Clear Sky Science · zh
基于解剖上下文的深度学习用于糖尿病视网膜病变眼底图像中准确的中心凹分割
在糖尿病眼中识别危险
对于数以百万计的糖尿病患者而言,位于视网膜正中心的一小块区域——中心凹——可能决定清晰视力与永久性视力丧失之间的差别。医生已经使用眼底彩色照片来筛查糖尿病视网膜病变,这是一种可预防失明的主要原因。但现有自动化工具大多将中心凹标记为一个点,而不是描出其真实的区域,而后者才是医生在判断谁需要注射、谁需要激光治疗以及谁可以安全等待时真正需要的。本研究展示了一种新的数据驱动人工智能(AI)方法如何学会像眼科专家那样观察中心凹——通过关注眼球的整体解剖结构而不仅仅是中心凹本身。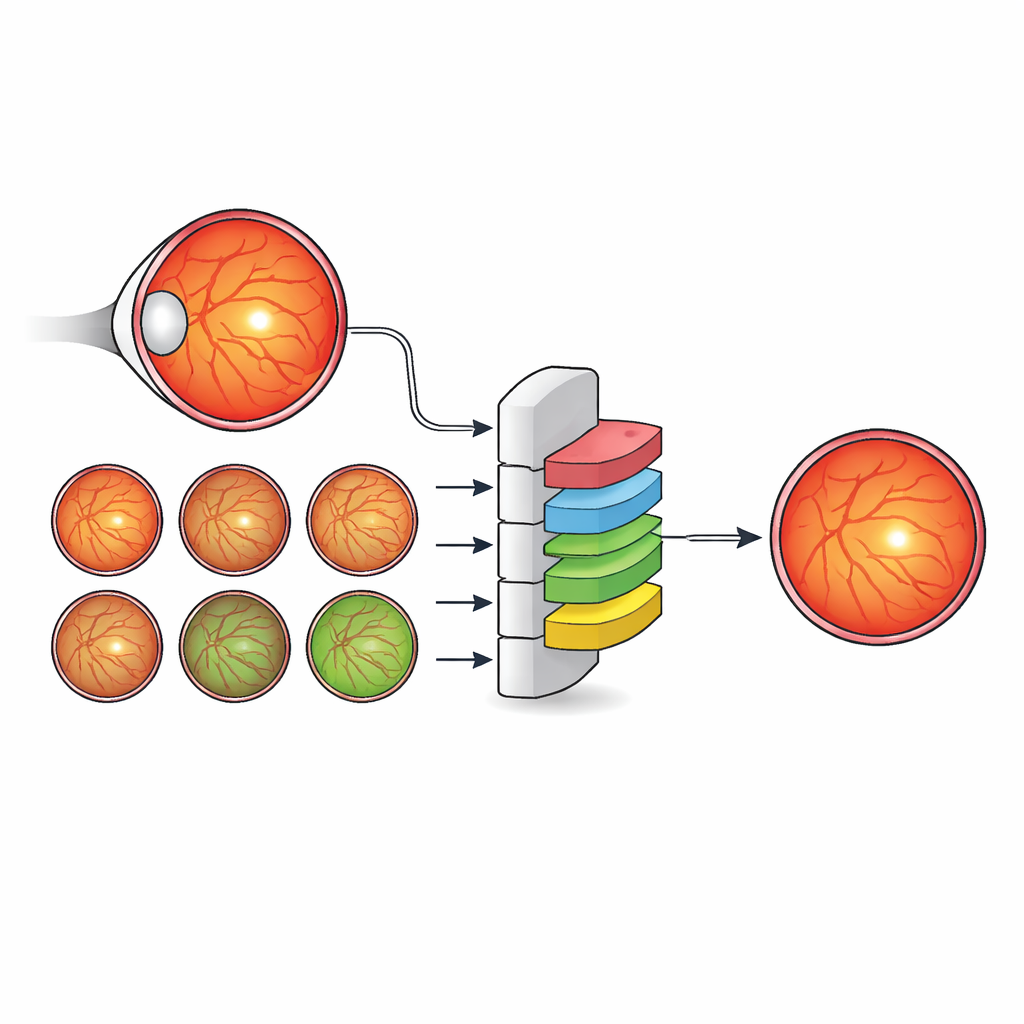
为什么中心凹难以描出轮廓
中心凹是视网膜上一个微小且浅的凹陷,赋予我们锐利的中央视力和丰富的色觉。在眼底图像上,其边界模糊,外观随相机不同而变化,疾病也会进一步使其变得不清晰。传统的计算方法依赖简单的亮度与几何规则,但在存在病灶或图像质量欠佳时很快失效。较新的深度学习系统虽提升了中心凹的检测,但通常要么将各个眼部结构分开处理,要么依赖日益复杂的网络设计。这两种做法常常忽视一个临床现实:眼科医生并不孤立地寻找中心凹——他们使用视盘和血管等地标以及整体血管分布来推断中心凹的位置,即便它难以直接辨认。
教会AI读取眼睛的路线图
作者提出了不同的策略:与其发明越来越复杂的网络架构,不如丰富用于训练的标注。他们创造了一个新数据集 IDRiD-RETA-FV,眼科专家在其中不仅对中心凹进行了像素级描画,还仔细标注了视盘、血管、整体视网膜和背景。两位眼科医生遵循严格协议,在这些标注上达成了接近完美的一致,为AI系统提供了可靠的参考。在该数据集上,他们使用了基于广泛采用架构的分割模型 MNv4Fovea,但让它同时分割所有解剖结构。通过逐步向训练标签中加入更多上下文——先仅有中心凹与背景,然后加入视盘,再加入视网膜轮廓,最后加入血管——他们能够直接衡量每块解剖信息对模型定位中心凹的帮助程度。
上下文与巧妙的增强如何提高准确性
结果表明,上下文非常重要。当模型仅从中心凹与背景标签学习时,它只正确识别了略高于四分之一的中心凹像素。仅仅加入视盘带来的提升也只是适度。但是一旦加入视网膜轮廓,性能便显著上升,而再加入血管则将中心凹的召回率推高到90%以上。换句话说,当AI模型获得了与眼科医生相同的路线图——视盘、血管和视网膜边界——它在描绘中心凹方面变得远为准确。为了帮助系统适应来自不同相机的图像,团队还设计了一种新颖的方法以改变图像的颜色与亮度。他们使用广义极值(GEV)分布对其他公开眼科数据集的风格进行建模,并将训练图像转换为这些风格以模拟不同拍摄条件,同时保留解剖结构。相比仅做常规几何变换,这种基于GEV的增强几乎使成功检测中心凹的比率翻倍。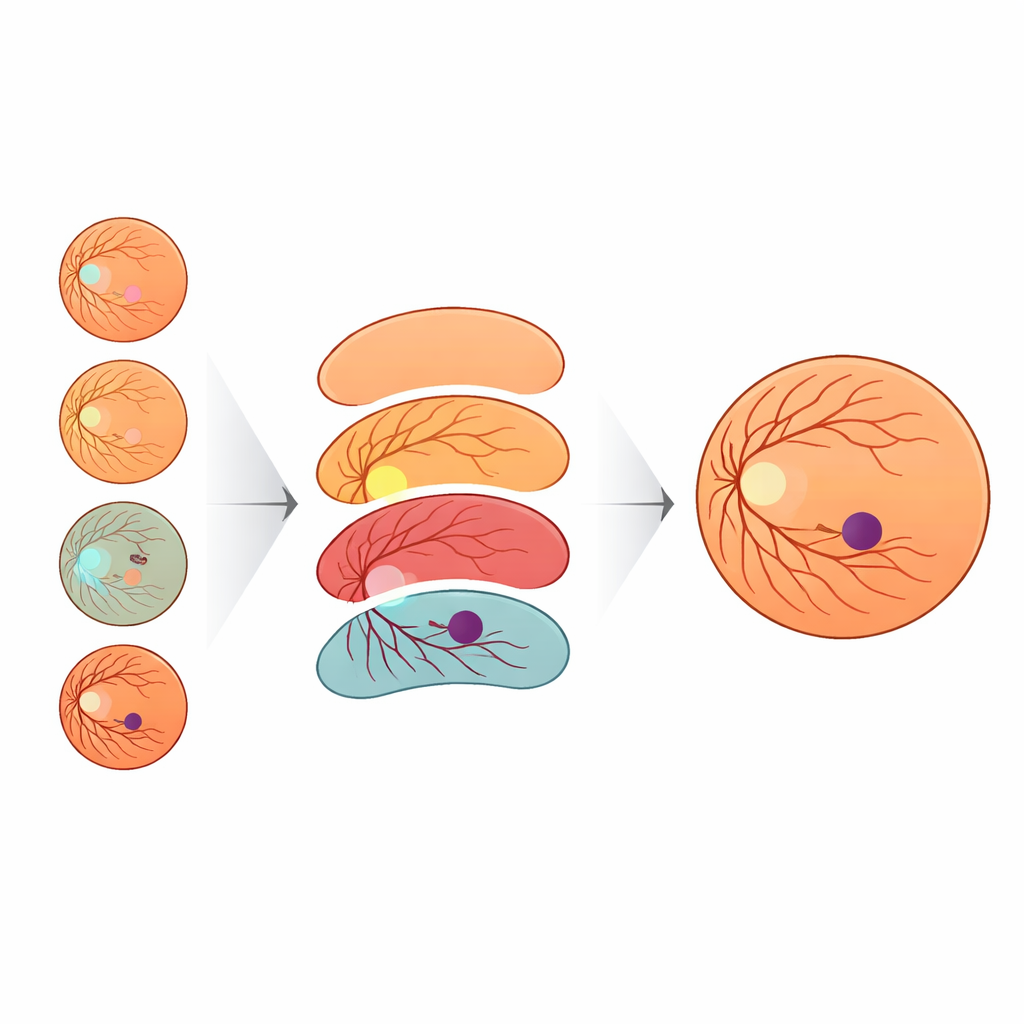
证明在多数据集上也有效
MNv4Fovea 在新建的专家标注数据集以及若干知名的公开视网膜图像集中进行了测试。在 IDRiD-RETA-FV 的保留测试集上,预测的中心凹区域与真实标注有高度重叠,并且将中心凹中心定位到仅几个像素内——基本上只要中心凹存在就能被检测到。在 MESSIDOR、REFUGE、ARIA 和 MAPLES-DR 等外部数据集中,该模型在中心凹预测与参考点接近度方面与或超过了现有最先进方法。有趣的是,在某些情况下数值评分看起来较为保守,是因为外部数据集对“中心凹”的定义不同——例如标注为较宽的黄斑区而非临床上的微小中心凹——但专家复核表明模型的预测在解剖学上是合理的,并且往往比原有标签更接近专家意见。
这对患者与未来工具的意义
对糖尿病患者而言,这项研究指出了一条通往更可靠、可广泛部署的筛查工具的路径,这类工具不仅仅在视网膜上打一个点。通过从完整的解剖上下文——视盘、血管和视网膜轮廓——学习,而不是仅依赖架构上的技巧,MNv4Fovea 能够精确绘制中心凹区域,这对于判断视网膜水肿或病灶是否足以威胁中央视力至关重要。作者认为,这种以数据为中心、以解剖为导向的方法可以补充未来的网络设计改进,并且类似策略可能有利于医学影像中其他许多需要在复杂病变环境中定位微妙结构的领域。
引用: Chankhachon, S., Kansomkeat, S., Bhurayanontachai, P. et al. Contextual anatomy-guided deep learning for accurate fovea segmentation in diabetic retinopathy fundus images. Sci Rep 16, 10388 (2026). https://doi.org/10.1038/s41598-026-40287-y
关键词: 糖尿病视网膜病变, 视网膜成像, 中心凹分割, 深度学习, 医学图像分析