Clear Sky Science · it
Integrazione di intelligence geospaziale e apprendimento automatico per la mappatura della suscettibilità alle inondazioni
Perché è importante per persone e luoghi
Le inondazioni sono tra i disastri naturali più distruttivi e stanno diventando più frequenti e costose man mano che le città si espandono nelle valli fluviali e il clima si riscalda. Tuttavia molte regioni mancano ancora di mappe dettagliate e affidabili che mostrino esattamente quali aree sono più soggette a inondazioni. Questo studio spiega come gli scienziati hanno combinato osservazioni satellitari, dati geografici e tecniche avanzate di apprendimento computazionale per creare mappe della “suscettibilità” alle inondazioni altamente accurate per un ampio e complesso bacino fluviale in Iran. L’approccio sviluppato potrebbe aiutare pianificatori e comunità in tutto il mondo a comprendere meglio dove è più probabile che si verifichino future inondazioni.
Comprendere un bacino fluviale a rischio
La ricerca si concentra sul grande bacino del fiume Karun nel sud-ovest dell’Iran, che ospita il fiume più grande del paese e milioni di persone, aziende agricole e industrie. Questo bacino comprende alte montagne, profonde valli e pianure di bassa quota, insieme a più di 40 dighe e una storia di inondazioni gravi, compreso un evento distruttivo nel 2019. Poiché il paesaggio e il clima variano molto all’interno del bacino, prevedere dove l’acqua si accumulerà durante forti tempeste è una sfida. Gli autori hanno assemblato un ricco insieme di informazioni geografiche descrivendo il clima (pioggia, temperatura, evaporazione, neve), l’idrologia (fiumi, dighe, modelli di drenaggio), la copertura del suolo (vegetazione, suolo, geologia, aree urbane) e la topografia (elevazione, pendenza e indici correlati). Utilizzando registri satellitari delle inondazioni coprenti il periodo 2000–2019, hanno identificato dove le inondazioni si erano effettivamente verificate per addestrare e testare i loro modelli.
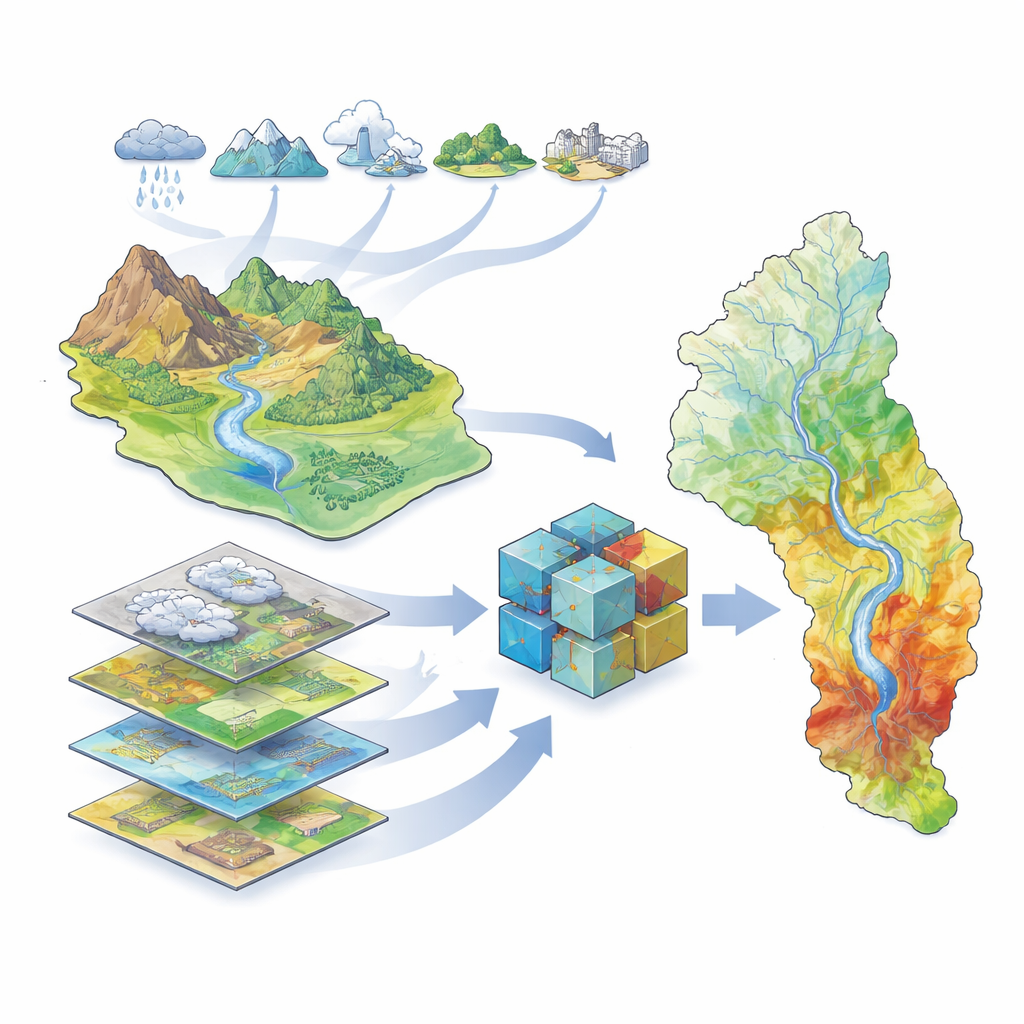
Insegnare ai computer a riconoscere le aree a rischio di inondazione
Per trasformare questi dati in mappe di suscettibilità, il team ha utilizzato una famiglia di metodi di apprendimento automatico — algoritmi che apprendono modelli dagli esempi invece di seguire equazioni fisse. Hanno addestrato cinque modelli differenti: un modello statistico tradizionale (chiamato modello lineare generalizzato) e quattro modelli basati su alberi particolarmente abili a gestire relazioni complesse e non lineari (Decision Tree, Random Forest, XGBoost e LightGBM). Ogni modello ha ricevuto gli stessi input: mappe che rappresentano i fattori ambientali e un registro dei luoghi che erano stati inondati e di quelli che non lo erano. Gli algoritmi hanno quindi imparato ad associare combinazioni di fattori — per esempio aree di bassa quota vicino ai fiumi con vegetazione rada — a una maggiore probabilità di inondazione.
Combinare molti modelli in una guida affidabile
Invece di scegliere un singolo modello “migliore”, i ricercatori hanno costruito un ensemble, o modello a voto, che fonde le stime di probabilità provenienti da tutti e cinque i modelli di base per ogni posizione nel bacino. Piuttosto che emettere un semplice voto sì/no, ogni modello contribuisce con una probabilità che un dato pixel sia soggetto a inondazione e l’ensemble calcola una media. Questa strategia di soft-voting riduce l’influenza degli errori di un singolo modello e valorizza le località dove i diversi approcci concordano. L’output finale è una mappa continua di suscettibilità alle inondazioni, poi raggruppata in cinque classi intuitive da molto bassa a molto alta in modo che i decisori possano interpretarla facilmente.
Quanto ha funzionato e cosa conta di più?
Il modello ensemble si è dimostrato straordinariamente accurato. Quando testato su dati indipendenti, ha correttamente distinto le aree inondate da quelle non inondate con un punteggio Area Under the Curve (AUC) di 0,994, migliore di qualsiasi modello individuale e molto al di sopra di quanto ci si aspetterebbe per caso. Le zone a suscettibilità alta e molto alta corrispondevano strettamente ai luoghi di inondazione osservati, soprattutto nelle pianure a valle della provincia del Khuzestan. Un’analisi dei fattori più importanti ha mostrato che la distanza dai corsi d’acqua, la pendenza del terreno e la densità della vegetazione (misurata dalle immagini satellitari) erano i predittori più forti della suscettibilità alle inondazioni, con elevazione, accumulo di deflusso, distanza dalle dighe e precipitazioni che fornivano informazioni secondarie rilevanti. In termini più semplici, essere vicino ai fiumi, trovarsi su terreni più ripidi o convergenti e mancare di una vegetazione fitta aumenta notevolmente la probabilità che un’area venga inondata.
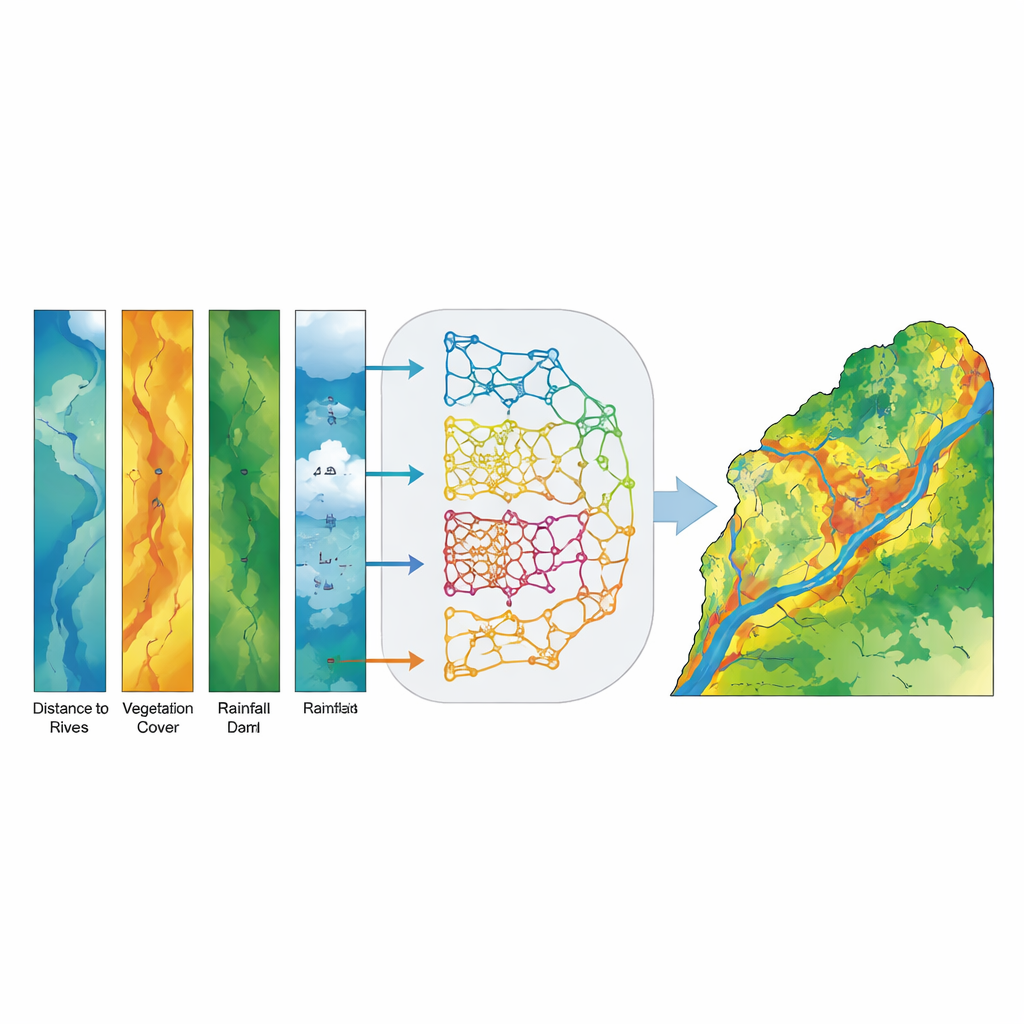
Dalle mappe all’azione
Per un lettore non specialista, la conclusione è che questo studio dimostra un modo potente per “insegnare” ai computer a leggere il paesaggio e individuare dove le inondazioni sono più probabili, anche in regioni vaste e con pochi dati. Integrando registri satellitari di inondazioni passate con mappe dettagliate di clima, terreno, fiumi e uso del suolo, e combinando poi diversi modelli di apprendimento automatico in un unico ensemble più robusto, gli autori hanno prodotto mappe della suscettibilità alle inondazioni altamente affidabili per il bacino del Grande Karun. Tali mappe possono orientare l’ubicazione più sicura di abitazioni e infrastrutture, modellare politiche di uso del territorio e gestione delle dighe, e supportare allerta precoce e pianificazione delle emergenze. Poiché il metodo si basa principalmente su dati disponibili a livello globale e su strumenti di uso diffuso, può essere trasferito ad altri bacini fluviali nel mondo, aiutando le comunità ad anticipare e ridurre i danni da inondazione prima che le acque crescano.
Citazione: Rahimi, M., Malekmohammadi, B., Firozjaei, M.K. et al. Integrating geospatial intelligence and machine learning for flood susceptibility mapping. Sci Rep 16, 10228 (2026). https://doi.org/10.1038/s41598-026-41014-3
Parole chiave: mappatura della suscettibilità alle inondazioni, apprendimento automatico, dati geospaziali, gestione dei bacini fluviali, riduzione del rischio di disastri