Clear Sky Science · pl
Integracja wywiadu geoprzestrzennego i uczenia maszynowego w mapowaniu podatności na powodzie
Dlaczego to ważne dla ludzi i miejsc
Powodzie należą do najbardziej niszczycielskich katastrof naturalnych i stają się częstsze oraz kosztowniejsze, gdy miasta rozrastają się w dolinach rzecznych, a klimat się ociepla. Jednak w wielu regionach wciąż brakuje szczegółowych, wiarygodnych map pokazujących, które obszary są najbardziej narażone na zalanie. W tym badaniu wyjaśniono, jak naukowcy połączyli obserwacje satelitarne, dane geograficzne i zaawansowane metody uczenia komputerowego, aby stworzyć wysoce precyzyjne mapy „podatności” na powodzie dla dużego i złożonego dorzecza w Iranie. Opracowane podejście może pomóc planistom i społecznościom na całym świecie lepiej zrozumieć, gdzie przyszłe powodzie najprawdopodobniej wystąpią.
Zrozumienie dorzecza zagrożonego powodziami
Badania koncentrują się na dorzeczu Wielkiej Karun w południowo-zachodnim Iranie, obejmującym największą rzekę kraju oraz miliony mieszkańców, gospodarstw i zakładów przemysłowych. Dorzecze to zawiera wysokie góry, głębokie doliny i nizinne równiny, a także ponad 40 tam oraz historię poważnych powodzi, w tym niszczycielskie zdarzenie z 2019 roku. Ponieważ krajobraz i klimat znacznie się różnią w obrębie dorzecza, przewidywanie miejsc, w których woda będzie się gromadzić podczas intensywnych opadów, jest trudne. Autorzy zgromadzili bogaty zestaw informacji geograficznych opisujących klimat (opady, temperaturę, parowanie, śnieg), hydrologię (rzeki, tamy, systemy odwadniające), pokrycie terenu (roślinność, gleba, geologia, obszary miejskie) oraz topografię (wysokość, nachylenie i powiązane wskaźniki). Wykorzystując satelitarne zapisy powodzi obejmujące lata 2000–2019, zidentyfikowali miejsca, w których powodzie rzeczywiście wystąpiły, aby trenować i testować swoje modele.
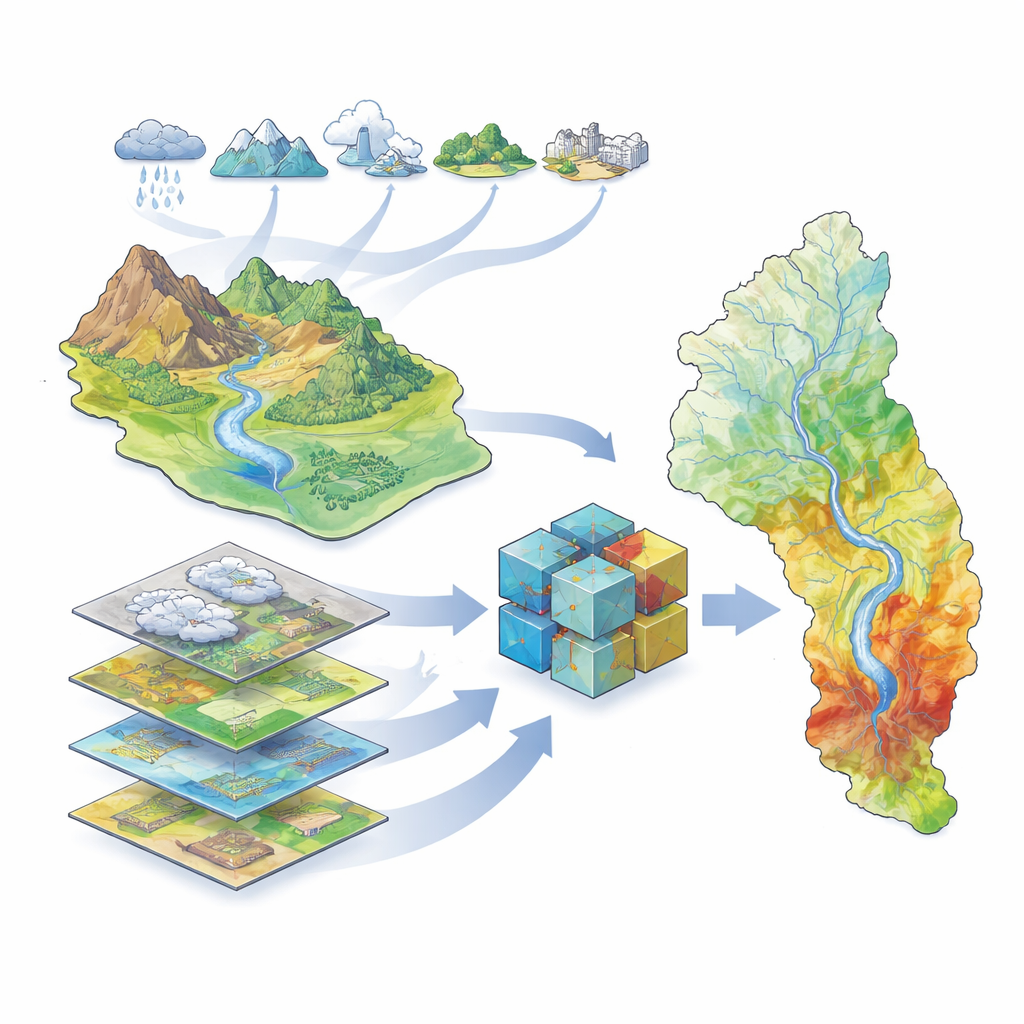
Nauczanie komputerów rozpoznawania terenów podatnych na powodzie
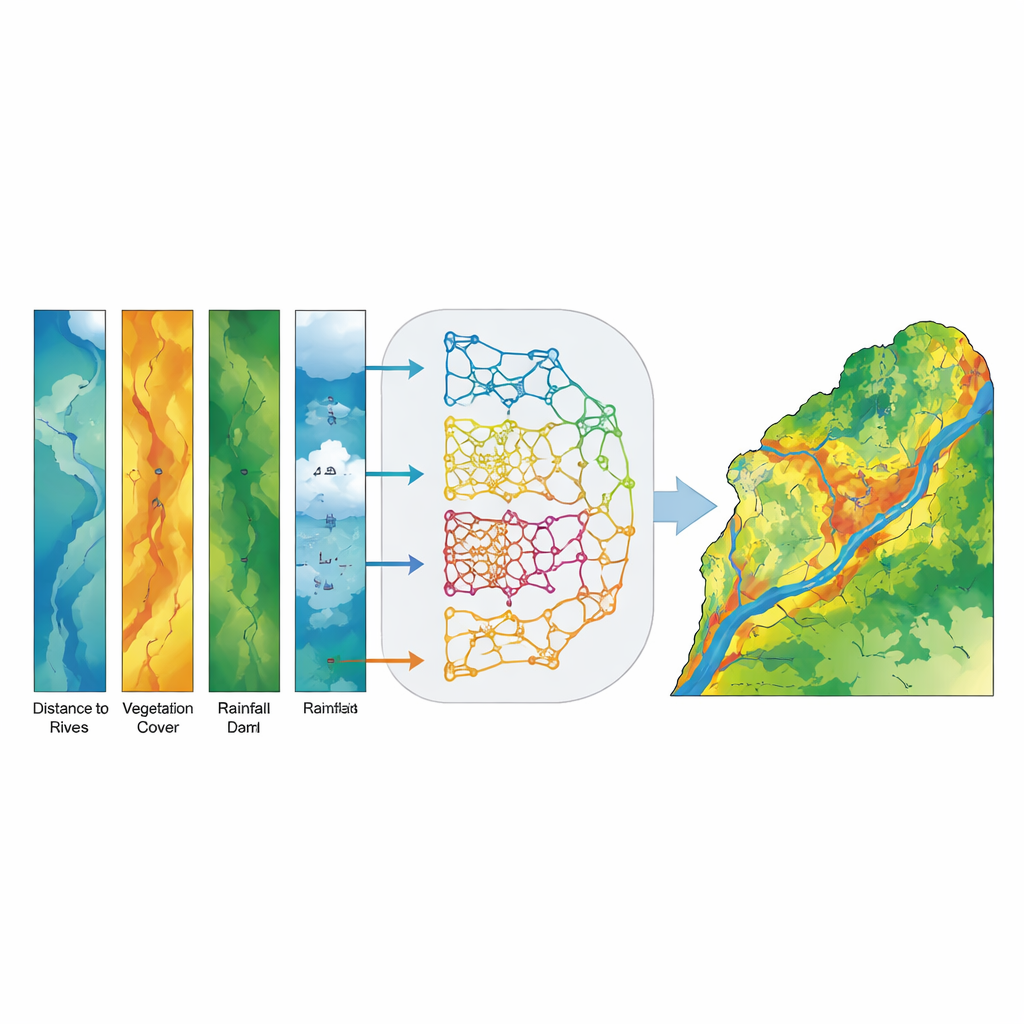
Aby przekształcić te dane w mapy podatności na powodzie, zespół zastosował zestaw metod uczenia maszynowego — algorytmów komputerowych, które uczą się wzorców na podstawie przykładów zamiast używać stałych równań. Wyszkolili pięć różnych modeli: tradycyjny model statystyczny (zwany uogólnionym modelem liniowym) oraz cztery modele oparte na drzewach, które szczególnie dobrze radzą sobie ze złożonymi, nieliniowymi zależnościami (Drzewo decyzyjne, Random Forest, XGBoost i LightGBM). Każdy model otrzymał te same dane wejściowe: mapy przedstawiające czynniki środowiskowe oraz zapis miejsc, które zostały zalane i które nie. Algorytmy nauczyły się kojarzyć kombinacje czynników — na przykład tereny nisko położone w pobliżu rzek z rzadką roślinnością — z wyższym prawdopodobieństwem wystąpienia powodzi.
Łączenie wielu modeli w jeden mocny przewodnik
Zamiast wybierać pojedynczy „najlepszy” model, badacze zbudowali model zespołowy (ensemble), który łączy prognozy prawdopodobieństwa ze wszystkich pięciu modeli bazowych dla każdej lokalizacji w dorzeczu. Zamiast prostego głosowania tak/nie, każdy model wnosi prawdopodobieństwo, że dany piksel jest podatny na powódź, a model zespołowy oblicza średnią. Taka strategia miękkiego głosowania zmniejsza wpływ błędów poszczególnych modeli i uwydatnia miejsca, gdzie różne podejścia się zgadzają. Końcowym produktem jest ciągła mapa podatności na powodzie, następnie podzielona na pięć czytelnych klas od bardzo niskiej do bardzo wysokiej, aby decydenci mogli ją łatwo interpretować.
Jak dobrze to działało i co ma największe znaczenie?
Model zespołowy okazał się niezwykle dokładny. Testowany na niezależnych danych poprawnie rozróżniał obszary zalane od niezagrożonych z wynikiem Area Under the Curve (AUC) równym 0,994, co przewyższało każdy pojedynczy model i było znacznie lepsze niż oczekiwanie losowe. Strefy o wysokiej i bardzo wysokiej podatności dobrze pokrywały się z obserwowanymi miejscami powodzi, szczególnie na nizinnym odcinku w prowincji Chuzestan. Analiza wpływu poszczególnych czynników wykazała, że najważniejszymi predyktorami podatności na powodzie były odległość od cieków wodnych, nachylenie terenu i gęstość roślinności (mierzone z obrazów satelitarnych), podczas gdy wysokość, akumulacja przepływu, odległość od tam i opady dostarczały istotnych informacji wtórnych. Mówiąc prościej: bliskość rzek, położenie na stromszym lub zbiegającym się terenie oraz brak gęstej roślinności znacząco zwiększają prawdopodobieństwo zalania obszaru.
Od map do działania
Dla laika najważniejsze jest to, że badanie pokazuje potężny sposób „nauczania” komputerów czytania krajobrazu i wskazywania miejsc, gdzie powodzie są najbardziej prawdopodobne, nawet w dużych regionach ubogich w dane. Poprzez scalenie satelitarnych zapisów przeszłych powodzi z szczegółowymi mapami klimatu, terenu, rzek i użytkowania ziemi, a następnie połączenie kilku modeli uczenia maszynowego w jeden, silniejszy zespół, autorzy uzyskali wysoce wiarygodne mapy podatności na powodzie dla dorzecza Wielkiej Karun. Takie mapy mogą wskazywać bezpieczniejsze lokalizacje dla domów i infrastruktury, kształtować politykę użytkowania ziemi i zarządzania tamami oraz wspierać systemy ostrzegania i planowanie awaryjne. Ponieważ metoda opiera się głównie na globalnie dostępnych danych i powszechnie używanych narzędziach, można ją przenieść do innych dorzeczy na świecie, pomagając społecznościom przewidywać i ograniczać szkody powodziowe, zanim wody nadejdą.
Cytowanie: Rahimi, M., Malekmohammadi, B., Firozjaei, M.K. et al. Integrating geospatial intelligence and machine learning for flood susceptibility mapping. Sci Rep 16, 10228 (2026). https://doi.org/10.1038/s41598-026-41014-3
Słowa kluczowe: mapowanie podatności na powodzie, uczenie maszynowe, dane geoprzestrzenne, zarządzanie dorzeczem, redukcja ryzyka katastrof