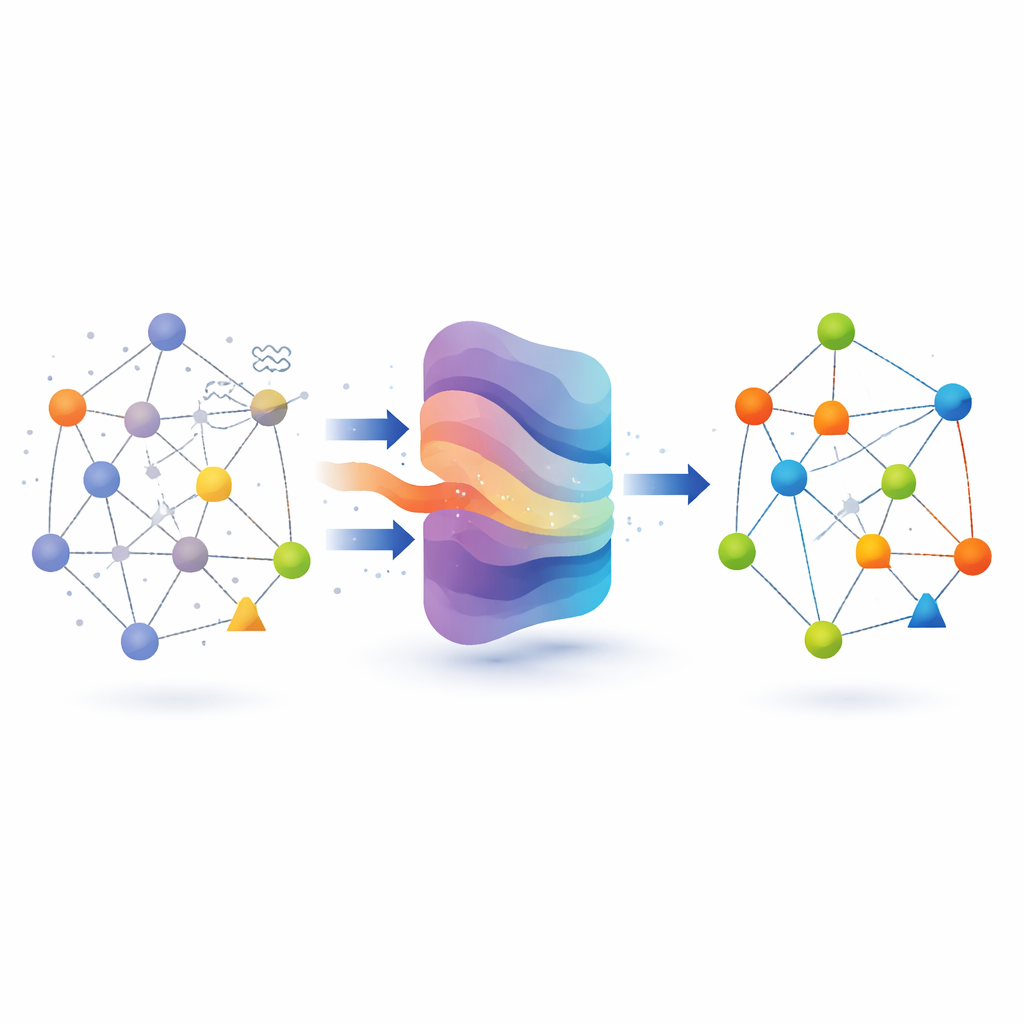
Redes com muitos tipos de entidades
Ao contrário de redes sociais simples, em que todo nó é uma pessoa e toda aresta é uma amizade, grafos heterogêneos misturam vários tipos de nós e de arestas. Um grafo acadêmico pode conectar autores, artigos e eventos; um grafo de um site de avaliações pode ligar usuários, estabelecimentos e resenhas. Cada nó vem com atributos: palavras-chave de um artigo, preferências de um usuário ou sinopse de um filme. Quando esses atributos estão incompletos ou corrompidos, métodos tradicionais de grafos têm dificuldade em aprender representações internas confiáveis dos nós. Isso, por sua vez, prejudica tarefas downstream, como classificar a área de um artigo, agrupar estabelecimentos similares ou recomendar filmes. Abordagens anteriores geralmente tentavam preencher atributos faltantes uma vez, usando regras fixas, e então treinavam modelos nessa versão única e “limpa” dos dados.
Do mascaramento a perturbações controladas
Métodos mais recentes tratam a informação ausente como um desafio de treinamento: eles escondem deliberadamente partes dos atributos dos nós (um processo chamado mascaramento) e ensinam o modelo a reconstruir as peças ocultas. Essa estratégia de “mascarar e recuperar” ajuda o modelo a entender o contexto, mas a maioria dos projetos existentes usa esquemas de mascaramento fixos ou aleatórios simples. Eles expõem o modelo a apenas uma gama limitada de padrões de ausência e não conseguem imitar fielmente como os dados do mundo real se degradam. Pior, se muita informação é ocultada cedo demais, o treinamento pode se tornar instável, enquanto mascaramentos insuficientes deixam de construir robustez. Os autores argumentam que atributos ausentes se comportam mais como perturbações aleatórias e dependentes do contexto que interagem com a estrutura multi-tipo da rede, e que precisam ser modelados de maneira mais flexível e controlável.
Uma visão de perturbar-e-recuperar dos dados ausentes
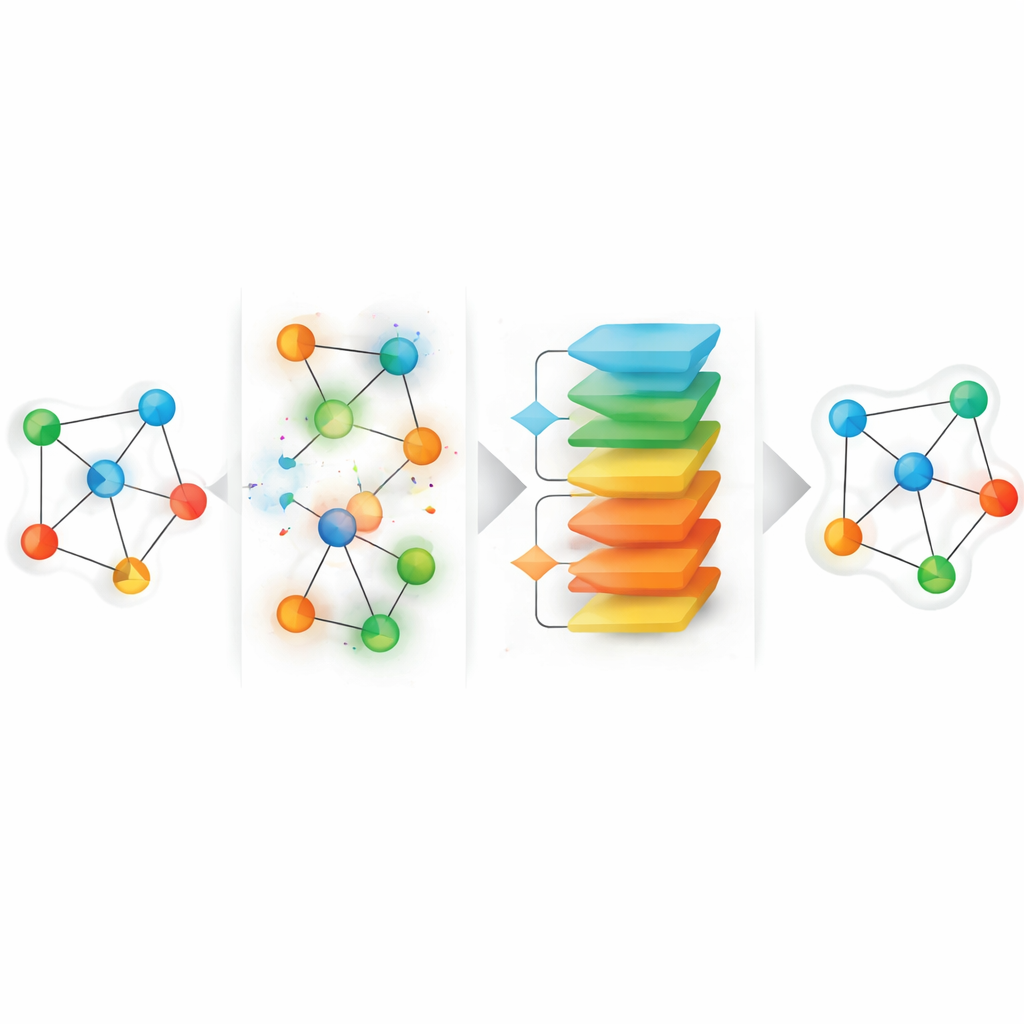
O arcabouço proposto, chamado HGGAE, parte de uma perspectiva diferente: tratar atributos ausentes como o resultado de um processo de perturbação que atrapalha deliberadamente características e conexões, e então aprender a desfazer essas perturbações. O HGGAE primeiro constrói “vistas ruidosas” do grafo ao substituir ou alterar seletivamente atributos de nós e ao modificar levemente padrões de ligação ao longo de diferentes tipos de caminhos. Um módulo treinável atribui a cada nó um escore de importância e o usa para decidir quais nós perturbar e em que intensidade. Durante o início do treinamento, o sistema perturba principalmente nós menos importantes, propondo tarefas de recuperação mais fáceis. À medida que o treinamento avança, ele aumenta gradualmente a dificuldade e começa a perturbar nós mais informativos. Esse cronograma, parecido com um currículo, permite que o modelo se estabilize antes de enfrentar problemas de reconstrução mais difíceis, ao mesmo tempo em que reflete melhor a natureza incerta e desigual dos dados ausentes reais.
Manter o modelo honesto e eficiente
Adicionar ruído por si só não é suficiente; o modelo também deve ser desencorajado a se afastar demais de padrões realistas. O HGGAE inclui, portanto, um componente adversarial: uma rede separada aprende a distinguir representações derivadas de entradas limpas daquelas geradas após perturbação. O modelo principal é treinado não apenas para reconstruir atributos e padrões estruturais, mas também para enganar esse discriminador, empurrando suas representações internas de volta ao “manifold” dos dados reais mesmo quando as entradas estão fortemente perturbadas. Para manter a computação manejável em grafos grandes, o método calcula erros de reconstrução apenas nos nós que realmente perturbou em cada passo de treinamento, em vez de em todos os nós. Esse desenho com alvo esparso foca o aprendizado nas posições mais informativas enquanto mantém o custo geral dominado por uma passagem padrão sobre o grafo completo.
Comprovando ganhos em benchmarks reais
Para testar o HGGAE, os autores utilizam quatro conjuntos de dados heterogêneos padrão representando artigos, autores, filmes e estabelecimentos, todos com atributos intencionalmente incompletos. Eles avaliam classificação de nós (prever rótulos como área de pesquisa ou categoria de estabelecimento) e clustering (agrupar nós similares) sob várias quantidades de dados rotulados. Nestas tarefas, o HGGAE consistentemente iguala ou supera métodos baselines fortes. Os ganhos são especialmente grandes em um conjunto de dados de filmes raso e ruidoso, onde melhora uma métrica-chave de acurácia em cerca de oito pontos percentuais. Experimentos adicionais mostram que tanto o cronograma de perturbação baseado em currículo quanto o mecanismo de perturbar-e-recuperar são cruciais: removê-los ou substituí-los por máscaras fixas leva a quedas claras de desempenho.
O que isso significa para aplicações cotidianas com grafos
Para os leitores, a principal conclusão é que, em vez de ocultar ou remendar de forma grosseira informações faltantes em redes complexas, pode ser mais eficaz simular ativamente como os atributos se corrompem e treinar modelos para repará-los de forma controlada. Ao ver os dados ausentes como um processo de perturbação em estágios e guiar a recuperação com pistas estruturais e uma verificação adversarial, o HGGAE aprende representações de nós que permanecem confiáveis mesmo quando grafos do mundo real estão bagunçados. Isso se traduz em melhores previsões e agrupamentos mais significativos em sistemas construídos sobre redes sociais, acadêmicas ou comerciais, onde dados incompletos são a regra, e não a exceção.
Citação: Wang, Q., Shao, X. & Huang, X. A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing. Sci Rep 16, 13538 (2026). https://doi.org/10.1038/s41598-026-44190-4
Palavras-chave: grafos heterogêneos, atributos ausentes, autoencoder de grafo, aprendizado de representação, aprendizado auto-supervisionado