Clear Sky Science · nl
Contextueel anatomie-gestuurde deep learning voor nauwkeurige fovea-segmentatie in fundusbeelden bij diabetische retinopathie
Het gevaar zien in diabetische ogen
Voor miljoenen mensen met diabetes kan een klein plekje in het hart van het netvlies — de fovea — het verschil betekenen tussen scherp zicht en blijvend gezichtsverlies. Artsen gebruiken kleurfoto’s van de achterkant van het oog (fundusbeelden) om te screenen op diabetische retinopathie, een belangrijke oorzaak van voorkombaar blindheid. De huidige geautomatiseerde hulpmiddelen plaatsen de fovea meestal als een enkel punt in plaats van het werkelijke oppervlak af te bakenen, terwijl artsen juist die oppervlakte nodig hebben om te bepalen wie injecties nodig heeft, wie laserbehandeling nodig heeft en wie veilig kan wachten. Deze studie toont hoe een nieuwe data-gedreven kunstmatige intelligentie (AI)-methode kan leren de fovea te zien zoals een oogspecialist dat doet, door rekening te houden met het volledige anatomische landschap van het oog in plaats van alleen de fovea zelf. 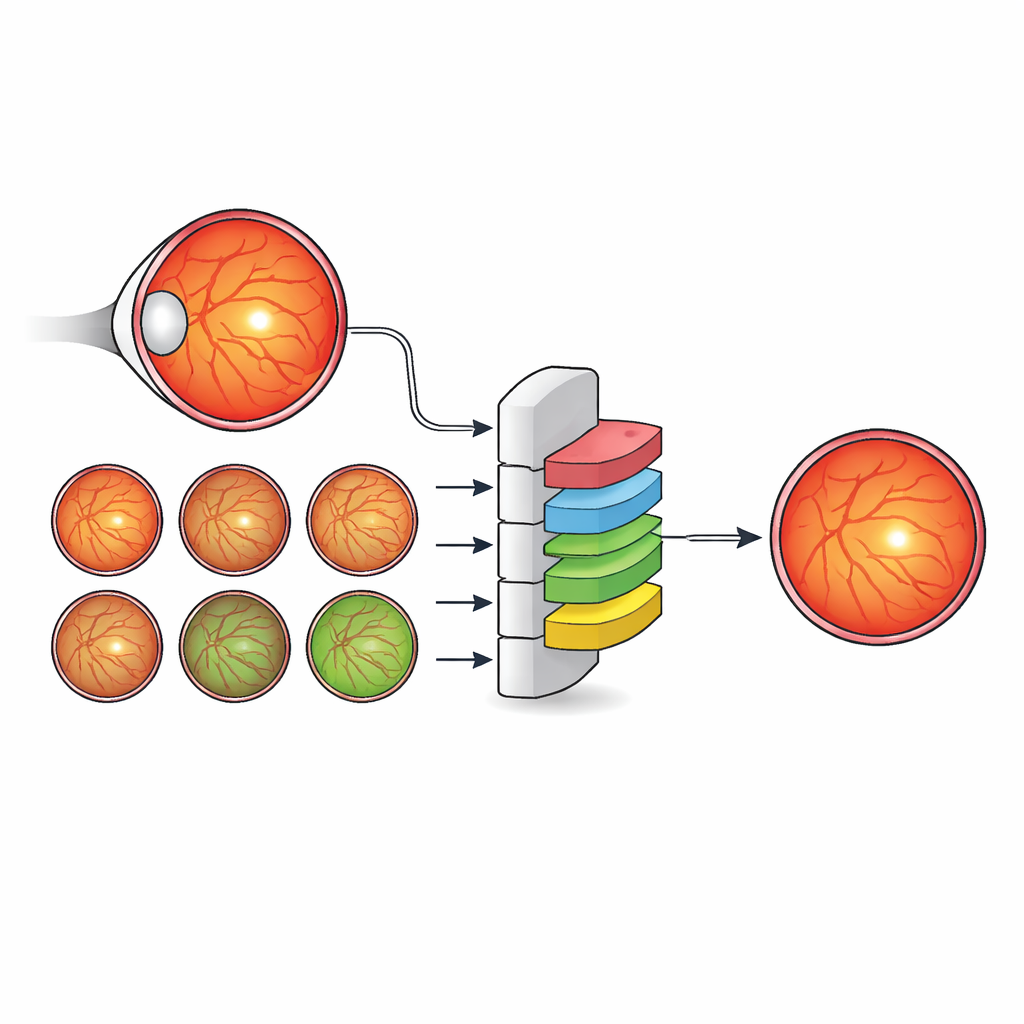
Waarom het moeilijk is de fovea af te bakenen
De fovea is een kleine, ondiepe inkeping in het netvlies die ons scherpe centrale zicht en rijke kleurwaarneming geeft. Op fundusbeelden zijn de randen vaag, verschilt het uiterlijk per camera en kan ziekte het nog onduidelijker maken. Traditionele computermethoden leunden op eenvoudige helderheids- en geometrische regels, die snel het onderspit delven bij letsels of slechte beeldkwaliteit. Nieuwere deep learning-systemen hebben de fovea-detectie verbeterd, maar behandelen vaak elk oogsstructuur afzonderlijk of vertrouwen op steeds complexere netwerktopologieën. Beide benaderingen negeren vaak een eenvoudige klinische realiteit: oogartsen zoeken de fovea niet geïsoleerd — ze gebruiken herkenningspunten zoals de papil (optic disc) en het patroon van bloedvaten om af te leiden waar de fovea moet liggen, zelfs als die moeilijk te zien is.
AI leren de kaart van het oog te lezen
De auteurs stellen een andere strategie voor: in plaats van steeds ingewikkeldere netwerkarchitecturen te bedenken, verrijken zij de labels die worden gebruikt om een standaard, efficiënt model te trainen. Ze maakten een nieuwe dataset, IDRiD-RETA-FV, waarin oogspecialisten pixelnauwkeurige contouren tekenden, niet alleen van de fovea maar ook van de papil, de bloedvaten, het gehele netvlies en de achtergrond. Twee oogartsen volgden een strikt protocol en bereikten bijna perfecte overeenstemming in deze markeringen, wat een solide referentie voor het AI-systeem oplevert. Op deze dataset pasten ze MNv4Fovea toe, een segmentatiemodel gebaseerd op een veelgebruikte architectuur, maar trainden het om alle anatomische structuren tegelijk te segmenteren. Door stapsgewijs meer context aan de trainingslabels toe te voegen — eerst alleen fovea versus achtergrond, vervolgens de papil, daarna het netvlies en ten slotte de vaten — konden ze direct meten hoeveel elke anatomische component het model helpt de fovea te vinden.
Hoe context en slimme augmentatie de nauwkeurigheid verhogen
De resultaten laten zien dat context enorm belangrijk is. Wanneer het model alleen leerde van fovea- en achtergrondlabels, identificeerde het iets meer dan een kwart van de foveale pixels correct. Het eenvoudig toevoegen van de papil leverde slechts bescheiden verbeteringen op. Maar zodra de netvliescontour werd opgenomen, steeg de prestatie scherp, en het toevoegen van bloedvaten duwde de recall van de fovea boven de 90 procent. Met andere woorden: zodra het AI-model dezelfde ‘kaart’ kreeg die oogartsen gebruiken — papil, vaten en netvliesgrens — werd het veel beter in het afbakenen van de fovea. Om het systeem robuust te maken voor beelden van verschillende camera’s, ontwikkelde het team ook een nieuwe manier om kleur en helderheid van beelden te variëren. Ze modelleerden hoe andere openbare oogdatasets eruitzien met een statistische verdeling genaamd de Generalized Extreme Value (GEV)-verdeling en transformeerden trainingsbeelden om die stijlen na te bootsen terwijl de anatomie behouden bleef. Deze GEV-gebaseerde augmentatie verdubbelde bijna het percentage succesvolle fovea-detecties vergeleken met standaard geometrische variaties alleen. 
Aantonen dat het werkt op veel datasets
MNv4Fovea werd getest op zowel de nieuw door experts gelabelde dataset als op meerdere bekende openbare verzamelingen van retinale beelden. Op de niet-gebruikte testsplit van IDRiD-RETA-FV behaalde het model een grote overlap tussen voorspelde en werkelijke foveale regio’s en lokaliseerde het foveale centrum binnen slechts enkele pixels — het detecteerde de fovea in wezen altijd wanneer die aanwezig was. Op externe datasets zoals MESSIDOR, REFUGE, ARIA en MAPLES-DR evenaarde of overtrof het model de state-of-the-art methoden in hoe dicht zijn foveavoorspellingen bij de referentiepunten lagen. Interessant genoeg leken de numerieke scores in sommige gevallen bescheiden omdat de externe datasets “fovea” anders definieerden — bijvoorbeeld door een brede maculaire zone te markeren in plaats van de kleine klinische fovea — toch toonde een deskundige beoordeling dat de voorspellingen anatomisch aannemelijk waren en vaak dichter bij de mening van specialisten lagen dan bij de oorspronkelijke labels.
Wat dit betekent voor patiënten en toekomstige hulpmiddelen
Voor mensen met diabetes benadrukt de studie een route naar betrouwbaardere, breed inzetbare screeningshulpmiddelen die meer doen dan een punt op het netvlies zetten. Door te leren van de volledige anatomische context — papil, vaten en netvliesomtrek — in plaats van uitsluitend op architecturale trucs te vertrouwen, kan MNv4Fovea het foveale gebied nauwkeurig in kaart brengen, een belangrijke stap om te bepalen of zwelling of letsels dicht genoeg bij het centrale zicht liggen om het te bedreigen. De auteurs stellen dat deze data-centrische, anatomie-gestuurde aanpak toekomstige verbeteringen in netwerkontwerp kan aanvullen, en dat vergelijkbare strategieën nuttig kunnen zijn in vele andere gebieden van medische beeldvorming waar subtiele structuren in complexe, zieke landschappen moeten worden gevonden.
Bronvermelding: Chankhachon, S., Kansomkeat, S., Bhurayanontachai, P. et al. Contextual anatomy-guided deep learning for accurate fovea segmentation in diabetic retinopathy fundus images. Sci Rep 16, 10388 (2026). https://doi.org/10.1038/s41598-026-40287-y
Trefwoorden: diabetische retinopathie, retinale beeldvorming, fovea-segmentatie, deep learning, medische beeldanalyse