Clear Sky Science · de
Integration von Geoinformationsdiensten und maschinellem Lernen für Karten zur Überschwemmungsanfälligkeit
Warum das für Menschen und Orte wichtig ist
Überschwemmungen gehören zu den schädlichsten Naturkatastrophen und treten immer häufiger und mit größeren Kosten auf, da Städte in Flusstäler vordringen und sich das Klima erwärmt. Trotzdem fehlen in vielen Regionen noch detaillierte, verlässliche Karten, die zeigen, welche Gebiete am stärksten gefährdet sind. Diese Studie erläutert, wie Forschende Satellitenbeobachtungen, geografische Daten und fortgeschrittene Computerlernverfahren kombinierten, um hochpräzise Karten der Überschwemmungs„anfälligkeit“ für ein großes und komplexes Flusseinzugsgebiet im Iran zu erstellen. Der entwickelte Ansatz könnte Planerinnen und Gemeinschaften weltweit helfen, besser zu verstehen, wo zukünftige Überschwemmungen am wahrscheinlichsten auftreten.
Ein gefährdetes Flusseinzugsgebiet verstehen
Die Forschung konzentriert sich auf das Große Karun-Einzugsgebiet im Südwesten Irans, Heimat des größten Flusses des Landes und von Millionen Menschen, landwirtschaftlichen Betrieben und Industrien. Das Becken umfasst hohe Berge, tiefe Täler und tiefliegende Ebenen, darüber hinaus mehr als 40 Staudämme und eine Geschichte schwerer Überschwemmungen, einschließlich eines zerstörerischen Ereignisses im Jahr 2019. Weil sich Landschaft und Klima im Becken stark unterscheiden, ist es schwierig vorherzusagen, wo sich bei heftigen Stürmen Wasser ansammelt. Die Autorinnen und Autoren stellten einen umfangreichen Satz geografischer Informationen zusammen, der Klima (Niederschlag, Temperatur, Verdunstung, Schnee), Hydrologie (Flüsse, Dämme, Entwässerungsmuster), Landbedeckung (Vegetation, Boden, Geologie, Siedlungsflächen) und Topografie (Höhe, Hangneigung und verwandte Indizes) beschreibt. Mithilfe satellitengestützter Überschwemmungsaufzeichnungen für 2000–2019 identifizierten sie, wo tatsächlich überflutet wurde, um ihre Modelle zu trainieren und zu testen.
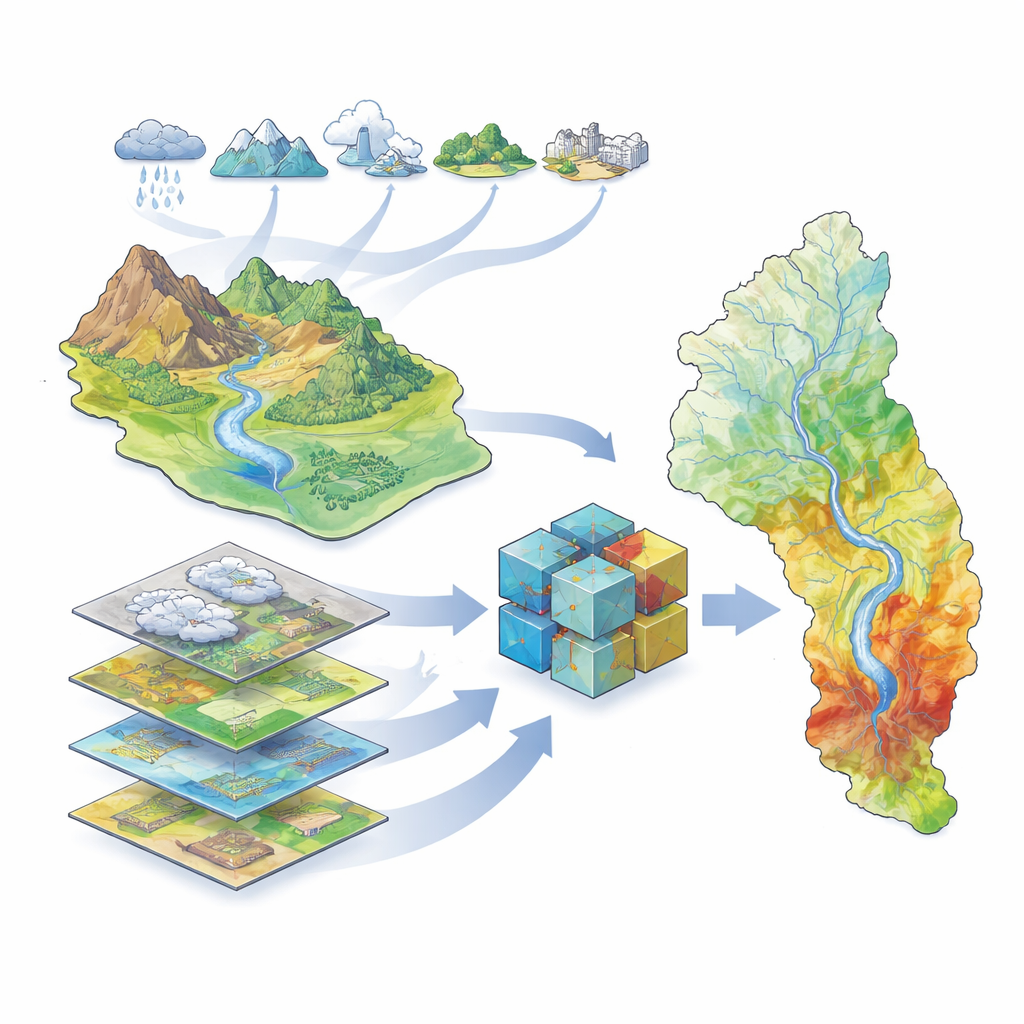
Computern beibringen, überschwemmungsgefährdete Flächen zu erkennen
Um diese Daten in Karten der Überschwemmungsanfälligkeit zu verwandeln, nutzte das Team eine Reihe von Methoden des maschinellen Lernens — Computeralgorithmen, die Muster aus Beispielen lernen, anstatt festen Gleichungen zu folgen. Sie trainierten fünf verschiedene Modelle: ein traditionelles statistisches Modell (ein generalisiertes lineares Modell) und vier baumbasierte Modelle, die besonders gut mit komplexen, nichtlinearen Zusammenhängen umgehen können (Decision Tree, Random Forest, XGBoost und LightGBM). Jedes Modell erhielt dieselben Eingaben: Karten der Umweltfaktoren und eine Aufzeichnung, welche Orte überschwemmt waren und welche nicht. Die Algorithmen lernten dann, Kombinationen von Faktoren — zum Beispiel tiefliegendes Land in Flussnähe mit spärlicher Vegetation — mit einer höheren Überschwemmungswahrscheinlichkeit zu verknüpfen.
Viele Modelle zu einem starken Leitfaden kombinieren
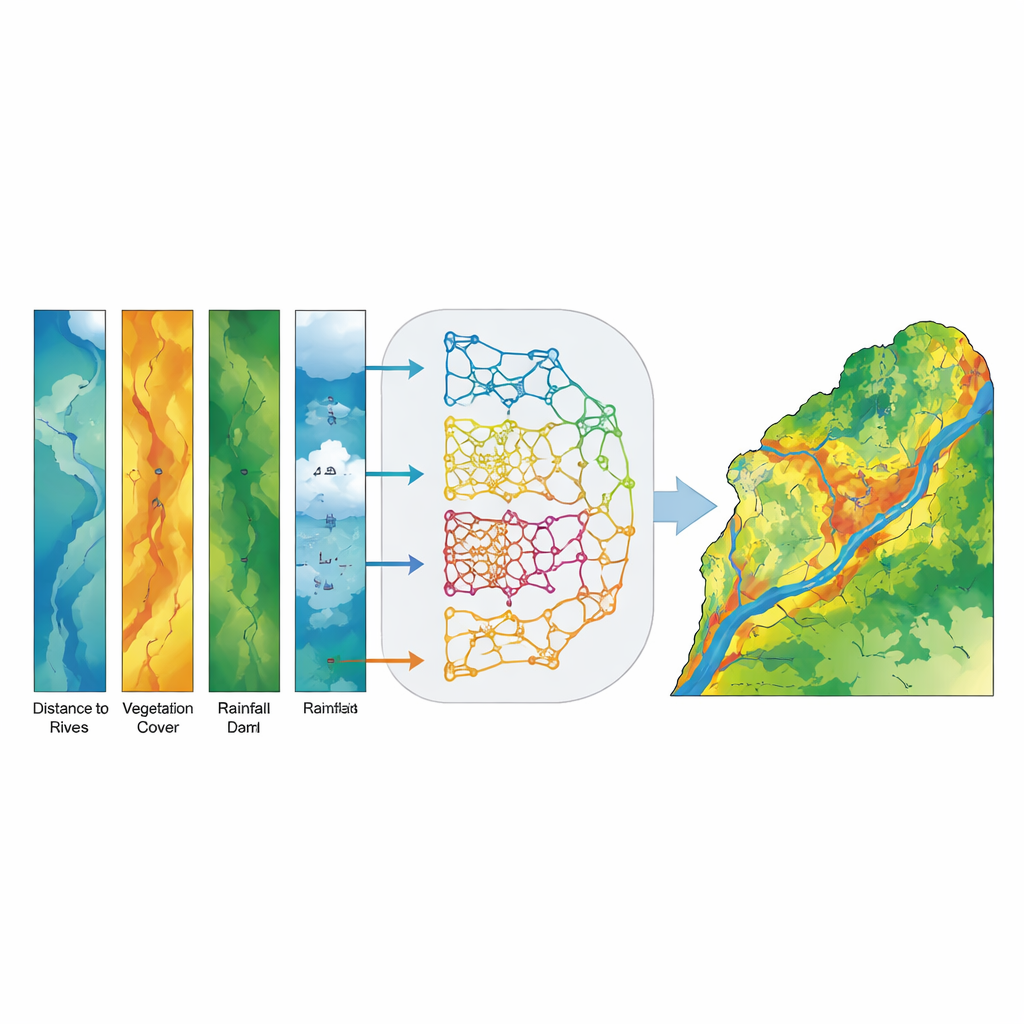
Statt ein einzelnes „bestes“ Modell auszuwählen, bauten die Forschenden ein Ensemble- bzw. Abstimmungsmodell, das die Wahrscheinlichkeitsabschätzungen aller fünf Basismodelle für jeden Ort im Becken miteinander vermischt. Anstatt einer einfachen Ja‑/Nein‑Stimme trägt jedes Modell eine Wahrscheinlichkeit dafür bei, dass ein bestimmtes Pixel überschwemmungsgefährdet ist, und das Ensemble berechnet einen Durchschnitt. Diese Soft‑Voting‑Strategie verringert den Einfluss von Fehlern eines einzelnen Modells und betont Orte, an denen die verschiedenen Ansätze übereinstimmen. Das Endergebnis ist eine stetige Karte der Überschwemmungsanfälligkeit, die später in fünf intuitive Klassen von sehr niedrig bis sehr hoch unterteilt wurde, damit Entscheidungsträger sie leicht interpretieren können.
Wie gut funktionierte es und was ist am wichtigsten?
Das Ensemble-Modell erwies sich als bemerkenswert genau. Getestet an unabhängigen Daten unterschied es korrekt überflutete von nicht überfluteten Flächen mit einer Area Under the Curve (AUC) von 0,994 — besser als jedes einzelne Modell und weit über dem, was durch Zufall zu erwarten wäre. Gebiete mit hoher und sehr hoher Anfälligkeit stimmten eng mit beobachteten Überschwemmungsorten überein, insbesondere in den tieferliegenden Ebenen der Provinz Khuzestan. Eine Analyse der einflussreichsten Faktoren zeigte, dass die Entfernung zu Gewässern, die Hangneigung und die Vegetationsdichte (gemessen an Satellitenbildern) die stärksten Prädiktoren für Überschwemmungsanfälligkeit waren; Höhe, Abflussakkumulation, Entfernung zu Dämmen und Niederschlag lieferten wichtige sekundäre Informationen. Einfach gesagt: Nähe zu Flüssen, steilere oder zusammenlaufende Geländeformen und fehlende dichte Vegetation erhöhen deutlich die Wahrscheinlichkeit einer Überschwemmung.
Von Karten zur Praxis
Für Laien lautet die Quintessenz, dass diese Studie einen leistungsfähigen Weg zeigt, Computern beizubringen, die Landschaft zu „lesen“ und genau zu lokalisieren, wo Überschwemmungen am wahrscheinlichsten sind — selbst in großen, datenarmen Regionen. Durch die Verschmelzung satellitengestützter Aufzeichnungen vergangener Überschwemmungen mit detaillierten Karten zu Klima, Gelände, Flüssen und Landnutzung und durch die Kombination mehrerer Modelle des maschinellen Lernens zu einem stärkeren Ensemble erzeugten die Autorinnen und Autoren sehr verlässliche Karten der Überschwemmungsanfälligkeit für das Große Karun-Becken. Solche Karten können bei der sicheren Standortwahl von Wohn- und Infrastrukturprojekten helfen, die Landnutzungs- und Dammmanagementpolitik beeinflussen sowie Frühwarn- und Notfallplanung unterstützen. Da die Methode hauptsächlich auf global verfügbaren Daten und weit verbreiteten Werkzeugen beruht, lässt sie sich auf andere Flusseinzugsgebiete weltweit übertragen und hilft Gemeinschaften, Überschwemmungsschäden zu antizipieren und zu verringern, bevor das Wasser steigt.
Zitation: Rahimi, M., Malekmohammadi, B., Firozjaei, M.K. et al. Integrating geospatial intelligence and machine learning for flood susceptibility mapping. Sci Rep 16, 10228 (2026). https://doi.org/10.1038/s41598-026-41014-3
Schlüsselwörter: Kartierung der Überschwemmungsanfälligkeit, maschinelles Lernen, geodaten, Flusseinzugsgebietsmanagement, Katastrophenvorsorge