Clear Sky Science · ru
Генеративный автоэнкодер восстановления после возмущений для гетерогенных графов с отсутствующими атрибутами
Почему неряшливые данные в сетях имеют значение
От рекомендательных систем для фильмов до академических поисковиков и разработки лекарств — многие современные инструменты опираются на сети, связывающие разные типы объектов: людей, статьи, компании, фильмы или белки. Такие сети, называемые гетерогенными графами, не только фиксируют, кто с кем связан, но и хранят описательную информацию о каждой вершине, например синопсис фильма или теги ресторана. На практике значительная часть этих данных отсутствует или шумна, что незаметно снижает качество предсказаний, сделанных поверх этих сетей. В статье предлагается новый способ обучения моделей на таких несовершенных графах, который помогает им лучше справляться с пробелами и ошибками в данных.
Сети из разных типов объектов
В отличие от простых социальных сетей, где каждая вершина — человек, а каждое ребро — дружба, гетерогенные графы объединяют несколько типов вершин и связей. Академический граф может соединять авторов, статьи и конференции; граф обзоров — пользователей, бизнесы и отзывы. Каждая вершина сопровождается атрибутами: ключевые слова статьи, предпочтения пользователя или синопсис фильма. Когда эти атрибуты неполны или искажены, стандартные графовые методы испытывают трудности при обучении надежных внутренних представлений узлов. Это, в свою очередь, вредит задачам, таким как классификация области статьи, группировка похожих бизнесов или рекоммендации фильмов. Ранее подходы обычно пытались один раз заполнить отсутствующие атрибуты по фиксированным правилам и затем обучали модели на этой единственной, «очищенной» версии данных.
От маскировки к контролируемым возмущениям
Более свежие методы рассматривают отсутствие информации как учебную задачу: они намеренно скрывают части атрибутов вершин (процесс, называемый маскировкой) и обучают модель восстанавливать скрытое. Эта стратегия «замаскировать-и-восстановить» помогает модели усвоить контекст, но большинство существующих схем используют фиксированные или простые случайные маскировки. Они открывают модели лишь узкий набор шаблонов пропусков и не могут достоверно имитировать, как данные деградируют в реальности. Хуже того, если слишком много информации скрывать слишком рано, обучение может стать нестабильным, тогда как слишком слабая маскировка не развивает робустность. Авторы утверждают, что отсутствие атрибутов скорее похоже на случайные, зависящие от контекста возмущения, которые взаимодействуют со структурой сети разных типов, и что это нужно моделировать более гибко и управляемо.
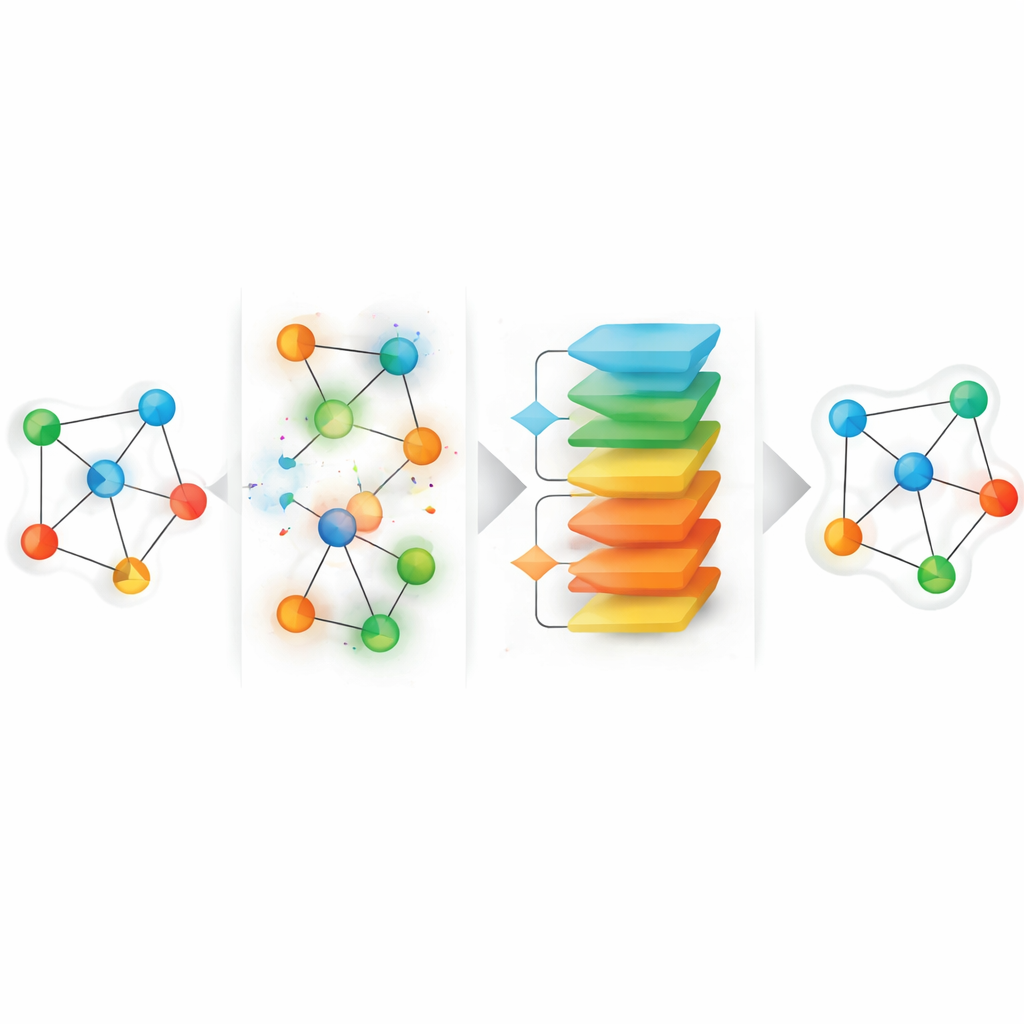
Видение отсутствующих данных как процесса возмущения и восстановления
Предлагаемая структура, названная HGGAE, исходит из другой перспективы: рассматривать отсутствующие атрибуты как результат процесса возмущения, который намеренно искажает признаки и связи, а затем учиться отменять эти искажения. HGGAE сначала строит «шумные представления» графа, выборочно заменяя или изменяя атрибуты вершин и слегка модифицируя шаблоны связей вдоль различных типов путей. Обучаемый модуль присваивает каждой вершине оценку важности и использует её, чтобы решить, какие вершины возмущать и в какой степени. На ранних этапах обучения система в основном возмущает менее важные вершины, создавая более простые задачи восстановления. По мере продвижения обучения она постепенно повышает сложность и начинает искажать более информативные вершины. Такое расписание, напоминающее учебный план, позволяет модели стабилизироваться перед более сложными задачами реконструкции и лучше отражает неопределённый, неравномерный характер реальных пропусков данных.
Сохранение честности и эффективности модели
Просто добавить шум недостаточно; модель также нужно удерживать от ухода слишком далеко от реалистичных паттернов. Поэтому HGGAE включает состязательный компонент: отдельная сеть учится отличать представления, полученные из чистых входов, от тех, что сгенерированы после возмущения. Основная модель обучается не только восстанавливать атрибуты и структурные паттерны, но и обманывать этот дискриминатор, подтягивая свои внутренние представления назад к «реальному» многообразию данных даже при сильных искажениях входов. Чтобы сохранить вычислительную управляемость на больших графах, метод вычисляет ошибки реконструкции только по тем вершинам, которые были действительно возмущены на данном шаге обучения, а не по всем вершинам. Такой дизайн с разреженной целью фокусирует обучение на самых информативных позициях, при этом общая стоимость вычислений остаётся определяемой стандартным проходом по всему графу.
Доказательства преимуществ на реальных бенчмарках
Чтобы протестировать HGGAE, авторы использовали четыре стандартных набора гетерогенных графов, представляющих статьи, авторов, фильмы и бизнесы, все с намеренно неполными атрибутами. Они оценивали классификацию узлов (предсказание меток, таких как исследовательская область или категория бизнеса) и кластеризацию (группировку похожих узлов) при различном количестве размеченных данных. По этим задачам HGGAE последовательно сопоставим или превосходил сильные базовые методы. Выигрыш особенно заметен на разреженном и шумном наборе данных о фильмах, где он улучшает ключевую метрику точности примерно на восемь процентных пунктов. Дополнительные эксперименты показывают, что и расписание возмущений по учебному плану, и механизм возмущения-и-восстановления критически важны: их удаление или замена фиксированными масками приводит к явному падению качества.
Что это означает для повседневных графовых приложений
Для читателей главный вывод в том, что вместо сокрытия или грубого исправления отсутствующей информации в сложных сетях более эффективно активно моделировать, как атрибуты портятся, и обучать модели их исправлять управляемым образом. Рассматривая отсутствующие данные как поэтапный процесс возмущений и направляя восстановление с помощью структурных подсказок и состязательной проверки, HGGAE формирует представления узлов, остающиеся надёжными даже когда реальные графы неряшливы. Это превращается в более точные предсказания и более осмысленные группировки в системах, построенных поверх социальных, академических или бизнес-сетей, где неполные данные скорее правило, чем исключение.
Цитирование: Wang, Q., Shao, X. & Huang, X. A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing. Sci Rep 16, 13538 (2026). https://doi.org/10.1038/s41598-026-44190-4
Ключевые слова: гетерогенные графы, отсутствующие атрибуты, графовый автоэнкодер, обучение представлений, самостоятельное обучение