Clear Sky Science · nl
Integratie van georuimtelijke inlichtingen en machine learning voor overstromingsgevoeligheidskaarten
Waarom dit belangrijk is voor mensen en plaatsen
Overstromingen behoren tot de meest verwoestende natuurrampen en komen steeds vaker en met grotere kosten voor naarmate steden zich uitbreiden in rivierdalgebieden en het klimaat opwarmt. Toch ontbreken in veel gebieden nog gedetailleerde, betrouwbare kaarten die precies aangeven welke locaties het meest vatbaar zijn voor overstromingen. Deze studie legt uit hoe wetenschappers satellietwaarnemingen, geografische gegevens en geavanceerde computerleertechnieken combineerden om zeer nauwkeurige kaarten van overstromings“gevoeligheid” te maken voor een groot en complex rivierbekken in Iran. De ontwikkelde aanpak kan planners en gemeenschappen wereldwijd helpen beter te begrijpen waar toekomstige overstromingen waarschijnlijk zullen toeslaan.
Inzicht in een risicovol rivierbekken
Het onderzoek richt zich op het Grote Karun-rivierbekken in het zuidwesten van Iran, met de grootste rivier van het land en miljoenen mensen, landbouwbedrijven en industrieën. Dit bekken omvat hoge bergen, diepe valleien en laaggelegen vlakten, plus meer dan 40 dammen en een geschiedenis van zware overstromingen, waaronder een verwoestend evenement in 2019. Omdat landschap en klimaat sterk variëren binnen het bekken, is het moeilijk te voorspellen waar water zich tijdens zware buien zal ophopen. De auteurs stelden een rijke set geografische informatie samen over klimaat (neerslag, temperatuur, verdamping, sneeuw), hydrologie (rivieren, dammen, afwateringspatronen), landbedekking (vegetatie, bodem, geologie, stedelijke gebieden) en topografie (hoogte, helling en gerelateerde indexen). Met behulp van satellietgebaseerde overstromingsregisters over 2000–2019 identificeerden ze waar overstromingen daadwerkelijk hadden plaatsgevonden om hun modellen te trainen en te testen.
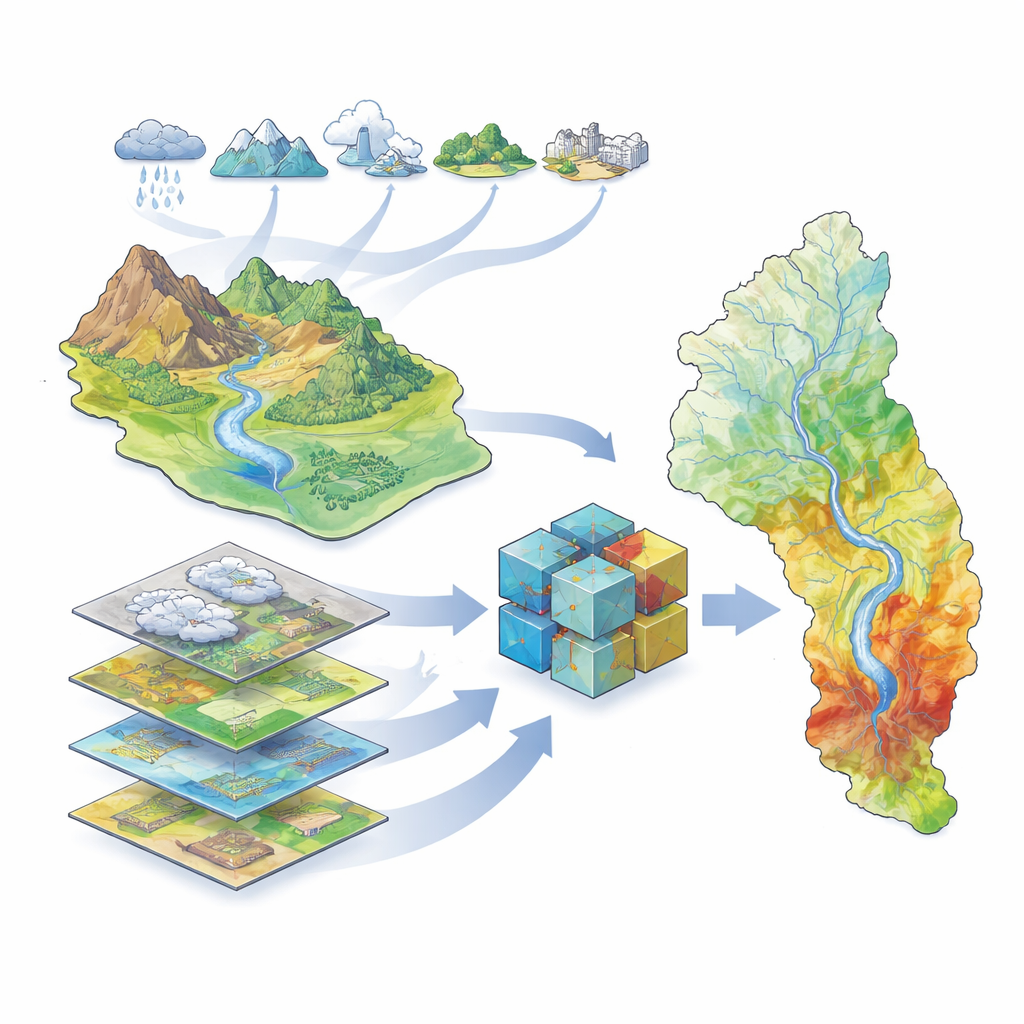
Computers leren overstromingsgevoelige terreinen herkennen
Om deze gegevens om te zetten in overstromingsgevoeligheidskaarten gebruikte het team een reeks machine learning-methoden — computeralgoritmen die patronen uit voorbeelden leren in plaats van vaste vergelijkingen te volgen. Ze trainden vijf verschillende modellen: een traditioneel statistisch model (een gegeneraliseerd lineair model) en vier boomgebaseerde modellen die bijzonder goed omgaan met complexe, niet-lineaire relaties (Decision Tree, Random Forest, XGBoost en LightGBM). Elk model kreeg dezelfde invoer: kaarten die de omgevingsfactoren weergeven en een registratie van welke plaatsen wel en niet waren overstroomd. De algoritmen leerden vervolgens combinaties van factoren te koppelen — bijvoorbeeld laaggelegen land nabij rivieren met weinig vegetatie — aan een hogere kans op overstroming.
Meerdere modellen combineren tot één sterke gids
In plaats van één enkel “beste” model te kiezen, bouwden de onderzoekers een ensemble- of stemmingsmodel dat de kansschattingen van alle vijf basismodellen voor elke locatie in het bekken samenvoegt. In plaats van een eenvoudige ja-of-nee-stem levert elk model een waarschijnlijkheid dat een gegeven pixel overstromingsgevoelig is, en het ensemble berekent het gemiddelde. Deze soft-votingstrategie vermindert de invloed van fouten van individuele modellen en benadrukt locaties waar de verschillende benaderingen overeenkomen. De uiteindelijke output is een continue kaart van overstromingsgevoeligheid, later ingedeeld in vijf intuïtieve klassen van zeer laag tot zeer hoog zodat besluitvormers deze gemakkelijk kunnen interpreteren.
Hoe goed werkte het, en wat is het belangrijkst?
Het ensemblemodel bleek opmerkelijk nauwkeurig. Getest tegen onafhankelijke gegevens onderscheidde het correct overstroomde van niet-overstroomde gebieden met een Area Under the Curve (AUC)-score van 0,994, beter dan elk afzonderlijk model en ver boven wat door toeval verwacht zou worden. Zones met hoge en zeer hoge gevoeligheid kwamen nauw overeen met waargenomen overstromingslocaties, vooral in de benedenliggende vlakten van de provincie Khuzestan. Een analyse van de belangrijkste factoren toonde aan dat afstand tot beken, helling van het terrein en vegetatiedichtheid (gemeten met satellietbeelden) de sterkste voorspellers van overstromingsgevoeligheid waren, met hoogte, afvloeiingsaccumulatie, afstand tot dammen en neerslag als belangrijke secundaire informatie. Simpel gezegd: dicht bij rivieren liggen, op steiler of convergerend terrein staan en weinig dichte vegetatie hebben, vergroot sterk de kans op overstroming.
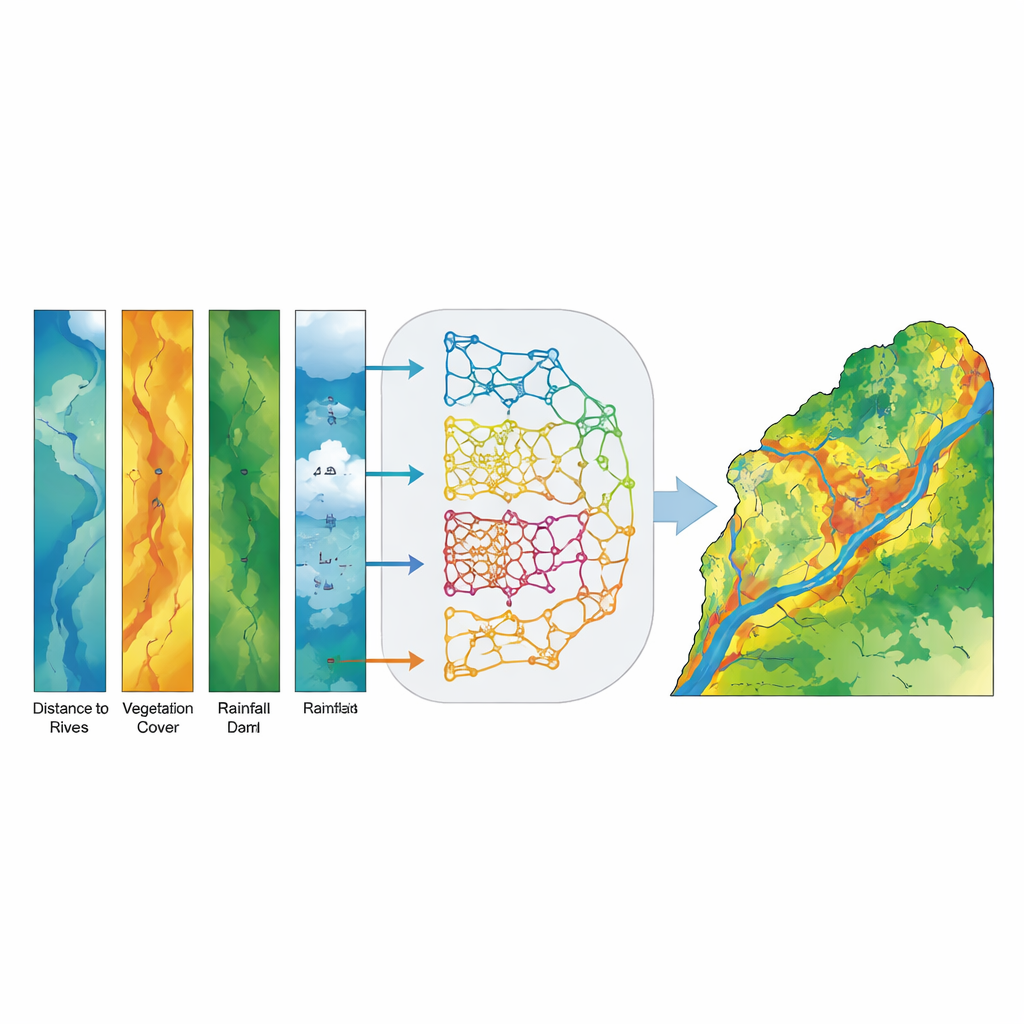
Van kaarten naar actie
Voor een lezer zonder specialistische kennis is de kernboodschap dat deze studie een krachtige manier laat zien om computers ‘te leren’ het landschap te lezen en te bepalen waar overstromingen het meest waarschijnlijk zijn, zelfs in grote gebieden met weinig gegevens. Door satellietregistraties van eerdere overstromingen te combineren met gedetailleerde kaarten van klimaat, terrein, rivieren en landgebruik, en vervolgens meerdere machine learning-modellen te verenigen in één sterker ensemble, produceerden de auteurs zeer betrouwbare overstromingsgevoeligheidskaarten voor het Grote Karun-bekken. Dergelijke kaarten kunnen helpen bij het veiliger plaatsen van woningen en infrastructuur, bij het vormgeven van grondgebruik- en dambeheerbeleid, en bij het ondersteunen van waarschuwing en noodplanning. Omdat de methode grotendeels steunt op wereldwijd beschikbare data en veelgebruikte tools, kan ze worden toegepast in andere rivierbekkens wereldwijd en gemeenschappen helpen schade door overstromingen te voorspellen en te beperken voordat het water stijgt.
Bronvermelding: Rahimi, M., Malekmohammadi, B., Firozjaei, M.K. et al. Integrating geospatial intelligence and machine learning for flood susceptibility mapping. Sci Rep 16, 10228 (2026). https://doi.org/10.1038/s41598-026-41014-3
Trefwoorden: overstromingsgevoeligheidskaarten, machine learning, georuimtelijke gegevens, rivierbekkenbeheer, rampenrisicoreductie