Clear Sky Science · zh
结合地理空间情报与机器学习用于洪水易损性制图
这对人和地方的重要性
洪水是破坏性最强的自然灾害之一,随着城市向河谷扩展和气候变暖,洪水变得越来越频繁且代价高昂。然而,许多地区仍然缺乏能精确显示哪些区域最容易发生洪涝的详细可靠地图。本研究解释了科学家如何结合卫星观测、地理数据和先进的计算学习技术,为伊朗一个大且复杂的流域创建高精度的洪水“易损性”地图。他们开发的方法有助于规划者和社区更好地了解未来洪水最可能发生的地点,具有全球推广价值。
了解有风险的流域
研究聚焦于伊朗西南部的大卡鲁恩(Great Karun)流域,这里有该国最大的河流以及数百万居民、农田和工业设施。该流域包括高山、深谷和低洼平原,拥有40多座大坝,并有严重洪水的历史,包括2019年的一次破坏性事件。由于流域内地形和气候差异很大,在强降雨时预测水流汇集地点具有挑战性。作者汇集了一套丰富的地理信息,描述气候(降雨、气温、蒸发、降雪)、水文(河流、大坝、排水模式)、土地覆盖(植被、土壤、地质、城市区)和地形(高程、坡度及相关指数)。他们利用覆盖2000–2019年的基于卫星的洪水记录,识别实际发生洪水的地点以用于模型训练和测试。
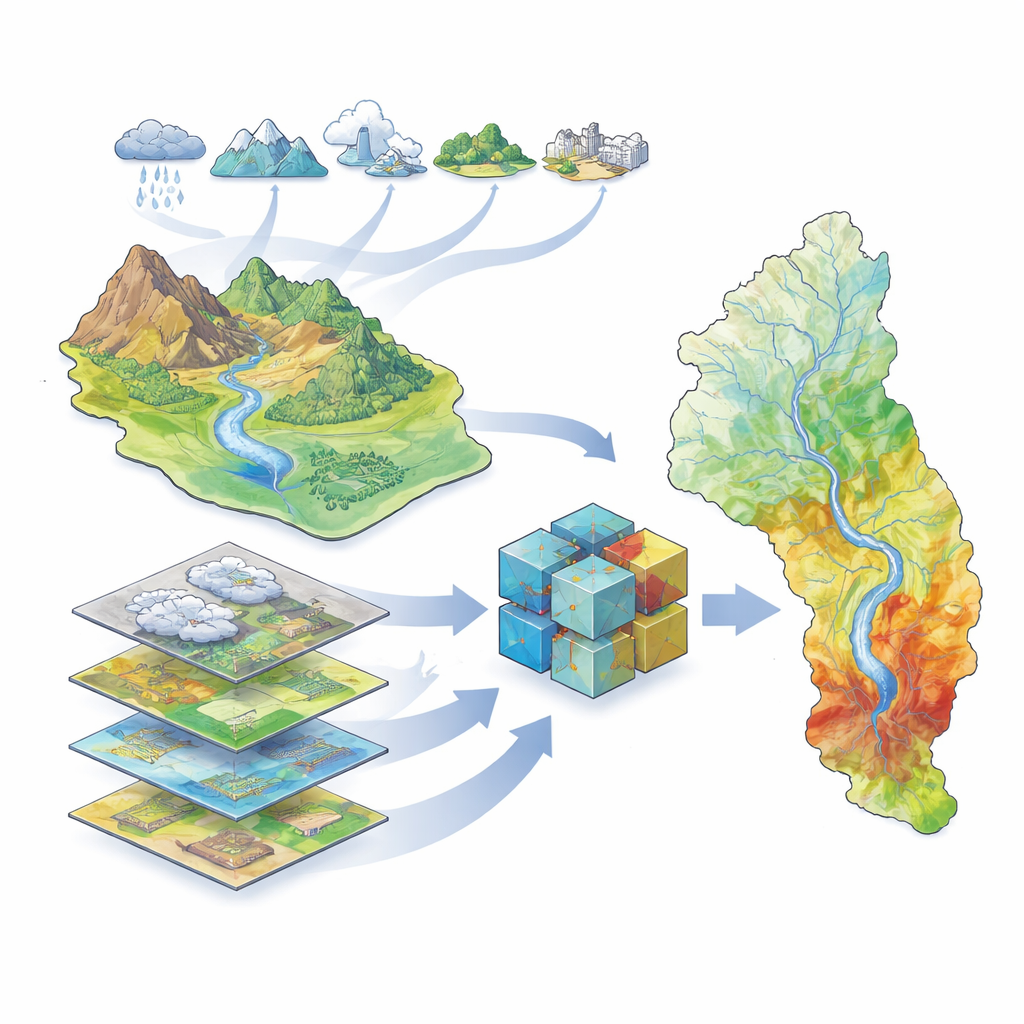
教计算机识别易淹地带
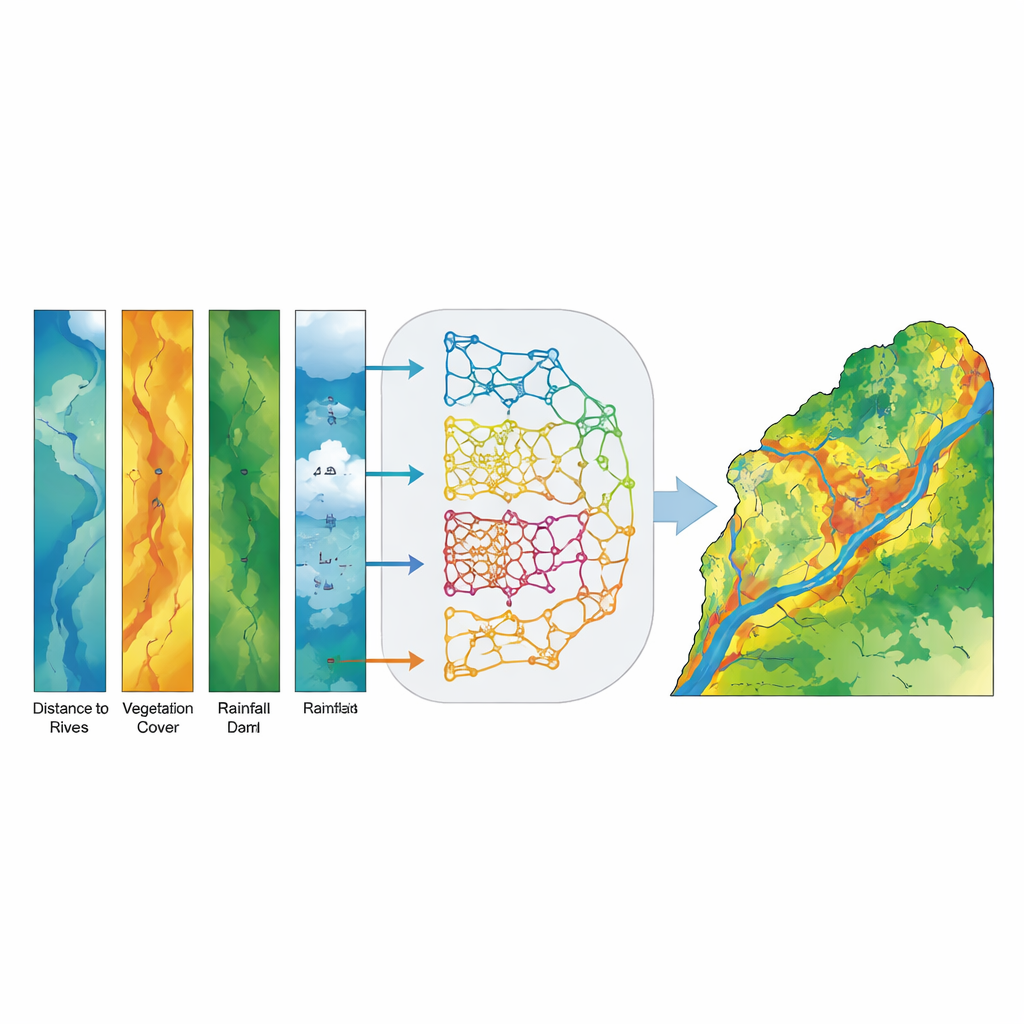
为了将这些数据转化为洪水易损性地图,团队使用了一类机器学习方法——这些算法通过示例学习模式而不是遵循固定方程。他们训练了五种不同的模型:一种传统的统计模型(称为广义线性模型)和四种基于树的模型,擅长处理复杂的非线性关系(决策树、随机森林、XGBoost 和 LightGBM)。每个模型使用相同的输入:表示环境因子的地图和洪涝发生与否的记录。算法随后学习将因子的组合(例如靠近河流的低洼地且植被稀疏)与更高的洪水概率关联起来。
将多种模型合成一个强有力的指导
研究人员没有选择单一“最佳”模型,而是构建了一个集成(投票)模型,将五个基础模型对流域每个位置的概率估计进行融合。每个模型并非简单投出是或否的票,而是为某个像素给出一个洪水倾向概率,集成模型计算这些概率的平均值。这种软投票策略减少了单一模型错误的影响,并强调不同方法达成一致的位置。最终输出是一张连续的洪水易损性地图,随后将其分为从“非常低”到“非常高”五个直观等级,便于决策者解读。
效果如何,哪些因素最关键?
该集成模型表现出异常高的准确性。在独立数据上测试时,它以AUC(曲线下面积)0.994准确地区分了被淹与未被淹区域,优于任何单一模型且远高于随机水平。高和非常高易损性区域与观测到的洪水位置高度吻合,尤其是在胡齐斯坦省的下游平原。关于关键因素的分析表明,距河流的距离、地面坡度和植被密度(从卫星影像测得)是洪水易损性的最强预测因子;高程、流量汇集、距大坝距离和降雨量提供了重要的次要信息。简言之,靠近河流、位于坡度较大或地形会聚处且缺乏茂密植被的地区,发生洪水的概率显著增加。
从地图到行动
对普通读者而言,本研究展示了一种强有力的方法,可以“教会”计算机读取地形并精准定位最可能发生洪水的地点,即便是在大范围、数据稀缺的地区。通过将过去洪水的卫星记录与气候、地形、河流和土地利用的详细地图融合,并将多种机器学习模型合成为单一更强的集成体,作者为大卡鲁恩流域生成了高度可靠的洪水易损性地图。这类地图可用于指导住宅和基础设施的安全选址,制定土地利用和大坝管理政策,支持预警和应急规划。由于该方法主要依赖全球可用的数据和广泛使用的工具,它可以推广到世界上其他流域,帮助社区在洪水来临前预测并减少损失。
引用: Rahimi, M., Malekmohammadi, B., Firozjaei, M.K. et al. Integrating geospatial intelligence and machine learning for flood susceptibility mapping. Sci Rep 16, 10228 (2026). https://doi.org/10.1038/s41598-026-41014-3
关键词: 洪水易损性制图, 机器学习, 地理空间数据, 流域管理, 减灾