Clear Sky Science · fr
Un autoencodeur génératif perturbation-récupération pour graphes hétérogènes avec attributs manquants
Pourquoi des données mal rangées dans les réseaux importent
Des recommandations de films aux moteurs de recherche académiques en passant par la découverte de médicaments, de nombreux outils modernes s’appuient sur des réseaux qui relient différents types d’entités : personnes, articles, entreprises, films ou protéines. Ces réseaux, appelés graphes hétérogènes, enregistrent non seulement qui est connecté à qui, mais associent aussi des informations descriptives à chaque nœud, comme le synopsis d’un film ou les tags d’un restaurant. En pratique, une grande partie de ces informations est manquante ou bruitée, ce qui affaiblit discrètement la qualité des prédictions basées sur ces réseaux. Cet article présente une nouvelle manière d’entraîner des modèles sur de tels graphes imparfaits afin qu’ils gèrent mieux les lacunes et les erreurs dans les données.
Des réseaux mêlant de nombreux types d’entités
Contrairement aux réseaux sociaux simples où chaque nœud est une personne et chaque lien une amitié, les graphes hétérogènes mélangent plusieurs types de nœuds et de liens. Un graphe académique peut relier auteurs, articles et conférences ; un graphe de site d’avis peut lier utilisateurs, commerces et commentaires. Chaque nœud porte des attributs : les mots-clés d’un article, les préférences d’un utilisateur ou le synopsis d’un film. Quand ces attributs sont incomplets ou corrompus, les méthodes de graphe classiques peinent à apprendre des représentations internes fiables des nœuds. Cela nuit ensuite à des tâches en aval telles que la classification du domaine d’un article, le regroupement de commerces similaires ou la recommandation de films. Les approches antérieures tentaient généralement d’imputer les attributs manquants une fois pour toutes, en utilisant des règles fixes, puis d’entraîner des modèles sur cette version unique et « nettoyée » des données.
Du masquage aux perturbations contrôlées
Les méthodes plus récentes considèrent l’absence d’information comme un défi d’entraînement : elles cachent délibérément des parties des attributs des nœuds (un processus appelé masquage) et apprennent au modèle à reconstruire les parties cachées. Cette stratégie « masquer-et-récupérer » aide le modèle à comprendre le contexte, mais la plupart des conceptions existantes utilisent des schémas de masquage fixes ou simplement aléatoires. Elles exposent le modèle à une gamme limitée de motifs de manque et ne reproduisent pas fidèlement la façon dont les données réelles se dégradent. Pire, si trop d’information est cachée trop tôt, l’entraînement peut devenir instable, tandis qu’un masquage insuffisant ne construit pas la robustesse. Les auteurs soutiennent que les attributs manquants se comportent plutôt comme des perturbations aléatoires dépendantes du contexte qui interagissent avec la structure multi-type du réseau, et qu’il faut les modéliser de manière plus flexible et contrôlable.
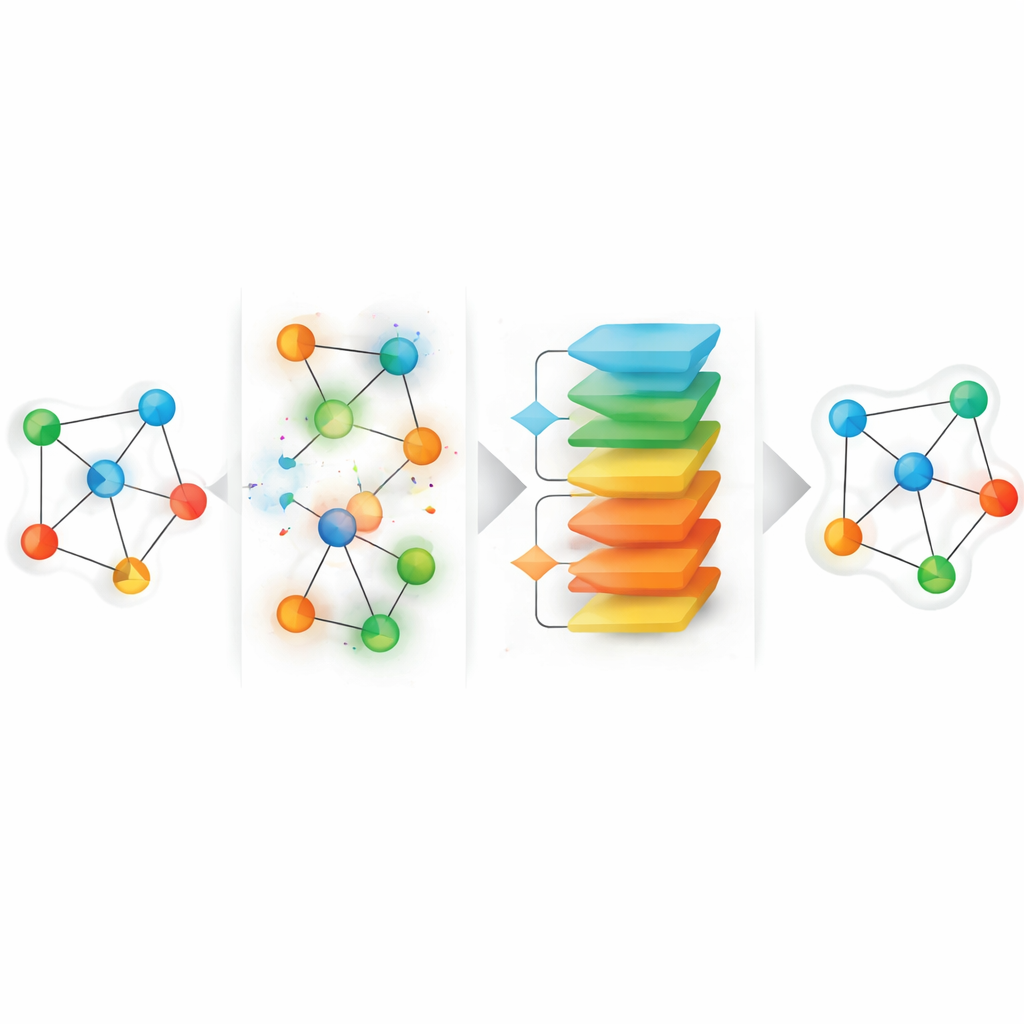
Une vue perturbation-récupération des données manquantes
Le cadre proposé, appelé HGGAE, adopte une perspective nouvelle : traiter les attributs manquants comme le résultat d’un processus de perturbation qui dérange volontairement les caractéristiques et les connexions, puis apprendre à annuler ces perturbations. HGGAE construit d’abord des « vues bruitées » du graphe en remplaçant ou modifiant sélectivement les attributs des nœuds et en ajustant légèrement les motifs de liens le long de différents types de chemins. Un module entraînable attribue à chaque nœud un score d’importance et l’utilise pour décider quels nœuds perturber et dans quelle mesure. Pendant les premiers stades de l’entraînement, le système perturbe principalement les nœuds moins importants, proposant des tâches de récupération plus faciles. Au fur et à mesure de l’entraînement, il augmente progressivement la difficulté et commence à déranger des nœuds plus informatifs. Ce calendrier de type curriculum permet au modèle de se stabiliser avant d’affronter des problèmes de reconstruction plus difficiles, tout en reflétant mieux la nature incertaine et inégale des données manquantes réelles.
Conserver l’honnêteté et l’efficacité du modèle
Ajouter du bruit ne suffit pas ; il faut aussi empêcher le modèle de s’éloigner trop des motifs réalistes. HGGAE inclut donc une composante adversariale : un réseau séparé apprend à distinguer les représentations issues d’entrées propres de celles générées après perturbation. Le modèle principal est entraîné non seulement à reconstruire les attributs et les motifs structurels, mais aussi à tromper ce discriminateur, poussant ses représentations internes vers la variété de données « réelle » même quand les entrées sont fortement perturbées. Pour garder le calcul raisonnable sur de grands graphes, la méthode calcule les erreurs de reconstruction uniquement sur les nœuds qu’elle a effectivement perturbés à chaque étape d’entraînement, au lieu de tous les nœuds. Ce ciblage clairsemé concentre l’apprentissage sur les positions les plus informatives tout en faisant en sorte que le coût global soit dominé par un passage standard sur le graphe complet.
Montrer les gains sur des benchmarks réels
Pour tester HGGAE, les auteurs utilisent quatre jeux de données hétérogènes standard représentant des articles académiques, des auteurs, des films et des commerces, tous avec des attributs intentionnellement incomplets. Ils évaluent la classification de nœuds (prédire des étiquettes comme le domaine de recherche ou la catégorie d’un commerce) et le clustering (regrouper des nœuds similaires) sous diverses quantités de données étiquetées. Sur ces tâches, HGGAE atteint systématiquement ou dépasse des méthodes de référence solides. Les gains sont particulièrement importants sur un jeu de données de films clairsemé et bruité, où il améliore un score d’exactitude clé d’environ huit points de pourcentage. Des expériences additionnelles montrent que le calendrier de perturbation basé sur un curriculum et le mécanisme perturbation-récupération sont cruciaux : les supprimer ou les remplacer par des masques fixes entraîne des baisses de performance nettes.
Ce que cela signifie pour les applications courantes de graphes
Pour les lecteurs, la conclusion principale est que, au lieu de cacher ou de colmater grossièrement l’information manquante dans des réseaux complexes, il peut être plus efficace de simuler activement la façon dont les attributs se dégradent et d’entraîner les modèles à les réparer de manière contrôlée. En considérant les données manquantes comme un processus de perturbation graduée et en guidant la récupération par des indices structurels et une vérification adversariale, HGGAE apprend des représentations de nœuds qui restent fiables même quand les graphes du monde réel sont désordonnés. Cela se traduit par de meilleures prédictions et des regroupements plus pertinents dans les systèmes construits sur des réseaux sociaux, académiques ou commerciaux où les données incomplètes sont la norme plutôt que l’exception.
Citation: Wang, Q., Shao, X. & Huang, X. A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing. Sci Rep 16, 13538 (2026). https://doi.org/10.1038/s41598-026-44190-4
Mots-clés: graphes hétérogènes, attributs manquants, autoencodeur de graphe, apprentissage de représentations, apprentissage auto-supervisé