Clear Sky Science · ru
Интеграция геопространственной разведки и машинного обучения для картирования восприимчивости к наводнениям
Почему это важно для людей и территорий
Наводнения — одни из самых разрушительных природных бедствий, и они становятся более частыми и дорогостоящими по мере расширения городов в речные долины и потепления климата. При этом во многих регионах по-прежнему нет детальных и надежных карт, показывающих, какие именно районы наиболее подвержены затоплению. В этом исследовании объясняется, как ученые объединили спутниковые наблюдения, географические данные и продвинутые методы машинного обучения, чтобы создать высокоточные карты «восприимчивости» к наводнениям для большого и сложного бассейна реки в Иране. Разработанный ими подход может помочь планировщикам и сообществам во всем мире лучше понять, где в будущем наиболее вероятны наводнения.
Понимание речного бассейна, находящегося в зоне риска
Исследование сосредоточено на бассейне Великой реки Карун на юго-западе Ирана, где протекает крупнейшая в стране река и проживают миллионы людей, фермы и предприятия. Этот бассейн включает высокие горы, глубокие долины и низменные равнины, а также более 40 плотин и историю тяжелых наводнений, включая разрушительное событие 2019 года. Поскольку рельеф и климат сильно варьируются по бассейну, предсказать, где будет накапливаться вода в сильные ливни, сложно. Авторы собрали богатый набор географической информации, описывающей климат (осадки, температура, испарение, снег), гидрологию (реки, плотины, дренажные паттерны), покров земли (растительность, почвы, геология, урбанизация) и топографию (высота, уклон и родственные индексы). Используя спутниковые данные о наводнениях за 2000–2019 гг., они определили, где на самом деле происходили затопления, чтобы обучить и протестировать свои модели.
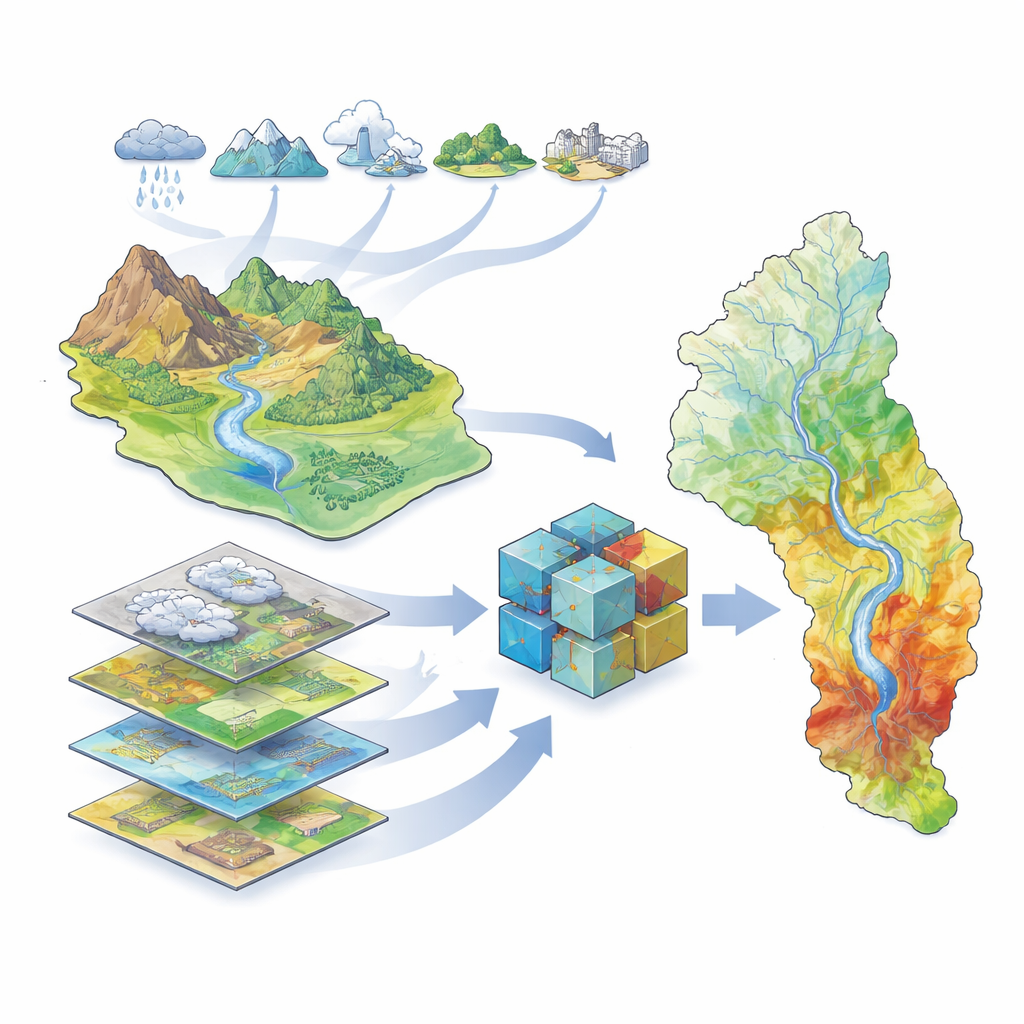
Обучение компьютеров распознавать подверженные наводнениям участки
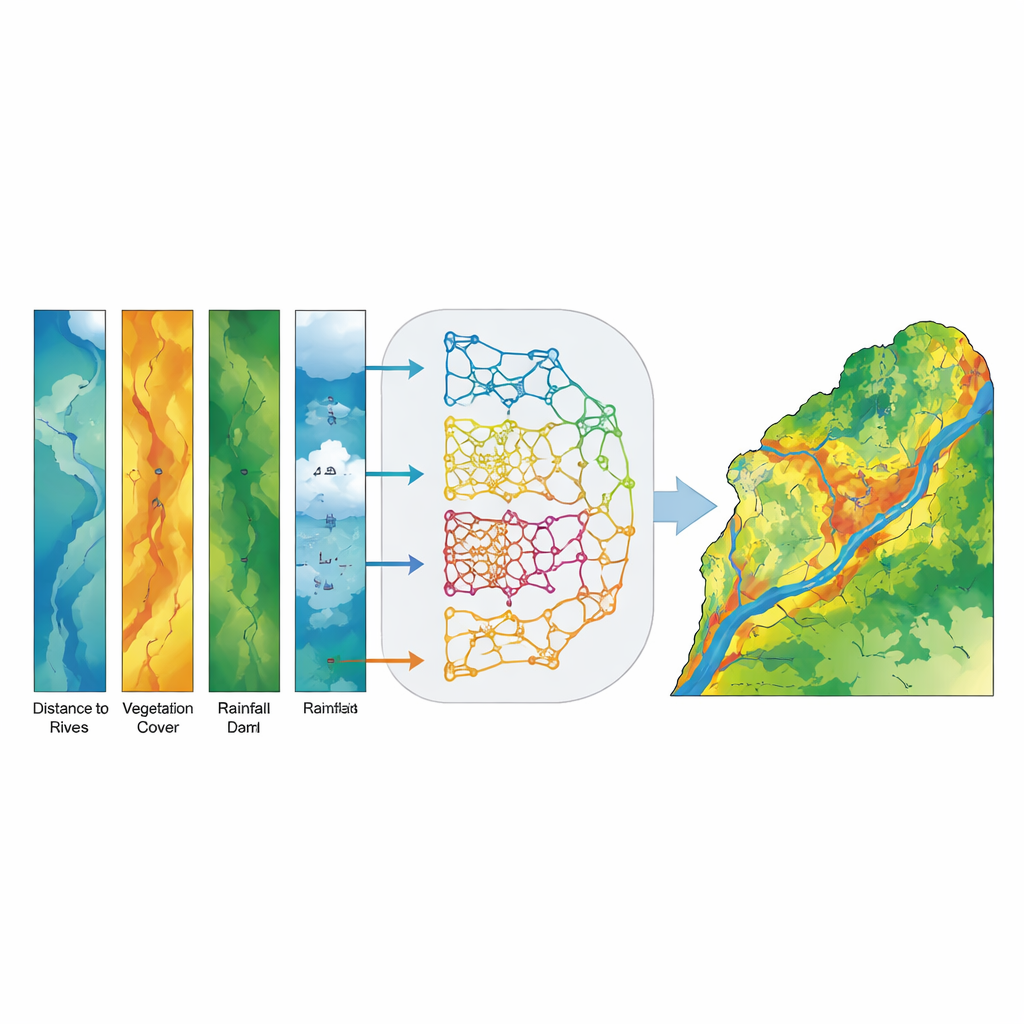
Чтобы превратить эти данные в карты восприимчивости к наводнениям, команда использовала ряд методов машинного обучения — компьютерных алгоритмов, которые выявляют закономерности по примерам, а не следуют фиксированным уравнениям. Они обучили пять различных моделей: традиционную статистическую модель (обобщенную линейную модель) и четыре деревообразные модели, особенно эффективные при работе со сложными нелинейными связями (дерево решений, случайный лес, XGBoost и LightGBM). Каждая модель получила одинаковые входные данные: карты, представляющие экологические факторы, и записи о том, где происходили наводнения, а где нет. Алгоритмы затем научились соотносить сочетания факторов — например, низменные участки возле рек с редкой растительностью — с повышенной вероятностью затопления.
Объединение множества моделей в один мощный инструмент
Вместо того чтобы выбирать одну «лучшую» модель, исследователи создали ансамбль, или модель голосования, которая объединяет оценки вероятности от всех пяти базовых моделей для каждой точки бассейна. Вместо простого «да» или «нет» каждая модель вносит вероятность того, что данный пиксель склонен к затоплению, а ансамбль вычисляет усреднение. Такая стратегия мягкого голосования уменьшает влияние ошибок какой-либо одной модели и выделяет места, где разные подходы сходятся. Конечным выводом является непрерывная карта восприимчивости к наводнениям, которую затем сгруппировали в пять интуитивных классов от очень низкой до очень высокой, чтобы лицам, принимающим решения, было проще интерпретировать результаты.
Насколько это сработало и что имеет наибольшее значение?
Ансамблевая модель оказалась чрезвычайно точной. При проверке на независимых данных она правильно различала затопленные и незатопленные участки с показателем площади под кривой (AUC) 0,994 — лучше, чем любая отдельная модель, и значительно выше случайного совпадения. Зоны высокой и очень высокой восприимчивости тесно соответствовали наблюдаемым местам затоплений, особенно в нижнезападных равнинах провинции Хузестан. Анализ вклада факторов показал, что расстояние до ручьев, уклон поверхности и плотность растительности (измеренная по спутниковым снимкам) являются самыми сильными предикторами восприимчивости к наводнениям, а высота, накопление стока, расстояние до плотин и осадки обеспечивают важную дополнительную информацию. Проще говоря, близость к рекам, расположение на крутых или сходящихся склонах и отсутствие густой растительности существенно увеличивают вероятность затопления.
От карт к действиям
Для неспециалиста главный вывод таков: исследование демонстрирует мощный способ «обучить» компьютеры читать ландшафт и точно указывать, где наводнения наиболее вероятны, даже в больших регионах с ограниченными данными. Объединив спутниковые записи о прошлых наводнениях с детальными картами климата, рельефа, рек и использования земли, а затем объединив несколько моделей машинного обучения в единый более сильный ансамбль, авторы получили высоконадёжные карты восприимчивости к наводнениям для бассейна Великой Карун. Такие карты могут помочь в выборе безопасных мест для жилья и инфраструктуры, формировании политики использования земель и управления плотинами, а также в поддержке системы раннего предупреждения и планирования чрезвычайных ситуаций. Поскольку метод в основном опирается на глобально доступные данные и широко используемые инструменты, его можно перенести в другие речные бассейны по всему миру, помогая сообществам предвидеть и уменьшать ущерб от наводнений до подъема воды.
Цитирование: Rahimi, M., Malekmohammadi, B., Firozjaei, M.K. et al. Integrating geospatial intelligence and machine learning for flood susceptibility mapping. Sci Rep 16, 10228 (2026). https://doi.org/10.1038/s41598-026-41014-3
Ключевые слова: картирование восприимчивости к наводнениям, машинное обучение, геопространственные данные, управление речным бассейном, снижение риска бедствий