Clear Sky Science · pt
Anatomia contextual orientada por deep learning para segmentação precisa da fóvea em imagens de fundo de olho com retinopatia diabética
Vendo o Perigo nos Olhos Diabéticos
Para milhões de pessoas com diabetes, um pequeno ponto no centro da retina—a fóvea—pode significar a diferença entre visão nítida e perda visual permanente. Médicos já usam fotografias coloridas do fundo do olho (imagens de fundoscopia) para rastrear a retinopatia diabética, uma das principais causas de cegueira evitável. Mas as ferramentas automatizadas atuais geralmente identificam a fóvea como um único ponto em vez de delinear sua verdadeira área, que é o que os médicos realmente precisam para decidir quem requer injeções, quem precisa de tratamento a laser e quem pode esperar com segurança. Este estudo mostra como um novo método de inteligência artificial (IA) orientado por dados pode aprender a ver a fóvea de forma mais parecida com um especialista, prestando atenção a toda a paisagem anatômica do olho em vez de focar apenas na fóvea. 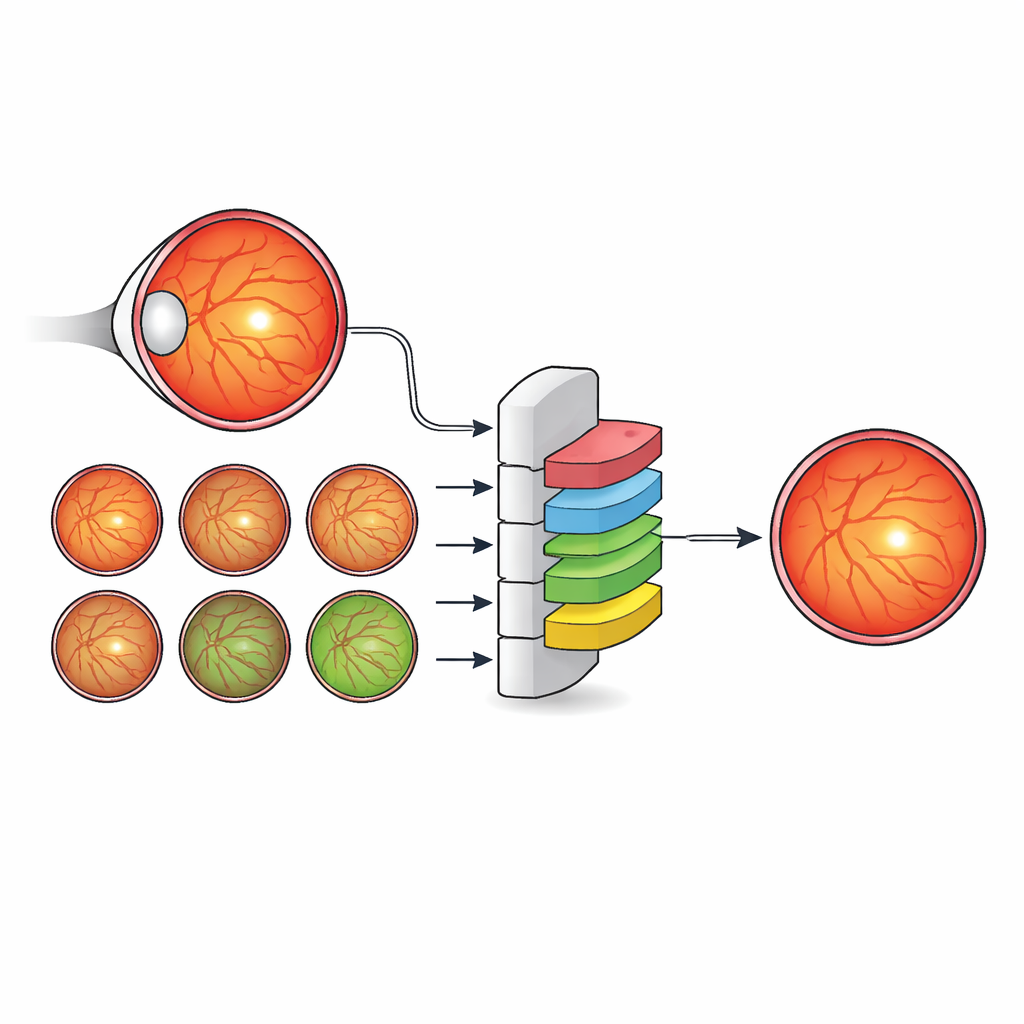
Por Que é Difícil Delinear a Fóvea
A fóvea é uma depressão minúscula e superficial na retina que nos dá visão central nítida e percepção de cores rica. Em imagens de fundoscopia, suas bordas são esfumaçadas, sua aparência varia de câmera para câmera e a doença pode torná-la ainda mais indistinta. Métodos computacionais tradicionais dependiam de regras simples de brilho e geometria, que rapidamente falham na presença de lesões ou má qualidade da imagem. Sistemas mais recentes baseados em deep learning melhoraram a detecção da fóvea, mas geralmente tratam cada estrutura ocular separadamente ou dependem de arquiteturas de rede cada vez mais complexas. Ambas as abordagens frequentemente ignoram uma realidade clínica básica: oftalmologistas não procuram a fóvea isoladamente—eles usam marcos como o disco óptico e o padrão dos vasos sanguíneos para inferir onde a fóvea deve estar, mesmo quando é difícil de ver.
Ensinando a IA a Ler o Mapa do Olho
Os autores propõem uma estratégia diferente: em vez de inventar arquiteturas de rede cada vez mais intrincadas, eles enriquecem os rótulos usados para treinar um modelo padrão e eficiente. Criaram um novo conjunto de dados, IDRiD-RETA-FV, no qual especialistas oculares traçaram cuidadosamente contornos em nível de pixel não só da fóvea, mas também do disco óptico, dos vasos sanguíneos, da retina como um todo e do fundo. Dois oftalmologistas seguiram um protocolo rígido e alcançaram concordância quase perfeita nessas marcações, fornecendo uma referência sólida para o sistema de IA. Nesse conjunto de dados eles utilizaram o MNv4Fovea, um modelo de segmentação baseado em uma arquitetura amplamente usada, mas treinado para segmentar todas as estruturas anatômicas de uma só vez. Ao adicionar progressivamente mais contexto aos rótulos de treinamento—primeiro apenas fóvea versus fundo, depois incluindo o disco óptico, depois a retina e, por fim, os vasos—puderam medir diretamente quanto cada peça da anatomia ajuda o modelo a localizar a fóvea.
Como Contexto e Augmentação Inteligente Aumentam a Precisão
Os resultados mostram que o contexto importa enormemente. Quando o modelo aprendeu apenas a partir de rótulos de fóvea e fundo, identificou corretamente pouco mais de um quarto dos pixels foveais. Acrescentar simplesmente o disco óptico trouxe ganhos modestos. Mas uma vez incluído o contorno da retina, o desempenho subiu acentuadamente, e adicionar os vasos sanguíneos elevou a sensibilidade foveal para acima de 90%. Em outras palavras, quando o modelo de IA recebeu o mesmo mapa que os oftalmologistas usam—disco, vasos e limite retiniano—ele melhorou muito ao delinear a fóvea. Para ajudar o sistema a funcionar em imagens de diferentes câmeras, a equipe também elaborou uma forma nova de variar cor e brilho das imagens. Eles modelaram a aparência de outros conjuntos de dados públicos de olhos usando uma distribuição estatística chamada distribuição de Valor Extremo Generalizada (GEV) e transformaram as imagens de treinamento para imitar esses estilos preservando a anatomia. Essa augmentação baseada em GEV quase dobrou a taxa de detecções foveais bem-sucedidas em comparação com ajustes geométricos padrão isoladamente. 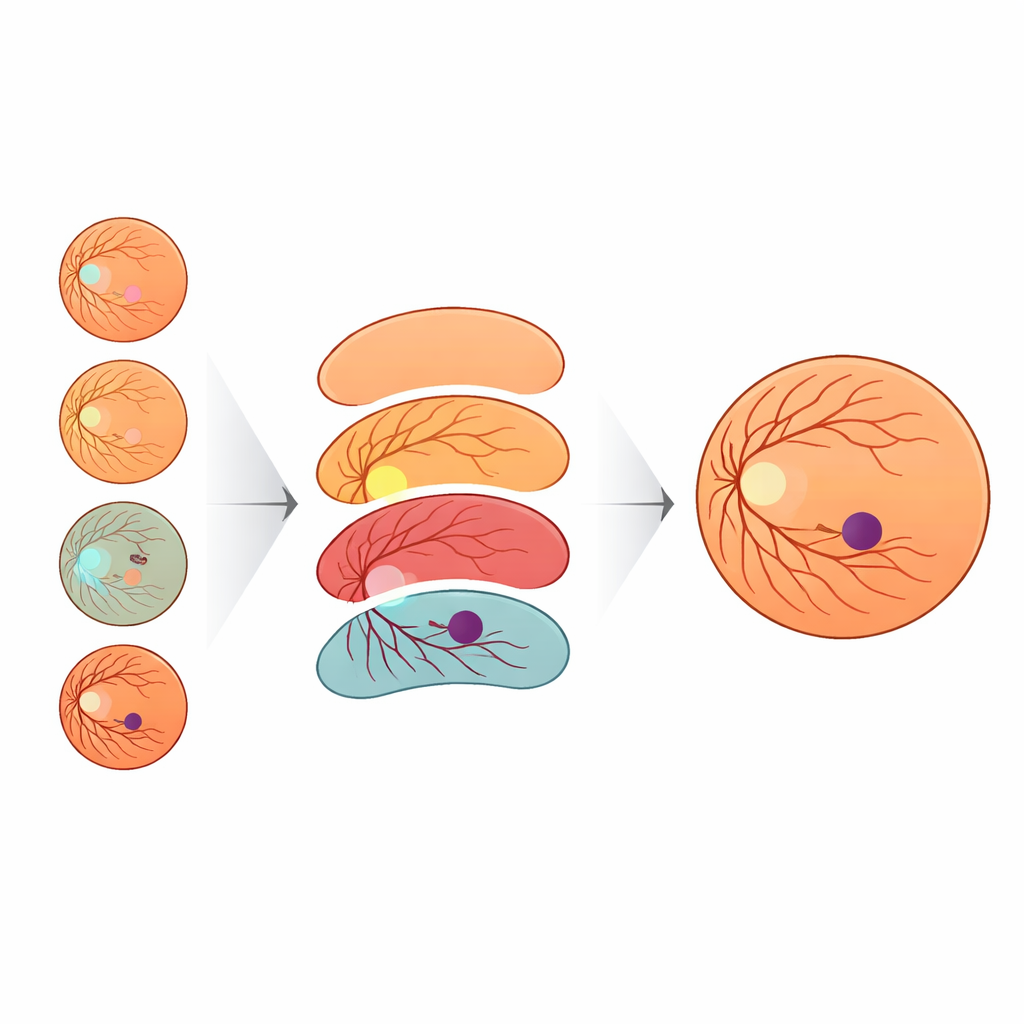
Comprovando que Funciona em Muitos Conjuntos de Dados
O MNv4Fovea foi testado tanto no novo conjunto de dados rotulado por especialistas quanto em várias coleções públicas bem conhecidas de imagens retinianas. No conjunto de teste reservado do IDRiD-RETA-FV, alcançou alta sobreposição entre as regiões foveais previstas e as reais e localizou o centro foveal a apenas alguns pixels—essencialmente detectando a fóvea sempre que ela estava presente. Em conjuntos externos como MESSIDOR, REFUGE, ARIA e MAPLES-DR, o modelo igualou ou superou métodos de ponta em quão próximas suas predições da fóvea estavam dos pontos de referência. Interessantemente, em alguns casos as pontuações numéricas pareceram modestas porque os conjuntos externos definiam “fóvea” de forma diferente—por exemplo, marcando uma ampla zona macular em vez da pequena fóvea clínica—ainda assim a revisão de especialistas mostrou que as previsões do modelo eram anatomicamente sensatas e frequentemente mais próximas da opinião de um especialista do que dos rótulos originais.
O Que Isso Significa para Pacientes e Ferramentas Futuras
Para pessoas com diabetes, o estudo aponta um caminho para ferramentas de triagem mais confiáveis e amplamente aplicáveis que fazem mais do que posicionar um ponto na retina. Ao aprender a partir do contexto anatômico completo—disco, vasos e contorno retiniano—in vez de confiar apenas em truques arquiteturais, o MNv4Fovea pode mapear com precisão a região foveal, um passo-chave para decidir se inchaço ou lesões estão próximos o suficiente para ameaçar a visão central. Os autores argumentam que essa abordagem centrada em dados e guiada pela anatomia pode complementar avanços futuros em desenho de redes, e que estratégias semelhantes podem beneficiar muitas outras áreas da imagem médica onde estruturas sutis precisam ser encontradas em paisagens complexas e doentes.
Citação: Chankhachon, S., Kansomkeat, S., Bhurayanontachai, P. et al. Contextual anatomy-guided deep learning for accurate fovea segmentation in diabetic retinopathy fundus images. Sci Rep 16, 10388 (2026). https://doi.org/10.1038/s41598-026-40287-y
Palavras-chave: retinopatia diabética, imagens da retina, segmentação da fóvea, deep learning, análise de imagens médicas