Clear Sky Science · es
Aprendizaje profundo guiado por la anatomía contextual para una segmentación precisa de la fóvea en imágenes de fondo de ojo con retinopatía diabética
Ver el peligro en ojos diabéticos
Para millones de personas con diabetes, una pequeña zona en el centro de la retina —la fóvea— puede marcar la diferencia entre ver con claridad y sufrir una pérdida visual permanente. Los médicos ya usan fotografías en color del fondo de ojo (imágenes de fondo) para detectar la retinopatía diabética, una de las principales causas de ceguera prevenible. Pero las herramientas automatizadas actuales generalmente localizan la fóvea como un único punto en lugar de delinear su área real, que es lo que los especialistas necesitan para decidir quién requiere inyecciones, quién necesita tratamiento con láser y quién puede esperar de forma segura. Este estudio muestra cómo un nuevo método de inteligencia artificial (IA) basado en datos puede aprender a ver la fóvea más como lo hace un oftalmólogo, prestando atención a todo el paisaje anatómico del ojo en lugar de centrarse únicamente en la fóvea. 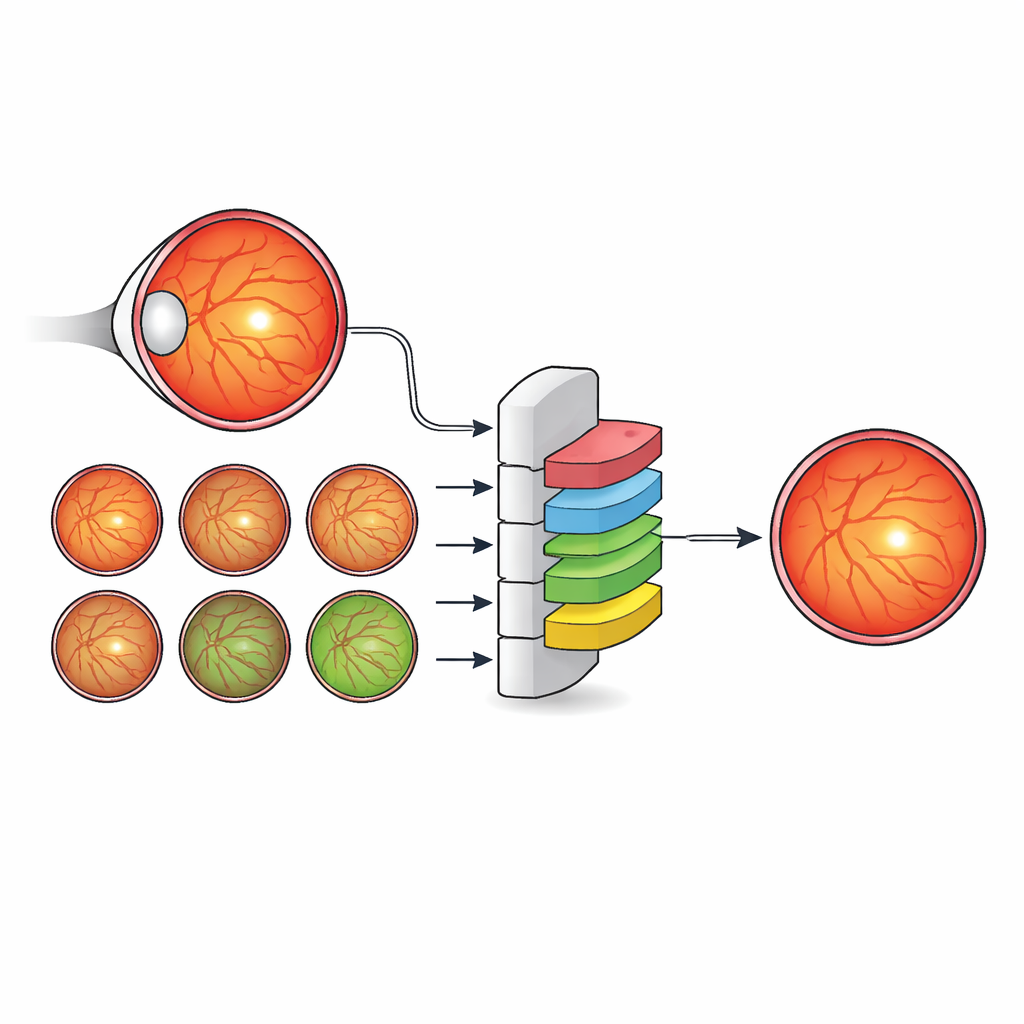
Por qué es difícil delinear la fóvea
La fóvea es una pequeña y superficial depresión en la retina que nos proporciona visión central nítida y una rica percepción del color. En las imágenes de fondo, sus bordes son difusos, su aspecto varía según la cámara y la enfermedad puede difuminarlos aún más. Los métodos informáticos tradicionales se basaban en reglas sencillas de brillo y geometría, que fallan rápidamente en presencia de lesiones o mala calidad de imagen. Los sistemas más recientes de aprendizaje profundo han mejorado la detección de la fóvea, pero por lo general tratan cada estructura ocular por separado o dependen de diseños de red cada vez más complejos. Ambos enfoques suelen pasar por alto una realidad clínica básica: los oftalmólogos no buscan la fóvea aisladamente —utilizan referencias como el disco óptico y el patrón de vasos sanguíneos para inferir dónde debe estar la fóvea, incluso cuando es difícil de ver.
Enseñar a la IA a leer el mapa del ojo
Los autores proponen una estrategia distinta: en lugar de inventar arquitecturas de red cada vez más intrincadas, enriquecen las etiquetas usadas para entrenar un modelo estándar y eficiente. Crearon un nuevo conjunto de datos, IDRiD-RETA-FV, en el que especialistas oculares dibujaron cuidadosamente contornos a nivel de píxel no solo para la fóvea, sino también para el disco óptico, los vasos sanguíneos, la retina en su conjunto y el fondo. Dos oftalmólogos siguieron un protocolo estricto y alcanzaron un acuerdo casi perfecto en estas anotaciones, ofreciendo una referencia sólida para el sistema de IA. En este conjunto de datos aplicaron MNv4Fovea, un modelo de segmentación basado en una arquitectura ampliamente utilizada, pero lo entrenaron para segmentar todas las estructuras anatómicas a la vez. Al añadir progresivamente más contexto a las etiquetas de entrenamiento —primero solo fóvea frente a fondo, luego incluyendo el disco óptico, después la retina y finalmente los vasos— pudieron medir directamente cuánto ayuda cada elemento de la anatomía al modelo para localizar la fóvea.
Cómo el contexto y una buena augmentación mejoran la precisión
Los resultados muestran que el contexto importa enormemente. Cuando el modelo aprendió solo con etiquetas de fóvea y fondo, identificó correctamente poco más de una cuarta parte de los píxeles foveales. Añadir el disco óptico ofreció solo ganancias modestísimas. Pero al incluir el contorno de la retina, el rendimiento aumentó de forma pronunciada, y sumar los vasos sanguíneos elevó la recuperación (recall) de la fóvea por encima del 90 por ciento. En otras palabras, cuando al modelo de IA se le proporcionó el mismo mapa que usan los oftalmólogos —disco, vasos y el límite retiniano— fue mucho mejor delineando la fóvea. Para ayudar al sistema a funcionar con imágenes de distintas cámaras, el equipo también ideó una forma novedosa de variar el color y el brillo de las imágenes. Modelaron cómo se ven otros conjuntos públicos de imágenes oculares usando una distribución estadística llamada distribución de Valor Extremo Generalizado (GEV) y transformaron las imágenes de entrenamiento para imitar esos estilos manteniendo la anatomía. Esta augmentación basada en GEV casi duplicó la tasa de detecciones exitosas de la fóvea en comparación con los ajustes geométricos estándar.
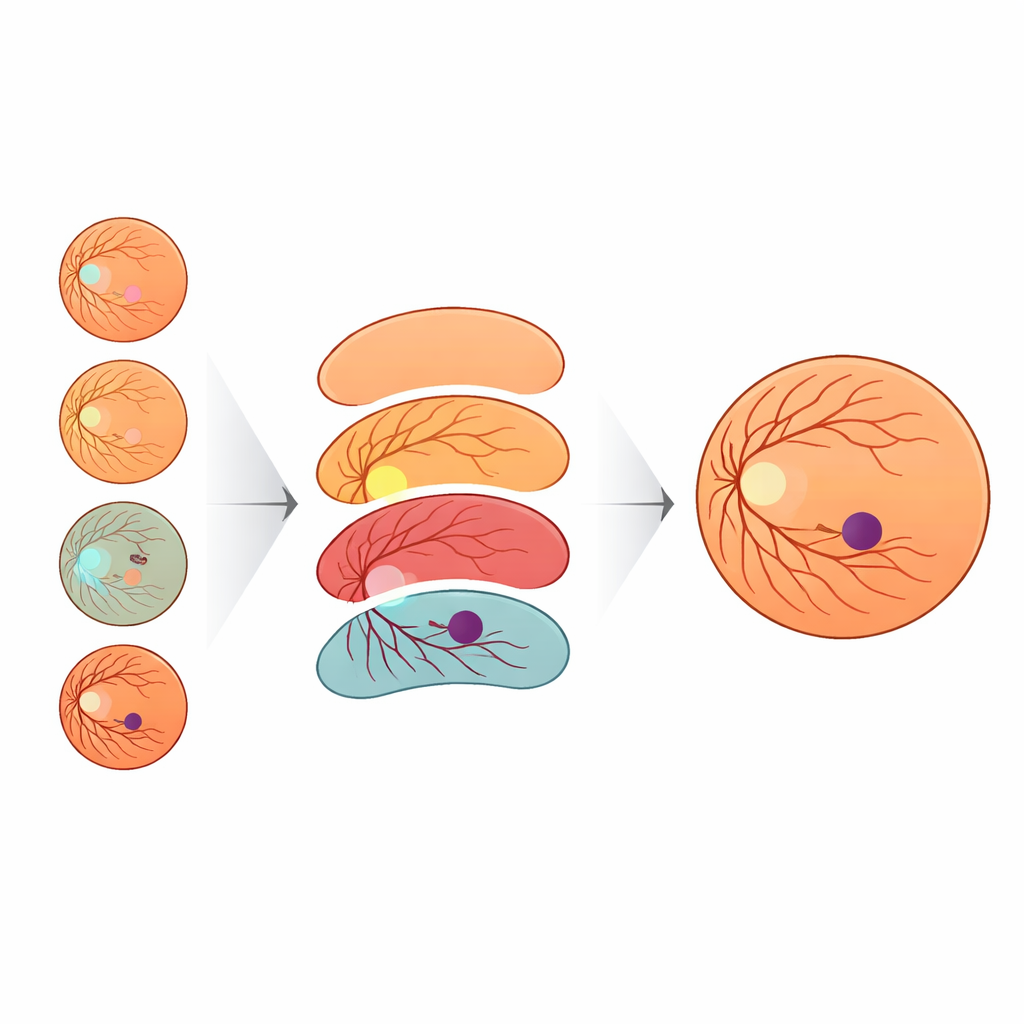
Demostrar que funciona en muchos conjuntos de datos
MNv4Fovea se probó tanto en el nuevo conjunto de datos anotado por expertos como en varias colecciones públicas bien conocidas de imágenes retinianas. En la partición de prueba retenida de IDRiD-RETA-FV, alcanzó una alta superposición entre las regiones foveales predichas y las reales y localizó el centro foveal con solo unos pocos píxeles de diferencia —esencialmente detectando siempre la fóvea cuando estaba presente. En conjuntos externos como MESSIDOR, REFUGE, ARIA y MAPLES-DR, el modelo igualó o superó métodos de última generación en la cercanía de sus predicciones foveales respecto a los puntos de referencia. Curiosamente, en algunos casos las puntuaciones numéricas parecían modestas porque los conjuntos externos definían la “fóvea” de forma distinta —por ejemplo, marcando una amplia zona macular en lugar de la pequeña fóvea clínica— sin embargo la revisión de expertos mostró que las predicciones del modelo eran anatómicamente sensatas y a menudo más cercanas a la opinión de especialistas que a las etiquetas originales.
Qué significa esto para los pacientes y las futuras herramientas
Para las personas con diabetes, el estudio señala un camino hacia herramientas de cribado más fiables y ampliamente desplegables que hacen más que colocar un punto en la retina. Al aprender del contexto anatómico completo —disco, vasos y contorno retiniano— en lugar de confiar solo en trucos arquitectónicos, MNv4Fovea puede mapear con precisión la región foveal, un paso clave para decidir si el edema o las lesiones están lo bastante cerca como para amenazar la visión central. Los autores sostienen que este enfoque centrado en los datos y guiado por la anatomía puede complementar avances futuros en el diseño de redes, y que estrategias similares pueden beneficiar a muchas otras áreas de la imagen médica donde hay que encontrar estructuras sutiles en paisajes complejos y enfermos.
Cita: Chankhachon, S., Kansomkeat, S., Bhurayanontachai, P. et al. Contextual anatomy-guided deep learning for accurate fovea segmentation in diabetic retinopathy fundus images. Sci Rep 16, 10388 (2026). https://doi.org/10.1038/s41598-026-40287-y
Palabras clave: retinopatía diabética, imagenología retiniana, segmentación de la fóvea, aprendizaje profundo, análisis de imágenes médicas