Clear Sky Science · de
Ein generativer Autoencoder mit Perturbation-Wiederherstellung für heterogene Graphen mit fehlenden Attributen
Warum unordentliche Daten in Netzwerken wichtig sind
Von Filmempfehlungen über akademische Suchmaschinen bis hin zur Wirkstoffforschung stützen sich viele moderne Werkzeuge auf Netzwerke, die verschiedene Arten von Objekten verbinden: Personen, Artikel, Firmen, Filme oder Proteine. Diese Netzwerke, sogenannte heterogene Graphen, erfassen nicht nur, wer mit wem verbunden ist, sondern hängen auch beschreibende Informationen an jeden Knoten an, etwa die Handlung eines Films oder die Tags eines Restaurants. In der Realität fehlen jedoch viele dieser Informationen oder sind verrauscht, was stillschweigend die Qualität der Vorhersagen auf diesen Netzen schwächt. Dieses Papier führt eine neue Methode ein, Modelle auf solchen unvollkommenen Graphen zu trainieren, damit sie besser mit Lücken und Fehlern in den Daten umgehen können.
Netzwerke mit vielen Arten von Objekten
Im Gegensatz zu einfachen sozialen Netzwerken, in denen jeder Knoten eine Person und jede Verbindung eine Freundschaft ist, mischen heterogene Graphen mehrere Knoten- und Beziehungstypen. Ein akademischer Graph könnte Autoren, Artikel und Konferenzen verbinden; ein Bewertungsplattform-Graph könnte Nutzer, Unternehmen und Bewertungen verknüpfen. Jeder Knoten hat Attribute: Schlagwörter eines Artikels, Präferenzen eines Nutzers oder die Synopsis eines Films. Wenn diese Attribute unvollständig oder beschädigt sind, tun sich Standard-Graphmethoden schwer damit, verlässliche interne Repräsentationen der Knoten zu lernen. Das beeinträchtigt Folgeaufgaben wie die Klassifikation des Forschungsgebiets eines Artikels, das Gruppieren ähnlicher Unternehmen oder die Empfehlung von Filmen. Früher versuchten Ansätze meist, fehlende Attribute einmalig mit festen Regeln aufzufüllen und dann Modelle auf dieser einmal bereinigten Datenversion zu trainieren.
Vom Maskieren zu kontrollierten Störungen
Neuere Methoden betrachten fehlende Informationen als Trainingsherausforderung: Sie verbergen absichtlich Teile von Knotenattributen (ein Prozess, der Maskierung genannt wird) und bringen dem Modell bei, die verborgenen Teile zu rekonstruieren. Diese "Mask-and-recover"-Strategie hilft dem Modell, Kontext zu verstehen, doch die meisten vorhandenen Entwürfe verwenden feste oder einfache zufällige Maskierungsschemata. Sie setzen das Modell nur einer engen Bandbreite von Fehlmustern aus und können nicht realistisch nachbilden, wie reale Daten degradieren. Schlimmer noch: Wenn zu viele Informationen zu früh verborgen werden, kann das Training instabil werden, während zu wenig Maskierung keine Robustheit aufbaut. Die Autoren argumentieren, dass fehlende Attribute eher wie zufällige, kontextabhängige Störungen agieren, die mit der multi-typen Struktur des Netzwerks interagieren, und dass sie flexibler und kontrollierbarer modelliert werden müssen.
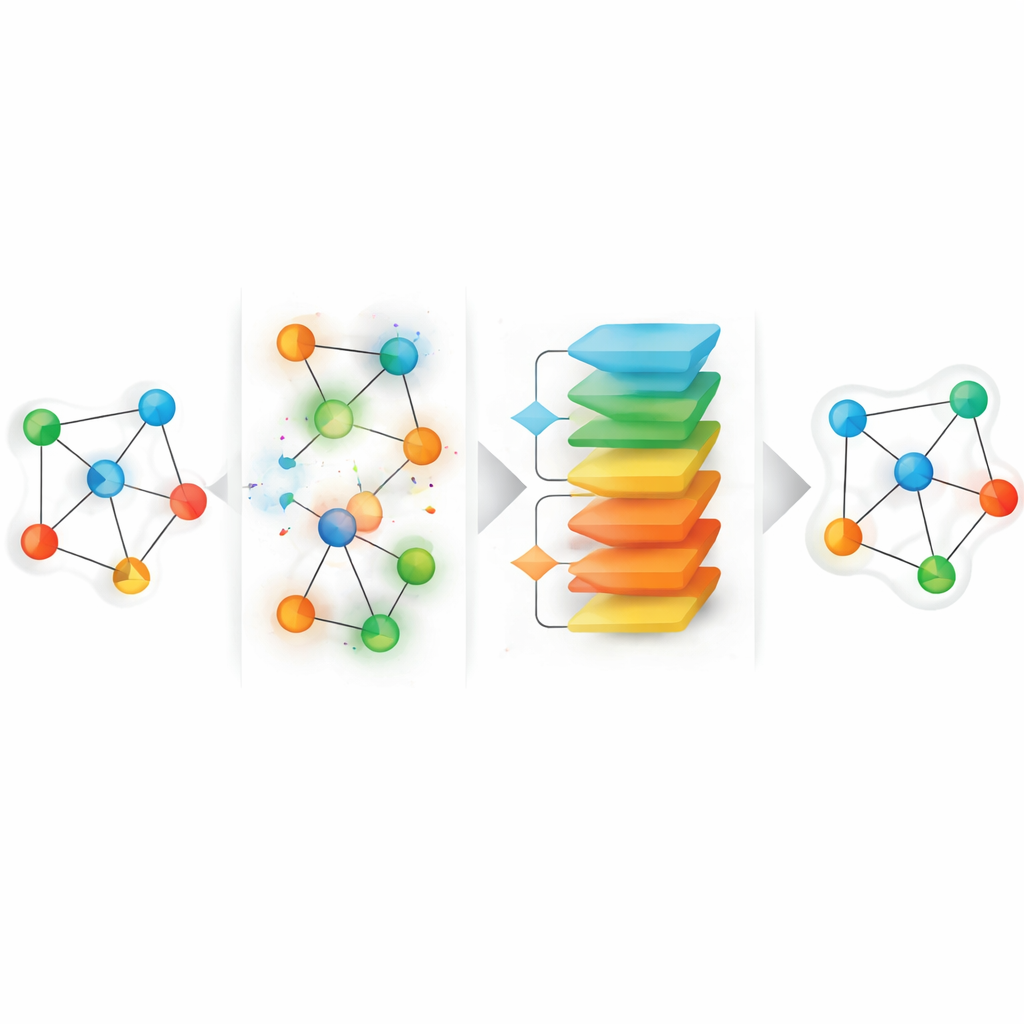
Eine Perturbations‑und‑Wiederherstellungs‑Perspektive auf fehlende Daten
Das vorgeschlagene Framework, HGGAE genannt, beginnt mit einer neuen Perspektive: Behandle fehlende Attribute als Ergebnis eines Perturbationsprozesses, der Merkmale und Verbindungen gezielt stört, und lerne dann, diese Störungen rückgängig zu machen. HGGAE erzeugt zunächst "rauschige Sichten" des Graphen, indem es Knotenattribute selektiv ersetzt oder verändert und leicht die Verbindungsmuster entlang verschiedener Pfadtypen modifiziert. Ein trainierbares Modul weist jedem Knoten eine Wichtigkeitsbewertung zu und nutzt diese, um zu entscheiden, welche Knoten gestört werden sollen und wie stark. Während der frühen Trainingsphase stört das System überwiegend weniger wichtige Knoten, was leichtere Wiederherstellungsaufgaben schafft. Mit fortschreitendem Training erhöht es schrittweise die Schwierigkeit und beginnt, informativer Knoten zu stören. Dieser lehrplanartige Zeitplan erlaubt dem Modell, sich zu stabilisieren, bevor es schwierigere Rekonstruktionsaufgaben bewältigen muss, und spiegelt zugleich die unsichere, ungleichmäßige Natur realer fehlender Daten besser wider.
Das Modell ehrlich und effizient halten
Einfaches Hinzufügen von Rauschen reicht nicht aus; das Modell muss außerdem davon abgehalten werden, zu weit von realistischen Mustern abzuweichen. HGGAE enthält daher eine adversariale Komponente: Ein separates Netzwerk lernt zu unterscheiden, ob Repräsentationen von sauberen Eingaben oder von nach Perturbation erzeugten stammen. Das Hauptmodell wird nicht nur darauf trainiert, Attribute und strukturelle Muster zu rekonstruieren, sondern auch diesen Diskriminator zu täuschen, wodurch seine internen Repräsentationen selbst bei stark gestörten Eingaben wieder in Richtung der "echten" Daten‑Mannigfaltigkeit gedrängt werden. Um die Berechnung auf großen Graphen handhabbar zu halten, berechnet die Methode Rekonstruktionsfehler nur für die Knoten, die in jedem Trainingsschritt tatsächlich gestört wurden, anstatt für jeden Knoten. Dieses Design mit sparsamen Zielen fokussiert das Lernen auf die informativsten Positionen, während die Gesamtkosten durch einen normalen Durchlauf über den vollständigen Graphen dominiert bleiben.
Nachweis der Vorteile an realen Benchmarks
Um HGGAE zu testen, verwenden die Autoren vier standardisierte heterogene Graph‑Datensätze, die Artikel, Autoren, Filme und Unternehmen repräsentieren, alle mit absichtlich unvollständigen Attributen. Sie bewerten Knotenklassifikation (Vorhersage von Labels wie Forschungsfeld oder Unternehmenskategorie) und Clustering (Gruppierung ähnlicher Knoten) unter verschiedenen Mengen gelabelter Daten. In diesen Aufgaben erreicht HGGAE durchweg Ergebnisse, die mit starken Baselines mithalten oder sie übertreffen. Die Zuwächse sind besonders groß bei einem spärlichen und verrauschten Filmdatensatz, wo ein zentraler Genauigkeitswert um etwa acht Prozentpunkte verbessert wird. Zusätzliche Experimente zeigen, dass sowohl der lehrplanbasierte Perturbationszeitplan als auch der Perturb-and-Recover‑Mechanismus entscheidend sind: Werden sie entfernt oder durch feste Masken ersetzt, sinkt die Leistung deutlich.
Was das für alltägliche Graph‑Anwendungen bedeutet
Für die Leserschaft ist die wichtigste Erkenntnis, dass es oft wirkungsvoller ist, fehlende Informationen in komplexen Netzwerken nicht nur zu verbergen oder grob zu übertünchen, sondern aktiv zu simulieren, wie Attribute fehlerhaft werden, und Modelle zu trainieren, sie kontrolliert zu reparieren. Indem man fehlende Daten als gestuften Perturbationsprozess betrachtet und die Wiederherstellung mit strukturellen Hinweisen und einer adversarialen Prüfung steuert, lernt HGGAE Knotenrepräsentationen, die selbst bei unordentlichen Real‑World‑Graphen verlässlich bleiben. Das führt zu besseren Vorhersagen und aussagekräftigeren Gruppierungen in Systemen, die auf sozialen, akademischen oder geschäftlichen Netzwerken aufbauen, in denen unvollständige Daten eher die Regel als die Ausnahme sind.
Zitation: Wang, Q., Shao, X. & Huang, X. A perturbation-recovery generative autoencoder for heterogeneous graphs with attributes missing. Sci Rep 16, 13538 (2026). https://doi.org/10.1038/s41598-026-44190-4
Schlüsselwörter: heterogene Graphen, fehlende Attribute, Graph-Autoencoder, Repräsentationslernen, selbstüberwachtes Lernen