Clear Sky Science · fr
Intégration du renseignement géospatial et de l’apprentissage automatique pour la cartographie de la susceptibilité aux inondations
Pourquoi cela compte pour les personnes et les territoires
Les inondations figurent parmi les catastrophes naturelles les plus destructrices, et elles deviennent plus fréquentes et coûteuses à mesure que les villes gagnent les vallées fluviales et que le climat se réchauffe. Pourtant, de nombreuses régions manquent encore de cartes détaillées et fiables montrant précisément quelles zones sont les plus susceptibles d’être inondées. Cette étude explique comment des scientifiques ont combiné observations satellitaires, données géographiques et techniques avancées d’apprentissage informatique pour créer des cartes de « susceptibilité » aux inondations très précises pour un grand bassin fluvial complexe en Iran. L’approche développée pourrait aider urbanistes et communautés du monde entier à mieux comprendre où les inondations futures sont les plus probables.
Comprendre un bassin versant à risque
La recherche se concentre sur le grand bassin du Karun dans le sud‑ouest de l’Iran, qui abrite le plus grand fleuve du pays et des millions de personnes, d’exploitations agricoles et d’industries. Ce bassin comporte de hautes montagnes, de profondes vallées et des plaines basses, plus de 40 barrages et un historique d’inondations sévères, dont un épisode destructeur en 2019. Parce que le paysage et le climat varient fortement à travers le bassin, il est difficile de prévoir où l’eau s’accumulera lors de fortes pluies. Les auteurs ont rassemblé un ensemble riche d’informations géographiques décrivant le climat (pluie, température, évaporation, neige), l’hydrologie (rivières, barrages, réseaux de drainage), la couverture du sol (végétation, sols, géologie, zones urbaines) et la topographie (élévation, pente et indices associés). En utilisant des archives satellitaires des inondations couvrant 2000–2019, ils ont identifié où les inondations s’étaient effectivement produites pour entraîner et tester leurs modèles.
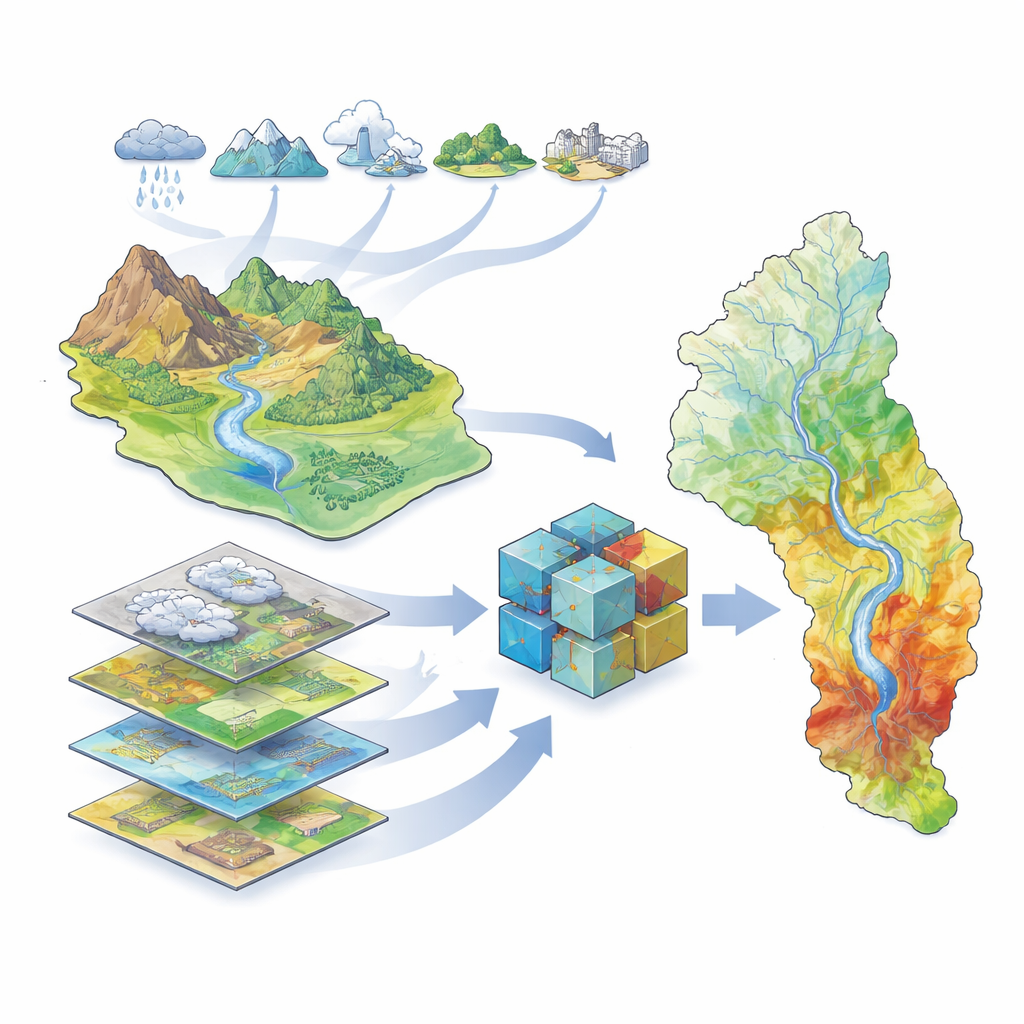
Apprendre aux ordinateurs à reconnaître les terrains inondables
Pour transformer ces données en cartes de susceptibilité aux inondations, l’équipe a utilisé une famille de méthodes d’apprentissage automatique — des algorithmes informatiques qui apprennent des motifs à partir d’exemples plutôt que d’appliquer des équations fixes. Ils ont entraîné cinq modèles différents : un modèle statistique traditionnel (appelé modèle linéaire généralisé) et quatre modèles à base d’arbres particulièrement aptes à gérer des relations complexes et non linéaires (Decision Tree, Random Forest, XGBoost et LightGBM). Chaque modèle a reçu les mêmes entrées : des cartes représentant les facteurs environnementaux et un enregistrement des lieux inondés et non inondés. Les algorithmes ont ensuite appris à associer des combinaisons de facteurs — par exemple des terrains bas à proximité des rivières avec une végétation clairsemée — à une probabilité accrue d’inondation.
Combiner plusieurs modèles en un guide robuste
Plutôt que de choisir un seul modèle « meilleur », les chercheurs ont construit un modèle ensembliste, ou de vote, qui combine les estimations de probabilité des cinq modèles de base pour chaque emplacement dans le bassin. Plutôt que d’émettre un vote oui/non, chaque modèle fournit une probabilité qu’un pixel donné soit propice aux inondations, et l’ensemble calcule une moyenne. Cette stratégie de vote « doux » réduit l’influence des erreurs d’un modèle individuel et met en évidence les lieux où les approches différentes s’accordent. Le produit final est une carte continue de susceptibilité aux inondations, ensuite regroupée en cinq classes intuitives de très faible à très élevée pour que les décideurs puissent l’interpréter facilement.
Quelle efficacité et quels facteurs importent le plus ?
Le modèle ensembliste s’est révélé remarquablement précis. Testé sur des données indépendantes, il a correctement distingué les zones inondées des zones non inondées avec un score Area Under the Curve (AUC) de 0,994, supérieur à celui de n’importe quel modèle individuel et bien au‑dessus de ce qui serait attendu par hasard. Les zones de susceptibilité élevée et très élevée correspondaient étroitement aux emplacements d’inondation observés, notamment dans les plaines aval de la province de Khuzestan. Une analyse des facteurs les plus importants a montré que la distance aux cours d’eau, la pente du terrain et la densité de végétation (mesurée à partir d’images satellitaires) étaient les meilleurs prédicteurs de susceptibilité aux inondations, l’altitude, l’accumulation d’écoulement, la distance aux barrages et les précipitations fournissant des informations secondaires importantes. En termes simples, être proche des rivières, sur un terrain plus pentu ou convergent, et dépourvu de végétation dense augmente fortement la probabilité qu’une zone subisse une inondation.
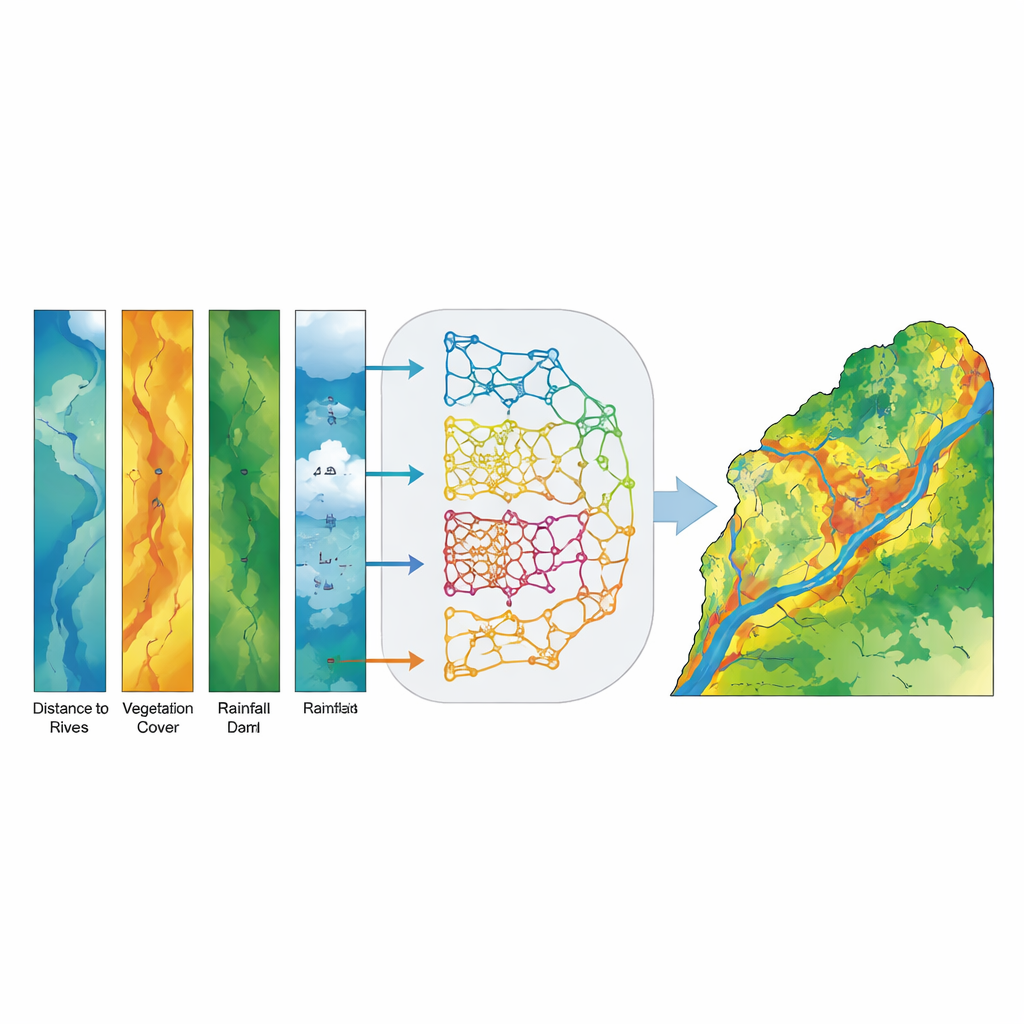
Des cartes à l’action
Pour le grand public, la conclusion est que cette étude démontre une méthode puissante pour « apprendre » aux ordinateurs à lire le paysage et repérer où les inondations sont les plus probables, même dans de vastes régions où les données sont rares. En fusionnant les archives satellitaires d’inondations passées avec des cartes détaillées du climat, du relief, des cours d’eau et de l’utilisation des sols, puis en combinant plusieurs modèles d’apprentissage automatique en un seul ensemble plus robuste, les auteurs ont produit des cartes de susceptibilité aux inondations très fiables pour le grand bassin du Karun. De telles cartes peuvent guider l’implantation plus sûre de logements et d’infrastructures, orienter les politiques d’aménagement du territoire et de gestion des barrages, et soutenir les systèmes d’alerte précoce et la planification d’urgence. Parce que la méthode repose principalement sur des données accessibles au niveau mondial et des outils largement utilisés, elle peut être transférée à d’autres bassins fluviaux dans le monde, aidant les communautés à anticiper et réduire les dégâts d’inondation avant que les eaux ne montent.
Citation: Rahimi, M., Malekmohammadi, B., Firozjaei, M.K. et al. Integrating geospatial intelligence and machine learning for flood susceptibility mapping. Sci Rep 16, 10228 (2026). https://doi.org/10.1038/s41598-026-41014-3
Mots-clés: cartographie de la susceptibilité aux inondations, apprentissage automatique, données géospatiales, gestion des bassins fluviaux, réduction des risques de catastrophe