Clear Sky Science · it
Anatomia contestuale guidata dall’apprendimento profondo per una segmentazione accurata della fovea nelle immagini del fundus nella retinopatia diabetica
Scoprire il pericolo negli occhi diabetici
Per milioni di persone con diabete, una piccola area al centro della retina—la fovea—può segnare la differenza tra una vista nitida e una perdita visiva permanente. I medici già utilizzano fotografie a colori della parte posteriore dell’occhio (immagini del fundus) per lo screening della retinopatia diabetica, una delle principali cause di cecità prevenibile. Ma gli strumenti automatizzati attuali individuano per lo più la fovea come un singolo punto piuttosto che delinearne l’area reale, che è ciò di cui i clinici hanno bisogno per decidere chi necessita di iniezioni, chi di trattamento laser e chi può aspettare in sicurezza. Questo studio mostra come un nuovo metodo di intelligenza artificiale (IA) guidato dai dati possa imparare a vedere la fovea più come farebbe uno specialista, prestando attenzione all’intero paesaggio anatomico dell’occhio invece che alla sola fovea. 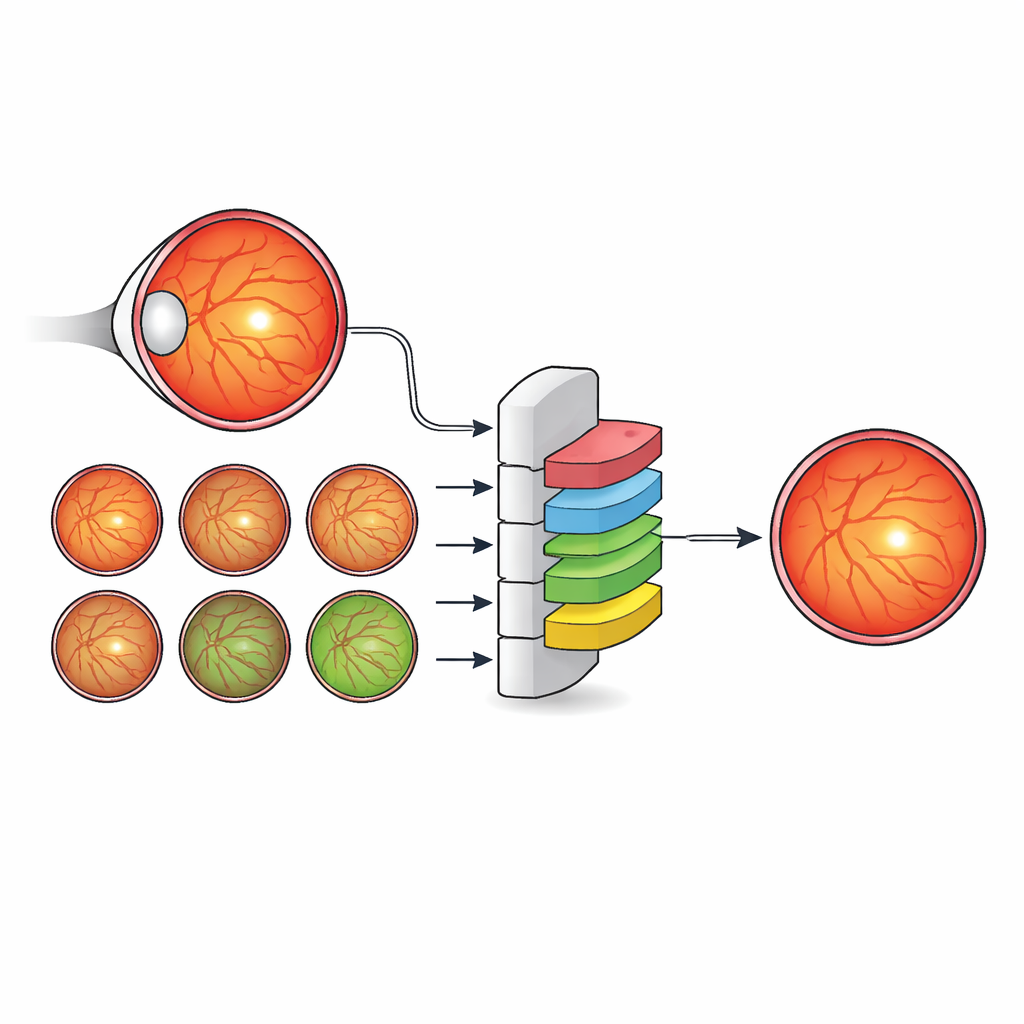
Perché è difficile delineare la fovea
La fovea è una piccola, superficiale depressione nella retina che ci offre la visione centrale nitida e una ricca percezione dei colori. Nelle immagini del fundus i suoi contorni sono sfumati, il suo aspetto varia da fotocamera a fotocamera e la malattia può renderla ancora più indistinta. I metodi tradizionali basati su semplici criteri di luminosità e regole geometriche falliscono rapidamente in presenza di lesioni o di scarsa qualità dell’immagine. I nuovi sistemi di deep learning hanno migliorato la rilevazione della fovea, ma di solito trattano ogni struttura oculare separatamente o si affidano a architetture di rete sempre più complesse. Entrambi gli approcci spesso ignorano una realtà clinica di base: gli oftalmologi non cercano la fovea in isolamento—utilizzano punti di riferimento come il disco ottico e il pattern dei vasi sanguigni per inferire dove la fovea debba trovarsi, anche quando è difficile da vedere.
Insegnare all’IA a leggere la mappa dell’occhio
Gli autori propongono una strategia diversa: invece di inventare architetture di rete sempre più intricate, arricchiscono le etichette usate per addestrare un modello standard ed efficiente. Hanno creato un nuovo dataset, IDRiD-RETA-FV, in cui specialisti oculari hanno tracciato con cura contorni a livello di pixel non solo per la fovea ma anche per il disco ottico, i vasi sanguigni, la retina complessiva e lo sfondo. Due oftalmologi hanno seguito un protocollo rigoroso raggiungendo un accordo quasi perfetto su queste annotazioni, fornendo un solido riferimento per il sistema IA. In questo dataset hanno inserito MNv4Fovea, un modello di segmentazione basato su un’architettura ampiamente usata, ma addestrato a segmentare tutte le strutture anatomiche contemporaneamente. Aggiungendo progressivamente più contesto alle etichette di addestramento—prima solo fovea contro sfondo, poi includendo il disco ottico, poi la retina e infine i vasi—hanno potuto misurare direttamente quanto ogni elemento anatomico aiuti il modello a trovare la fovea.
Come il contesto e l’augmentazione intelligente migliorano l’accuratezza
I risultati mostrano che il contesto è estremamente importante. Quando il modello è stato addestrato solo con etichette fovea e sfondo, ha identificato correttamente poco più di un quarto dei pixel foveali. Aggiungere semplicemente il disco ottico ha offerto solo guadagni modesti. Ma una volta inclusa la sagoma della retina, le prestazioni sono salite nettamente, e l’aggiunta dei vasi sanguigni ha portato il richiamo della fovea oltre il 90 percento. In altre parole, quando al modello IA è stata data la stessa mappa che usano gli oftalmologi—disco, vasi e confine retinico—è diventato molto più bravo a delineare la fovea. Per aiutare il sistema a funzionare su immagini provenienti da diverse fotocamere, il team ha anche ideato un nuovo modo di variare colore e luminosità delle immagini. Hanno modellato l’aspetto di altri dataset retinici pubblici usando una distribuzione statistica chiamata distribuzione degli estremi generalizzata (Generalized Extreme Value, GEV) e hanno trasformato le immagini di addestramento per imitare quegli stili pur preservando l’anatomia. Questa augmentazione basata su GEV ha quasi raddoppiato il tasso di rilevazioni foveali riuscite rispetto alle sole modifiche geometriche standard. 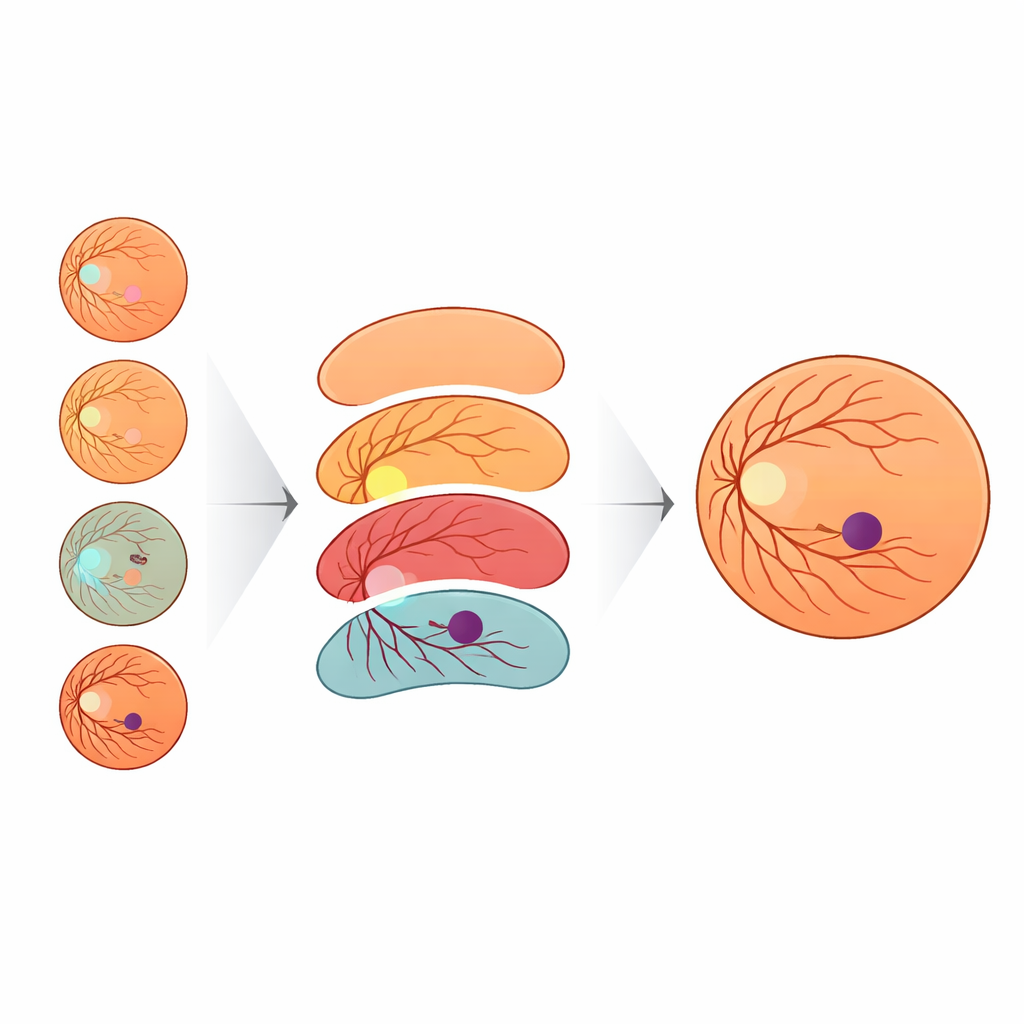
Dimostrare che funziona su molti dataset
MNv4Fovea è stato testato sia sul nuovo dataset annotato dagli esperti sia su diverse raccolte pubbliche di immagini retiniche ben note. Sulla porzione di test tenuta da parte di IDRiD-RETA-FV, ha raggiunto un’elevata sovrapposizione tra le regioni foveali predette e quelle reali e ha localizzato il centro della fovea entro poche decine di pixel—praticamente rilevando sempre la fovea quando era presente. Su dataset esterni come MESSIDOR, REFUGE, ARIA e MAPLES-DR, il modello ha eguagliato o superato i metodi all’avanguardia in termini di prossimità delle predizioni foveali ai punti di riferimento. È interessante notare che, in alcuni casi, i punteggi numerici risultavano modesti perché i dataset esterni definivano la “fovea” in modo diverso—for example marcando una vasta zona maculare invece della piccola fovea clinica—eppure la revisione da parte di esperti ha mostrato che le predizioni del modello erano anatomicamente sensate e spesso più vicine all’opinione degli specialisti rispetto alle etichette originali.
Cosa significa per i pazienti e per gli strumenti futuri
Per le persone con diabete, lo studio indica una strada verso strumenti di screening più affidabili e ampiamente distribuibili che fanno più che posizionare un punto sulla retina. Imparando dal contesto anatomico completo—disco, vasi e contorno retinico—invece di affidarsi solo a escamotage architetturali, MNv4Fovea può mappare con precisione la regione foveale, un passo chiave per decidere se edema o lesioni sono abbastanza vicini da minacciare la visione centrale. Gli autori sostengono che questo approccio incentrato sui dati e guidato dall’anatomia possa completare i futuri progressi nel design delle reti, e che strategie simili possano avvantaggiare molte altre aree dell’imaging medico dove strutture sottili devono essere trovate in paesaggi complessi e patologici.
Citazione: Chankhachon, S., Kansomkeat, S., Bhurayanontachai, P. et al. Contextual anatomy-guided deep learning for accurate fovea segmentation in diabetic retinopathy fundus images. Sci Rep 16, 10388 (2026). https://doi.org/10.1038/s41598-026-40287-y
Parole chiave: retinopatia diabetica, imaging retinico, segmentazione della fovea, apprendimento profondo, analisi di immagini mediche