Clear Sky Science · sv
Integrering av geospatial underrättelse och maskininlärning för översvämningskänslighetskartering
Varför detta är viktigt för människor och platser
Översvämningar är bland de mest förödande naturkatastroferna, och de blir både vanligare och dyrare i takt med att städer breder ut sig i floddalar och klimatet blir varmare. Ändå saknar många regioner fortfarande detaljerade, tillförlitliga kartor som visar exakt vilka områden som är mest utsatta. Denna studie förklarar hur forskare kombinerade satellitobservationer, geografiska data och avancerade datorinlärningstekniker för att skapa mycket precisa kartor över översvämnings"känslighet" för ett stort och komplext vattendrag i Iran. Den metod de utvecklade kan hjälpa planerare och samhällen världen över att bättre förstå var framtida översvämningar sannolikt kommer att drabba.
Att förstå ett vattendrag i riskzonen
Forskningen fokuserar på det stora Karun-vattendragets avrinningsområde i sydvästra Iran, hem för landets största flod och för miljontals människor, jordbruk och industrier. Detta avrinningsområde omfattar höga berg, djupa dalar och lågt liggande slätter, tillsammans med mer än 40 dammar och en historia av svåra översvämningar, inklusive en förödande händelse 2019. Eftersom landskapet och klimatet varierar starkt över området är det svårt att förutsäga var vatten kommer att samlas vid kraftiga skyfall. Författarna samlade ett rikt utbud av geografisk information som beskriver klimat (regn, temperatur, avdunstning, snö), hydrologi (floder, dammar, dräneringsmönster), markanvändning (vegetation, jord, geologi, tätorter) och topografi (höjd, lutning och relaterade index). Med hjälp av satellitbaserade översvämningsdata för perioden 2000–2019 identifierade de var översvämningar faktiskt hade inträffat för att träna och testa sina modeller.
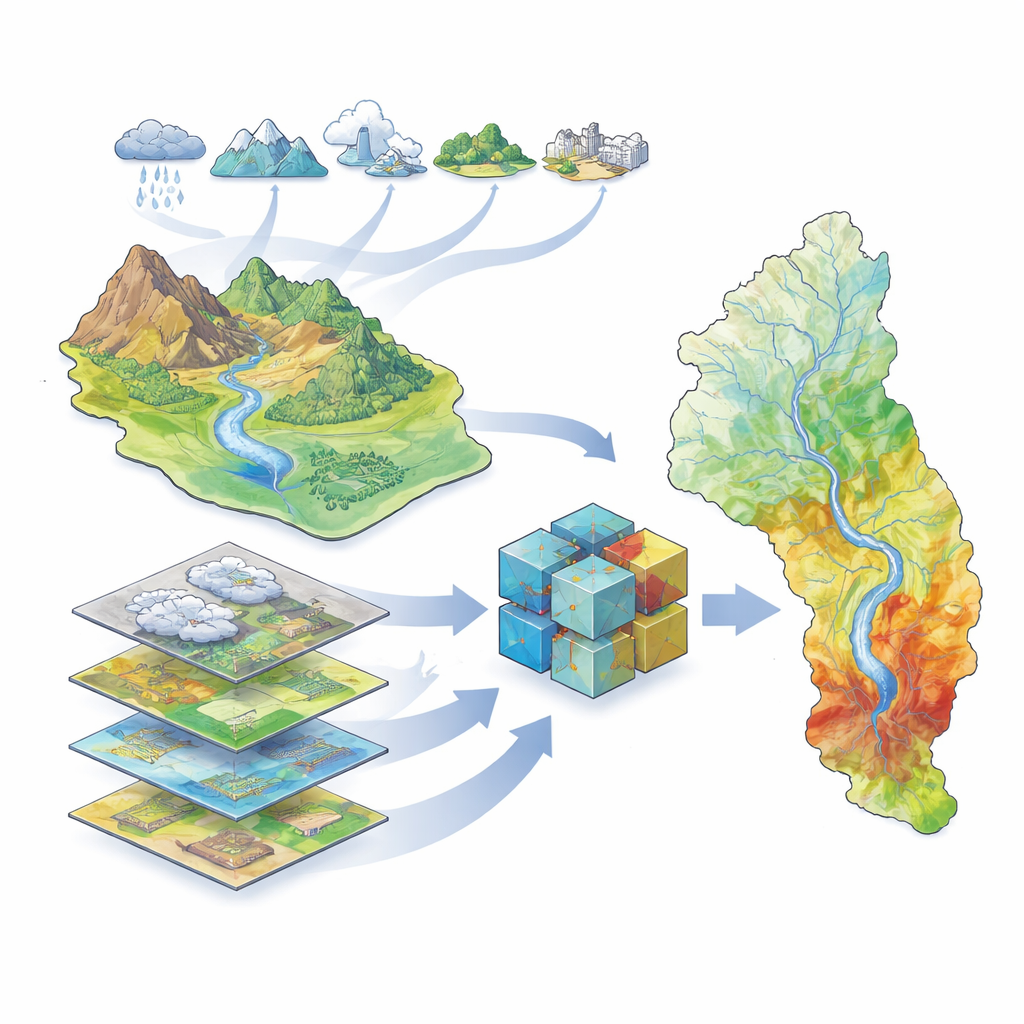
Att lära datorer känna igen översvämningsutsatt mark
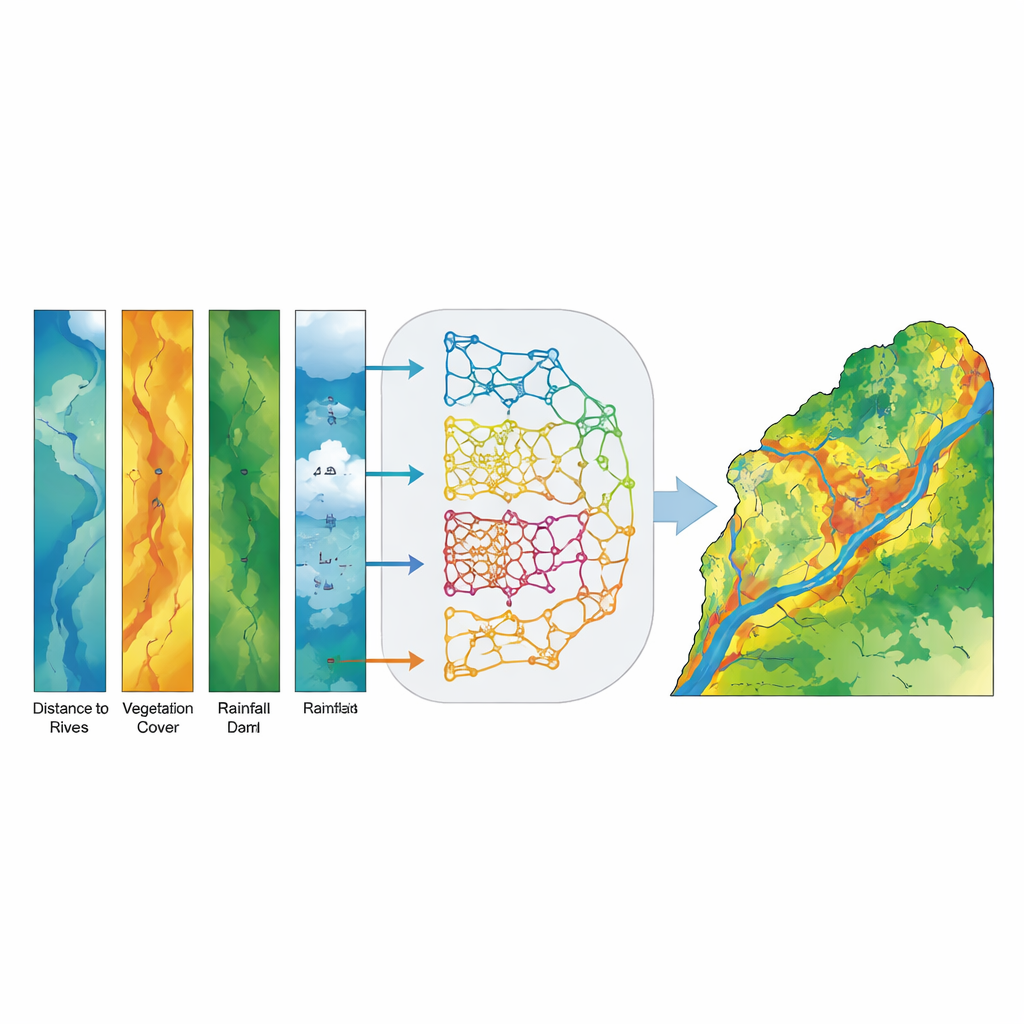
För att omvandla dessa data till kartor över översvämningskänslighet använde teamet en familj av maskininlärningsmetoder—datoralgoritmer som lär sig mönster från exempel snarare än att följa fasta ekvationer. De tränade fem olika modeller: en traditionell statistisk modell (kallad generaliserad linjär modell) och fyra träd-baserade modeller som är särskilt bra på att hantera komplexa, icke-linjära samband (Decision Tree, Random Forest, XGBoost och LightGBM). Varje modell fick samma indata: kartor som representerar miljöfaktorerna och en förteckning över vilka platser som hade översvämmats och vilka som inte hade det. Algoritmerna lärde sig sedan att koppla samman kombinationer av faktorer—till exempel lågt liggande mark nära floder med gles vegetation—med en högre sannolikhet för översvämning.
Att kombinera många modeller till en stark vägledning
I stället för att välja en enda "bästa" modell byggde forskarna ett ensemble- eller röstningssystem som blandar sannolikhetsuppskattningarna från alla fem basmodeller för varje plats i avrinningsområdet. I stället för att lämna en enkel ja-eller-nej-röst bidrar varje modell med en sannolikhet för att en viss pixel är översvämningsbenägen, och ensemblet beräknar ett medelvärde. Denna "mjuk" röstningsstrategi minskar påverkan från fel i en enskild modell och betonar platser där de olika angreppssätten är överens. Slutresultatet är en kontinuerlig karta över översvämningskänslighet, som senare grupperas i fem intuitiva klasser från mycket låg till mycket hög så att beslutsfattare lätt kan tolka den.
Hur väl fungerade det, och vad betydde mest?
Ensemblemodellen visade sig vara anmärkningsvärt träffsäker. När den testades mot oberoende data skilde den korrekt mellan översvämmade och icke-översvämmade områden med ett Area Under the Curve (AUC)-värde på 0,994, bättre än någon enskild modell och långt bättre än slumpen. Zoner med hög och mycket hög känslighet överensstämde väl med observerade översvämningsplatser, särskilt i de nedströms slätterna i Khuzestan-provinsen. En analys av vilka faktorer som spelade störst roll visade att avstånd till vattendrag, marklutning och vegetationstäthet (mätt från satellitbilder) var de starkaste indikatorerna på översvämningskänslighet, medan höjd, flödesackumulering, avstånd till dammar och nederbörd gav viktig sekundär information. Enkelt uttryckt ökar närhet till floder, brantare eller konvergerande terräng och brist på tät vegetation kraftigt chansen att ett område översvämmas.
Från kartor till handling
För en lekman är slutsatsen att denna studie visar ett kraftfullt sätt att "lära" datorer att läsa landskapet och identifiera var översvämningar är mest sannolika, även i stora regioner med begränsade data. Genom att förena satellitregister över tidigare översvämningar med detaljerade kartor över klimat, terräng, floder och markanvändning, och därefter kombinera flera maskininlärningsmodeller till ett enda, starkare ensemble, producerade författarna mycket tillförlitliga kartor över översvämningskänslighet för det stora Karun-avrinningsområdet. Sådana kartor kan vägleda säkrare placering av bostäder och infrastruktur, forma markanvändnings- och dammförvaltningspolicyer samt stödja tidiga varningar och beredskapsplanering. Eftersom metoden främst bygger på globalt tillgängliga data och vida använda verktyg kan den överföras till andra vattendrag världen över, och hjälpa samhällen att förutse och minska översvämningsskador innan vattnet stiger.
Citering: Rahimi, M., Malekmohammadi, B., Firozjaei, M.K. et al. Integrating geospatial intelligence and machine learning for flood susceptibility mapping. Sci Rep 16, 10228 (2026). https://doi.org/10.1038/s41598-026-41014-3
Nyckelord: översvämningskänslighetskartering, maskininlärning, geospatiala data, vattendragsförvaltning, katastrofriskreducering