Clear Sky Science · sv
En perturbations-återhämtnings generativ autoencoder för heterogena grafer med saknade attribut
Varför rörig data i nätverk spelar roll
Från filmtips till akademiska sökmotorer och läkemedelsupptäckt förlitar sig många moderna verktyg på nätverk som länkar olika typer av objekt: människor, artiklar, företag, filmer eller proteiner. Dessa nätverk, kallade heterogena grafer, registrerar inte bara vem som är kopplat till vem utan fäster också beskrivande information vid varje nod, såsom en films handling eller en restaurangs taggar. I verkligheten saknas eller är stor del av denna information brusig, vilket tyst underminerar kvaliteten på de förutsägelser som görs ovanpå dessa nätverk. Denna artikel presenterar ett nytt sätt att träna modeller på sådana ofullständiga grafer så att de bättre kan hantera luckor och fel i data.
Nätverk av många slags objekt
Till skillnad från enkla sociala nätverk där varje nod är en person och varje länk en vänskap, blandar heterogena grafer flera nod- och kanttyper. Ett akademiskt nätverk kan koppla författare, artiklar och konferenser; ett recensionsnätverk kan länka användare, företag och recensioner. Varje nod har attribut: en artikels nyckelord, en användares preferenser eller en films synopsis. När dessa attribut är ofullständiga eller korrupta har standardmetoder för grafer svårt att lära sig pålitliga interna representationer för noderna. Det skadar i sin tur uppgifter längre ner i kedjan, såsom att klassificera en artikels fält, gruppera liknande företag eller rekommendera filmer. Tidigare tillvägagångssätt försökte vanligtvis fylla i saknade attribut en gång, med fasta regler, och sedan träna modeller på denna enda, rensade version av datan.
Från maskering till kontrollerade störningar
Nyare metoder ser på saknad information som en träningsutmaning: de medvetet döljer delar av nodattributen (en process kallad maskering) och lär modellen att rekonstruera de dolda delarna. Denna "maskera-och-återställ"-strategi hjälper modellen att förstå kontext, men de flesta befintliga upplägg använder fasta eller enkla slumpmässiga maskeringsscheman. De utsätter modellen för bara ett snävt spektrum av saknade mönster och kan inte troget efterlikna hur verkliga data förfaller. Värre är att om för mycket information döljs för tidigt kan träningen bli instabil, medan för lite maskering misslyckas med att bygga robusthet. Författarna menar att saknade attribut beter sig mer som slumpmässiga, kontextberoende störningar som interagerar med nätverkets mångtypstruktur, och att de måste modelleras på ett mer flexibelt och kontrollerbart sätt.
En perturbations-och-återställ syn på saknad data
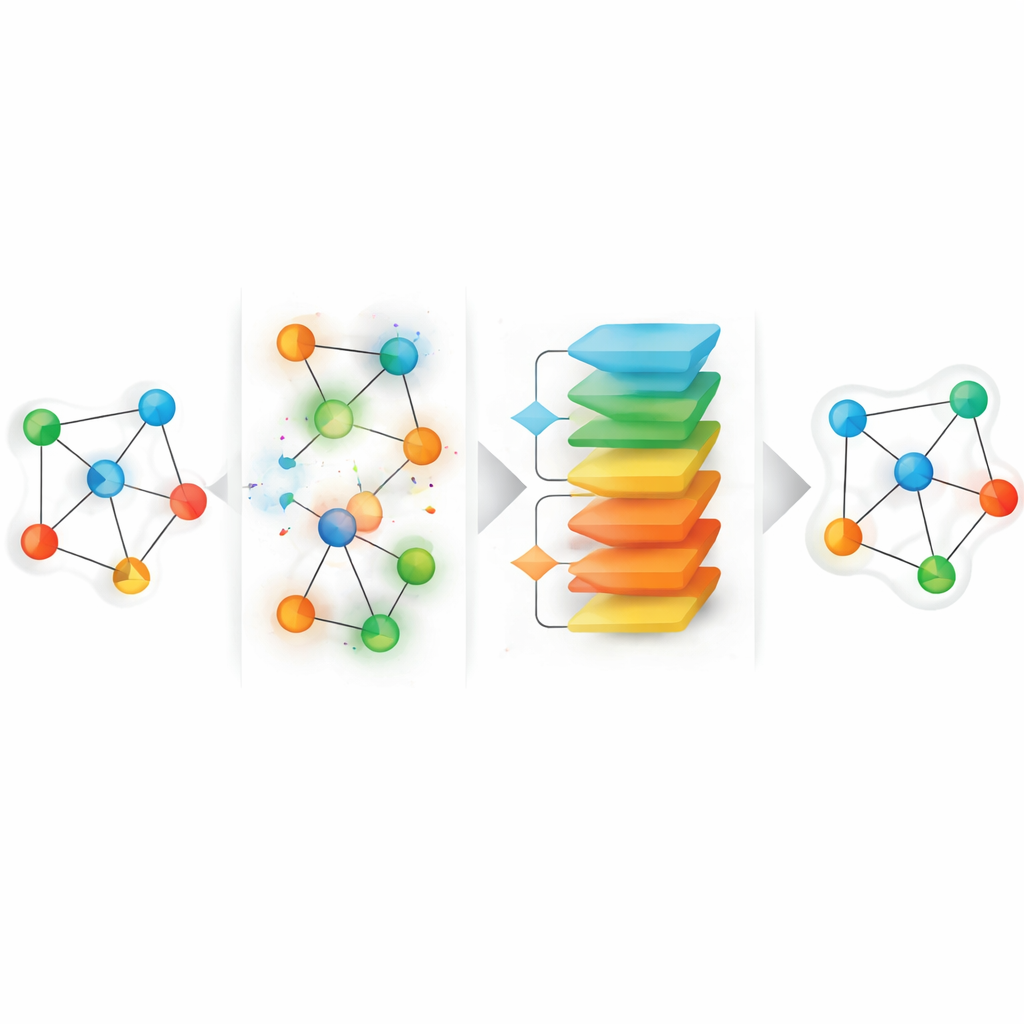
Det föreslagna ramverket, kallat HGGAE, börjar från ett nytt perspektiv: behandla saknade attribut som ett resultat av en perturbationsprocess som medvetet stör egenskaper och kopplingar, och lär sig sedan att ångra dessa störningar. HGGAE bygger först upp "brusiga vyer" av grafen genom att selektivt ersätta eller förändra nodattribut och lätt modifiera länkmönster längs olika typer av vägar. En träningsbar modulen tilldelar varje nod en betydelsescore och använder den för att avgöra vilka noder som ska störas och i vilken grad. Under tidig träning stör systemet mestadels mindre betydelsefulla noder, vilket ger enklare återställningsuppgifter. När träningen fortskrider ökar svårigheten gradvis och börjar störa mer informationsbärande noder. Detta läroplanslika schema tillåter modellen att stabilisera sig innan den möter svårare rekonstruktionsproblem, samtidigt som det bättre speglar den osäkra, ojämna naturen hos verkligt saknad data.
Hålla modellen ärlig och effektiv
Att bara lägga till brus räcker inte; modellen måste också motarbetas från att driva för långt bort från realistiska mönster. HGGAE inkluderar därför en adversarial komponent: ett separat nätverk lär sig att skilja representationer som kommer från rena indata från dem som genererats efter perturbation. Huvudmodellen tränas inte bara för att rekonstruera attribut och strukturella mönster utan också för att lura denna diskriminator, vilket knuffar dess interna representationer tillbaka mot den "verkliga" datamanifolden även när indatan är kraftigt störda. För att hålla beräkningen hanterbar på stora grafer beräknar metoden rekonstruktionsfel endast på de noder som faktiskt stördes i varje träningssteg, istället för på varje nod. Denna design med sparsamma mål fokuserar lärandet på de mest informativa positionerna samtidigt som den övergripande kostnaden domineras av en standardpass över hela grafen.
Bevisa vinsterna på verkliga benchmarks
För att testa HGGAE använder författarna fyra standarddataset för heterogena grafer som representerar akademiska artiklar, författare, filmer och företag, alla med avsiktligt ofullständiga attribut. De utvärderar nodklassificering (förutsäga etiketter såsom forskningsfält eller företagskategori) och klustring (gruppera liknande noder) under olika mängder märkta data. Över dessa uppgifter matchar eller överträffar HGGAE konsekvent starka basmetoder. Vinsterna är särskilt stora på ett glest och brusigt filmdatset, där det förbättrar en viktig noggrannhetssiffra med cirka åtta procentenheter. Ytterligare experiment visar att både det läroplansbaserade perturbationsschemat och perturbations-och-återställ-mekanismen är avgörande: att ta bort dem eller ersätta dem med fasta masker leder till tydliga prestandafall.
Vad detta innebär för vardagliga grafapplikationer
För läsaren är huvudslutsatsen att istället för att dölja eller grovt lappa över saknad information i komplexa nätverk kan det vara mer kraftfullt att aktivt simulera hur attribut går fel och träna modeller att reparera dem på ett kontrollerat sätt. Genom att betrakta saknad data som en stegvis perturbationsprocess och vägleda återställningen med strukturella ledtrådar och en adversarial kontroll, lär sig HGGAE nodrepresentationer som förblir pålitliga även när verkliga grafer är röriga. Detta översätts till bättre förutsägelser och mer meningsfulla grupperingar i system byggda ovanpå sociala, akademiska eller affärsnätverk där ofullständig data är normen snarare än undantaget.
Citering: Wang, Q., Shao, X. & Huang, X. A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing. Sci Rep 16, 13538 (2026). https://doi.org/10.1038/s41598-026-44190-4
Nyckelord: heterogena grafer, saknade attribut, grafautoencoder, representationsinlärning, självövervakad inlärning