Clear Sky Science · en
A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing
Why messy data in networks matters
From movie recommendations to academic search engines and drug discovery, many modern tools rely on networks that link different kinds of things: people, papers, businesses, films, or proteins. These networks, called heterogeneous graphs, not only record who is connected to whom, but also attach descriptive information to each node, such as a movie’s plot or a restaurant’s tags. In reality, much of this information is missing or noisy, which quietly weakens the quality of predictions made on top of these networks. This paper introduces a new way to train models on such imperfect graphs so that they can better handle gaps and errors in the data.
Networks of many kinds of things
Unlike simple social networks where every node is a person and every link is a friendship, heterogeneous graphs mix several node and link types. An academic graph might connect authors, papers, and venues; a review site graph might link users, businesses, and reviews. Each node comes with attributes: a paper’s keywords, a user’s preferences, or a movie’s synopsis. When these attributes are incomplete or corrupted, standard graph methods struggle to learn reliable internal representations of the nodes. That in turn hurts downstream tasks such as classifying a paper’s field, grouping similar businesses, or recommending films. Earlier approaches usually tried to fill in missing attributes once, using fixed rules, and then trained models on this single, cleaned-up version of the data.
From masking to controlled disturbances
More recent methods treat missing information as a training challenge: they deliberately hide parts of node attributes (a process called masking) and teach the model to reconstruct the hidden pieces. This “mask-and-recover” strategy helps the model understand context, but most existing designs use fixed or simple random masking schemes. They expose the model to only a narrow range of missing patterns and cannot faithfully mimic how real-world data degrades. Worse, if too much information is hidden too early, training can become unstable, while too little masking fails to build robustness. The authors argue that missing attributes behave more like random, context-dependent disturbances that interact with the network’s multi-type structure, and that they must be modeled in a more flexible and controllable way.
A perturb-and-recover view of missing data
The proposed framework, called HGGAE, starts from a fresh perspective: treat missing attributes as the outcome of a perturbation process that deliberately disturbs features and connections, and then learn to undo those perturbations. HGGAE first builds “noisy views” of the graph by selectively replacing or altering node attributes and slightly modifying link patterns along different types of paths. A trainable module assigns each node an importance score and uses it to decide which nodes to disturb and by how much. During early training, the system mostly perturbs less important nodes, posing easier recovery tasks. As training progresses, it gradually turns up the difficulty and begins to disturb more informative nodes. This curriculum-like schedule allows the model to stabilize before facing harder reconstruction problems, while better reflecting the uncertain, uneven nature of real missing data.
Keeping the model honest and efficient
Simply adding noise is not enough; the model must also be discouraged from drifting too far from realistic patterns. HGGAE therefore includes an adversarial component: a separate network learns to distinguish representations coming from clean inputs from those generated after perturbation. The main model is trained not only to reconstruct attributes and structural patterns, but also to fool this discriminator, nudging its internal representations back toward the “real” data manifold even when inputs are heavily disturbed. To keep computation manageable on large graphs, the method computes reconstruction errors only on the nodes it actually perturbed in each training step, instead of on every node. This sparse-target design focuses learning on the most informative positions while leaving the overall cost dominated by a standard pass over the full graph.
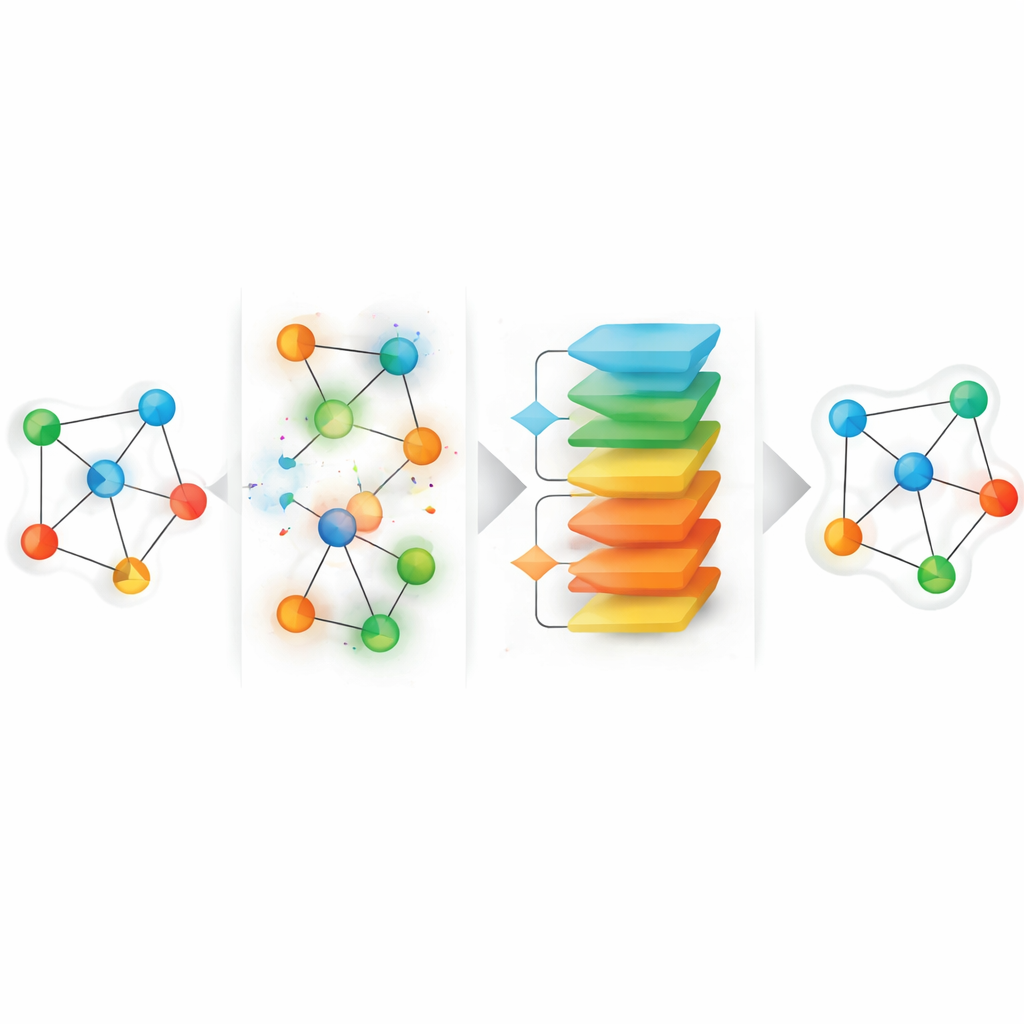
Proving the gains on real benchmarks
To test HGGAE, the authors use four standard heterogeneous graph datasets representing academic papers, authors, movies, and businesses, all with intentionally incomplete attributes. They evaluate node classification (predicting labels such as research field or business category) and clustering (grouping similar nodes) under various amounts of labeled data. Across these tasks, HGGAE consistently matches or surpasses strong baseline methods. The gains are especially large on a sparse and noisy movie dataset, where it improves one key accuracy score by about eight percentage points. Additional experiments show that both the curriculum-based perturbation schedule and the perturb-and-recover mechanism are crucial: removing them or replacing them with fixed masks leads to clear drops in performance.
What this means for everyday graph applications
For readers, the main takeaway is that instead of hiding or crudely patching over missing information in complex networks, it can be more powerful to actively simulate how attributes go wrong and train models to repair them in a controlled way. By viewing missing data as a staged perturbation process and guiding recovery with structural cues and an adversarial check, HGGAE learns node representations that remain reliable even when real-world graphs are messy. This translates into better predictions and more meaningful groupings in systems built on top of social, academic, or business networks where incomplete data is the norm rather than the exception.
Citation: Wang, Q., Shao, X. & Huang, X. A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing. Sci Rep 16, 13538 (2026). https://doi.org/10.1038/s41598-026-44190-4
Keywords: heterogeneous graphs, missing attributes, graph autoencoder, representation learning, self-supervised learning