Clear Sky Science · es
Un autoencoder generativo de perturbación-recuperación para grafos heterogéneos con atributos ausentes
Por qué importa que los datos en redes estén desordenados
Desde recomendaciones de películas hasta motores de búsqueda académicos y descubrimiento de fármacos, muchas herramientas modernas dependen de redes que conectan distintos tipos de entidades: personas, artículos, empresas, filmes o proteínas. Estas redes, llamadas grafos heterogéneos, no solo registran quién está conectado con quién, sino que también adjuntan información descriptiva a cada nodo, como la sinopsis de una película o las etiquetas de un restaurante. En la práctica, gran parte de esa información está ausente o es ruidosa, lo que debilita de forma silenciosa la calidad de las predicciones que se realizan sobre estas redes. Este artículo presenta una nueva manera de entrenar modelos sobre grafos imperfectos para que puedan manejar mejor las lagunas y los errores en los datos.
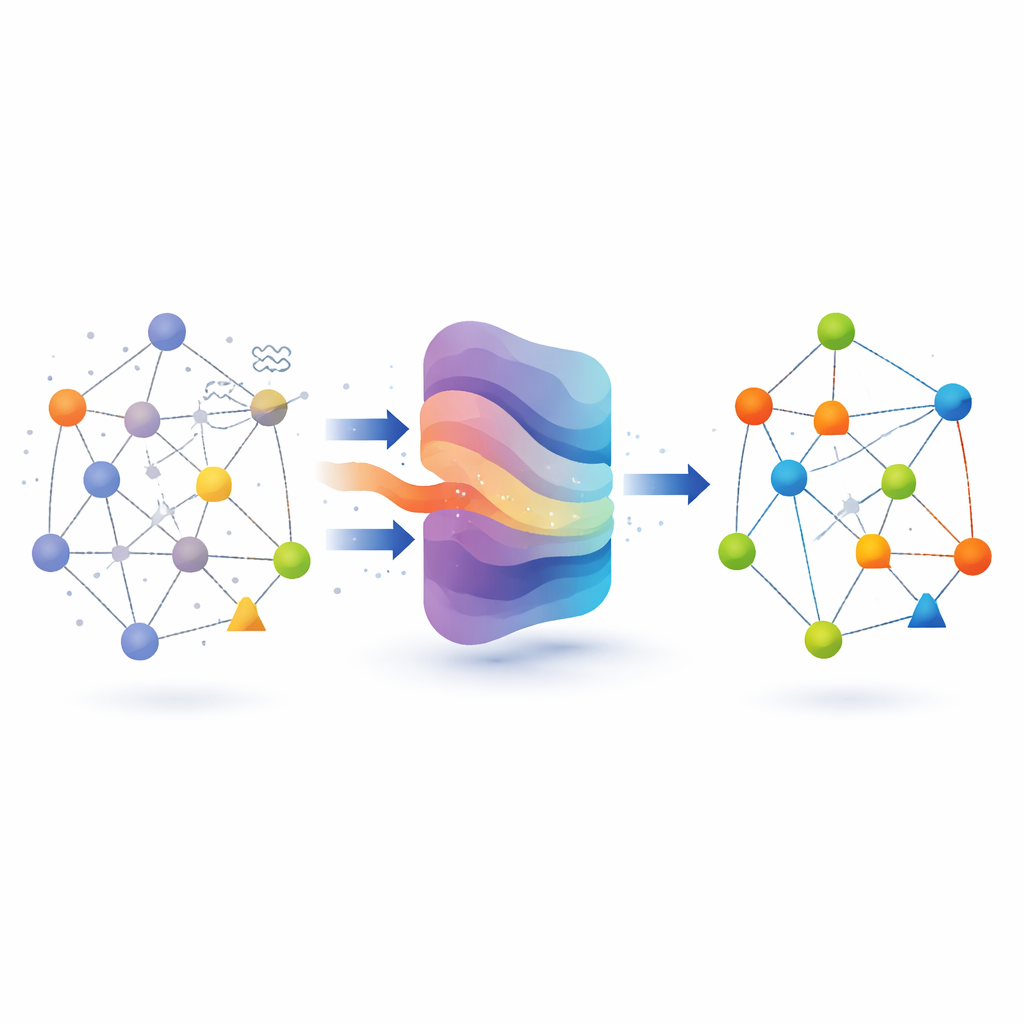
Redes con muchos tipos de entidades
A diferencia de las redes sociales simples donde cada nodo es una persona y cada enlace es una amistad, los grafos heterogéneos mezclan varios tipos de nodos y enlaces. Un grafo académico puede conectar autores, artículos y conferencias; un grafo de reseñas puede vincular usuarios, negocios y críticas. Cada nodo viene con atributos: las palabras clave de un artículo, las preferencias de un usuario o la sinopsis de una película. Cuando estos atributos están incompletos o corrompidos, los métodos estándar para grafos tienen dificultades para aprender representaciones internas fiables de los nodos. Eso a su vez perjudica tareas posteriores como clasificar el área de un artículo, agrupar negocios similares o recomendar películas. Enfoques anteriores suelen intentar rellenar los atributos faltantes una vez, usando reglas fijas, y luego entrenar modelos sobre esa versión única y ‘limpiada’ de los datos.
Del enmascaramiento a las perturbaciones controladas
Los métodos más recientes tratan la información faltante como un reto de entrenamiento: ocultan deliberadamente partes de los atributos de los nodos (un proceso llamado enmascaramiento) y enseñan al modelo a reconstruir las piezas ocultas. Esta estrategia de “enmascarar y recuperar” ayuda al modelo a entender el contexto, pero la mayoría de los diseños existentes usan esquemas de enmascaramiento fijos o simplemente aleatorios. Solo exponen al modelo a un rango estrecho de patrones de ausencia y no pueden imitar fielmente cómo se deterioran los datos en el mundo real. Peor aún, si se oculta demasiada información demasiado pronto, el entrenamiento puede volverse inestable, mientras que enmascarar muy poco no construye la robustez necesaria. Los autores sostienen que los atributos faltantes se comportan más como perturbaciones aleatorias y dependientes del contexto que interactúan con la estructura multimodal de la red, y que deben modelarse de manera más flexible y controlable.
Una visión de perturbación-y-recuperación de los datos faltantes
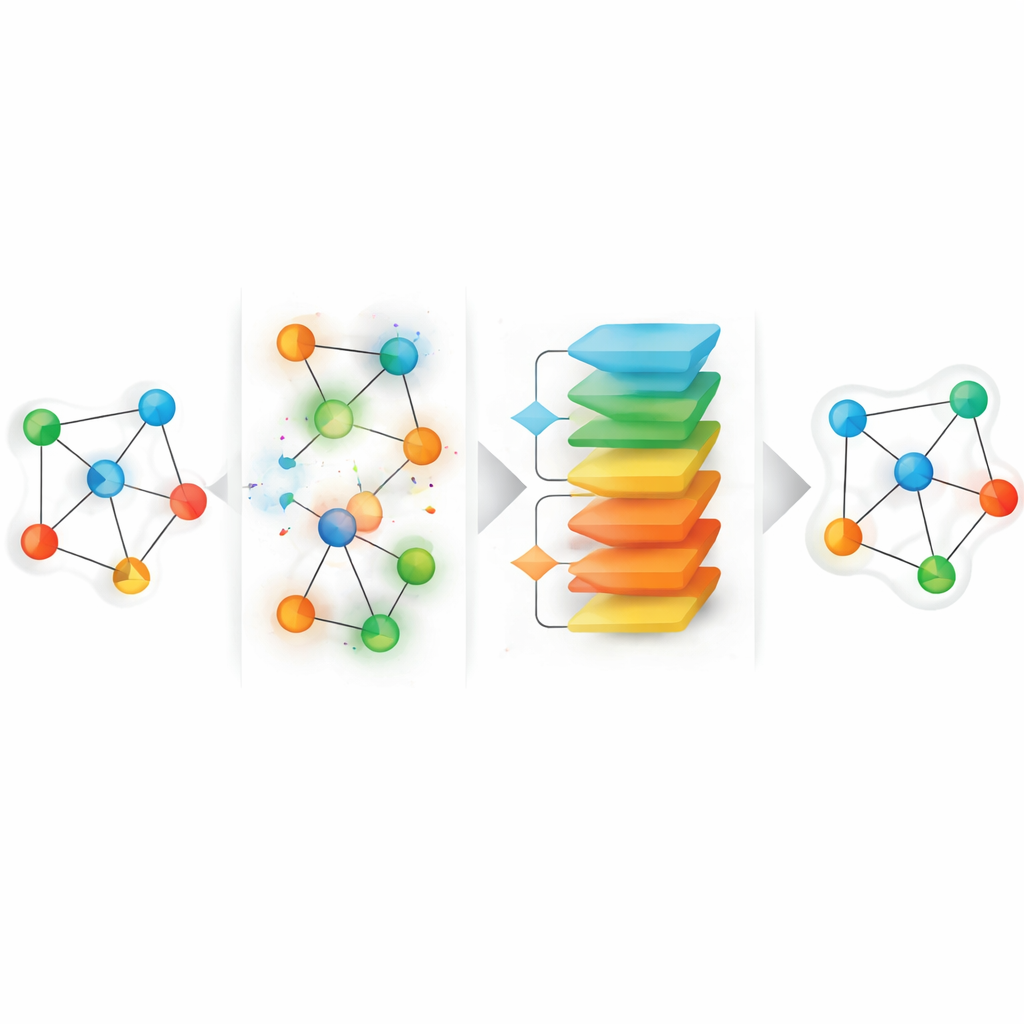
El marco propuesto, llamado HGGAE, parte de una perspectiva novedosa: tratar los atributos faltantes como el resultado de un proceso de perturbación que altera deliberadamente características y conexiones, y luego aprender a deshacer esas perturbaciones. HGGAE primero genera “vistas ruidosas” del grafo reemplazando o modificando selectivamente atributos de nodos y alterando ligeramente los patrones de enlaces a lo largo de distintos tipos de trayectorias. Un módulo entrenable asigna a cada nodo una puntuación de importancia y la usa para decidir qué nodos perturbar y en qué grado. Durante las fases tempranas del entrenamiento, el sistema perturba mayoritariamente nodos menos importantes, planteando tareas de recuperación más sencillas. A medida que avanza el entrenamiento, incrementa gradualmente la dificultad y empieza a perturbar nodos más informativos. Este calendario similar a un currículo permite que el modelo se estabilice antes de afrontar problemas de reconstrucción más difíciles, al tiempo que refleja mejor la naturaleza incierta y desigual de los datos faltantes reales.
Mantener el modelo honesto y eficiente
Agregar ruido no basta; también hay que desalentar que el modelo se aparte demasiado de los patrones realistas. Por ello HGGAE incluye un componente adversarial: una red separada aprende a distinguir las representaciones procedentes de entradas limpias de las generadas tras la perturbación. El modelo principal se entrena no solo para reconstruir atributos y patrones estructurales, sino también para engañar a este discriminador, empujando sus representaciones internas de vuelta hacia la variedad de datos “reales” incluso cuando las entradas están fuertemente perturbadas. Para mantener la computación manejable en grafos grandes, el método calcula los errores de reconstrucción solo sobre los nodos que realmente perturbó en cada paso de entrenamiento, en lugar de hacerlo sobre todos los nodos. Este diseño de objetivos dispersos centra el aprendizaje en las posiciones más informativas mientras deja que el coste global esté dominado por una pasada estándar sobre el grafo completo.
Demostrar las mejoras en benchmarks reales
Para evaluar HGGAE, los autores usan cuatro conjuntos de datos heterogéneos estándar que representan artículos académicos, autores, películas y negocios, todos con atributos intencionadamente incompletos. Evalúan clasificación de nodos (predecir etiquetas como campo de investigación o categoría del negocio) y clustering (agrupar nodos similares) bajo distintas cantidades de datos etiquetados. En estas tareas, HGGAE iguala o supera de forma consistente a métodos de referencia robustos. Las ganancias son especialmente notables en un conjunto de datos de películas, escaso y ruidoso, donde mejora una métrica clave de precisión en aproximadamente ocho puntos porcentuales. Experimentos adicionales muestran que tanto el programa de perturbación basado en currículo como el mecanismo de perturbar-y-recuperar son cruciales: eliminarlos o reemplazarlos por máscaras fijas provoca caídas claras en el rendimiento.
Qué significa esto para las aplicaciones cotidianas con grafos
Para el lector, la conclusión principal es que, en lugar de ocultar o parchear de forma burda la información faltante en redes complejas, puede ser más potente simular activamente cómo se degradan los atributos y entrenar a los modelos para repararlos de manera controlada. Al ver los datos faltantes como un proceso de perturbación por etapas y guiar la recuperación con señales estructurales y una comprobación adversarial, HGGAE aprende representaciones de nodos que siguen siendo fiables incluso cuando los grafos del mundo real están desordenados. Esto se traduce en mejores predicciones y agrupamientos más significativos en sistemas construidos sobre redes sociales, académicas o comerciales donde los datos incompletos son la norma en lugar de la excepción.
Cita: Wang, Q., Shao, X. & Huang, X. A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing. Sci Rep 16, 13538 (2026). https://doi.org/10.1038/s41598-026-44190-4
Palabras clave: grafos heterogéneos, atributos faltantes, autoencoder de grafos, aprendizaje de representaciones, aprendizaje auto-supervisado