Clear Sky Science · sv
Kontextstyrd anatomi-ledd djupinlärning för noggrann fovea-segmentering i fundusbilder vid diabetisk retinopati
Att se faran i diabetiska ögon
För miljontals människor med diabetes kan en liten fläck i själva centrum av ögats näthinna — fovean — skilja mellan klart seende och bestående synförlust. Läkare använder redan färgfoton av ögats bakre del (fundusbilder) för att screena för diabetisk retinopati, en ledande orsak till förebyggbar blindhet. Men dagens automatiserade verktyg pekar oftast ut fovean som en enda punkt i stället för att avgränsa dess verkliga yta, vilket är vad kliniker behöver för att avgöra vem som behöver injektioner, vem som behöver laserbehandling och vem som tryggt kan avvakta. Den här studien visar hur en ny datadriven artificiell intelligens (AI)-metod kan lära sig se fovean mer som en ögonspecialist gör, genom att uppmärksamma hela ögats anatomiska landskap i stället för enbart fovean.
Varför det är svårt att avgränsa fovean
Fovean är en liten, grund fördjupning i näthinnan som ger oss skarp central syn och rik färguppfattning. På fundusbilder är dess gränser suddiga, utseendet varierar mellan kameror och sjukdom kan göra den ännu svårare att urskilja. Traditionella datorbaserade metoder förlitade sig på enkla ljus- och geometriregler, vilka snabbt faller samman vid närvaro av lesioner eller dålig bildkvalitet. Nyare djupinlärningssystem har förbättrat fovea-detektion, men de behandlar oftast varje ögonstruktur separat eller bygger på allt mer komplexa nätverksdesigner. Båda angreppssätten förbiser ofta en grundläggande klinisk realitet: ögonläkare letar inte efter fovean isolerat — de använder landmärken som synnerven (optic disc) och blodkärlens mönster för att härleda var fovean måste ligga, även när den är svår att se.
Att lära AI att läsa ögats vägkarta
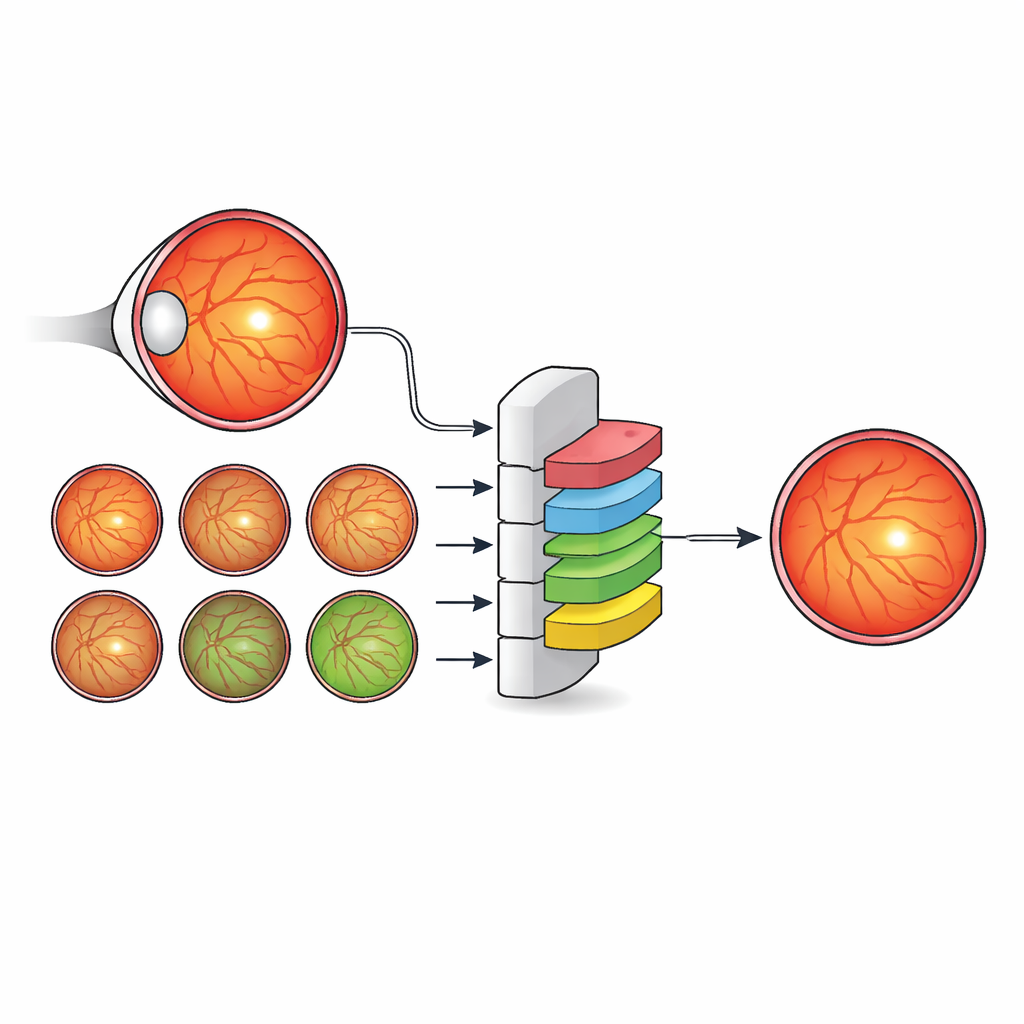
Författarna föreslår en annan strategi: istället för att uppfinna allt mer intrikata nätverksarkitekturer berikar de de etiketter som används för att träna en standard, effektiv modell. De skapade en ny dataset, IDRiD-RETA-FV, där ögonspecialister noggrant ritade pixelnivåkonturer inte bara för fovean utan också för synnerven, blodkärlen, hela näthinnan och bakgrunden. Två ögonläkare följde ett strikt protokoll och nådde nästan perfekt samsyn i dessa markeringar, vilket gav en solid referens för AI-systemet. I denna dataset använde de MNv4Fovea, en segmenteringsmodell baserad på en väl använd arkitektur, men tränade den att segmentera alla anatomiska strukturer samtidigt. Genom att successivt lägga till mer kontext i träningsetiketterna — först endast fovea kontra bakgrund, sedan inklusive synnerven, därefter näthinnan och slutligen kärlen — kunde de direkt mäta hur mycket varje anatomisk komponent hjälpte modellen att hitta fovean.
Hur kontext och smart augmentation ökar noggrannheten
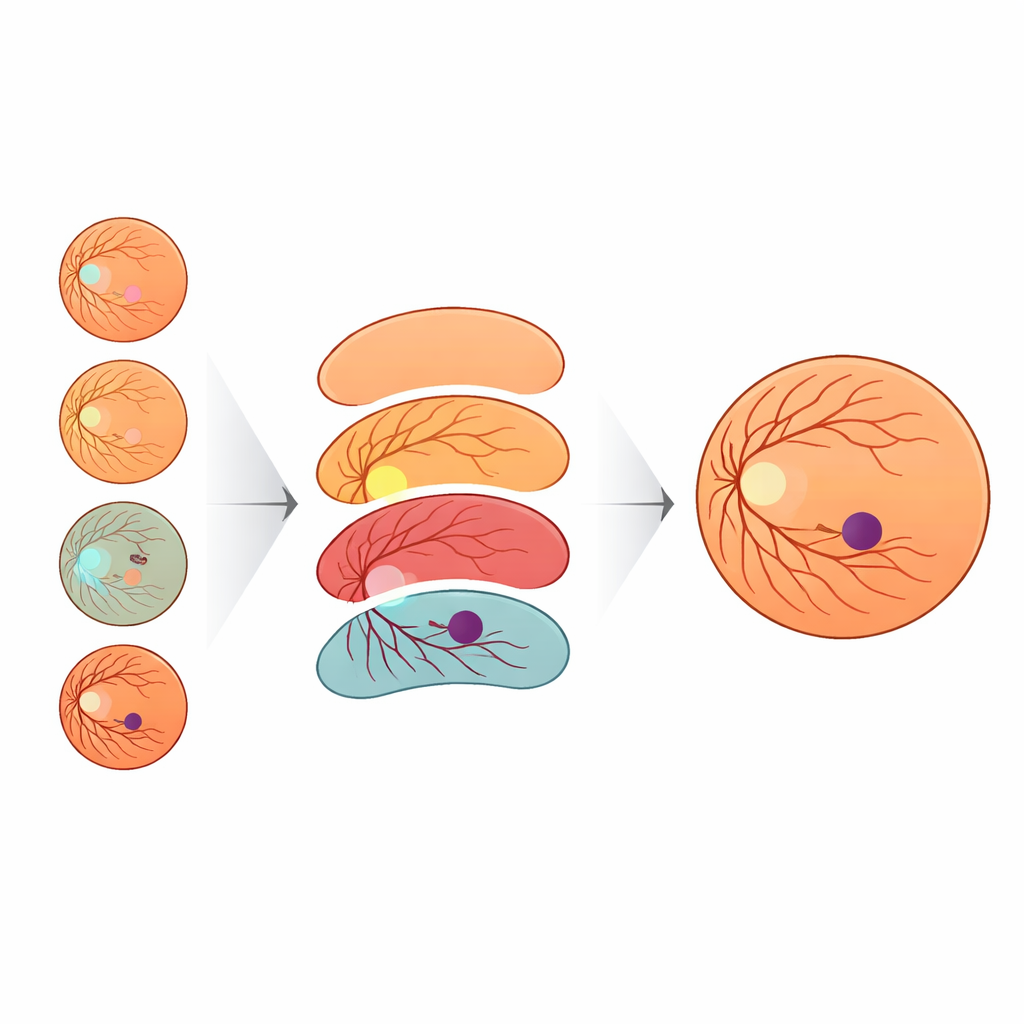
Resultaten visar att kontext spelar avgörande roll. När modellen endast lärde sig från etiketter för fovea och bakgrund identifierade den korrekt bara strax över en fjärdedel av foveala pixlar. Att enbart lägga till synnerven gav endast måttliga förbättringar. Men när näthinnekonturen inkluderades steg prestandan kraftigt, och att lägga till blodkärlen pressade fovea-återkallningen över 90 procent. Med andra ord, när AI-modellen gavs samma vägkarta som ögonläkare använder — synnerv, kärl och näthinnegräns — blev den mycket bättre på att avgränsa fovean. För att få systemet att fungera över bilder från olika kameror utvecklade teamet också ett nytt sätt att variera bildfärg och ljusstyrka. De modellerade hur andra offentliga ögondatasets ser ut med en statistisk fördelning kallad Generalized Extreme Value (GEV)-fördelning och transformerade träningsbilder för att efterlikna dessa stilar samtidigt som anatomin bevarades. Denna GEV-baserade augmentation fördubblade nästan andelen lyckade fovea-detektioner jämfört med standardmässiga geometriska justeringar ensam.
Bevisa att det fungerar över många dataset
MNv4Fovea testades både på den nya expert-annoterade datasetet och på flera välkända offentliga samlingar av retina-bilder. På den hållna testdelen av IDRiD-RETA-FV uppnådde den hög överlappning mellan predicerade och verkliga foveala regioner och lokaliserade foveas centrum inom bara ett fåtal pixlar — i praktiken hittade den alltid fovean när den fanns. På externa dataset såsom MESSIDOR, REFUGE, ARIA och MAPLES-DR matchade eller överträffade modellen state-of-the-art-metoder vad gäller hur nära dess foveaprediktioner låg referenspunkterna. Intressant nog såg de numeriska poängen i vissa fall måttliga ut eftersom de externa datasetten definierade ”fovea” olika — till exempel markerade en bred makulazond i stället för den kliniska lilla fovean — ändå visade expertgranskning att modellens prediktioner var anatomiskt rimliga och ofta närmare specialisternas uppfattning än de ursprungliga etiketterna.
Vad detta betyder för patienter och framtida verktyg
För personer som lever med diabetes pekar studien på en väg mot mer pålitliga, brett användbara screeningsverktyg som gör mer än att placera en punkt på näthinnan. Genom att lära från hela den anatomiska kontexten — synnerven, kärlen och näthinnekonturen — i stället för att förlita sig enbart på arkitektoniska knep kan MNv4Fovea exakt kartlägga fovearegionen, ett viktigt steg för att avgöra om svullnad eller lesioner ligger tillräckligt nära för att hota den centrala synen. Författarna menar att detta datacentrerade, anatomi-ledda angreppssätt kan komplettera framtida framsteg i nätverksdesign, och att liknande strategier kan gynna många andra områden inom medicinsk bildanalys där subtila strukturer måste hittas i komplexa, sjukliga landskap.
Citering: Chankhachon, S., Kansomkeat, S., Bhurayanontachai, P. et al. Contextual anatomy-guided deep learning for accurate fovea segmentation in diabetic retinopathy fundus images. Sci Rep 16, 10388 (2026). https://doi.org/10.1038/s41598-026-40287-y
Nyckelord: diabetisk retinopati, retinal bildtagning, fovea-segmentering, djupinlärning, medicinsk bildanalys