Clear Sky Science · de
Kontextuell anatomiegeführtes Deep Learning für präzise Foveasegmentierung in Fundusbildern bei diabetischer Retinopathie
Die Gefahr in diabetischen Augen erkennen
Für Millionen Menschen mit Diabetes kann ein kleiner Punkt im Zentrum der Netzhaut — die Fovea — den Unterschied zwischen klarem Sehen und dauerhaftem Sehverlust bedeuten. Ärzte nutzen bereits Farbfotografien des Augenhintergrunds (Fundusbilder), um auf diabetische Retinopathie zu screenen, eine führende Ursache vermeidbarer Erblindung. Die heutigen automatisierten Werkzeuge markieren die Fovea jedoch meist als einzelnen Punkt statt ihre tatsächliche Fläche zu umreißen, was Ärzte brauchen, um zu entscheiden, wer Injektionen benötigt, wer eine Laserbehandlung braucht und wer sicher abwarten kann. Diese Studie zeigt, wie eine neue datengesteuerte KI-Methode lernen kann, die Fovea eher so zu sehen wie ein Augenfacharzt — indem sie auf die gesamte anatomische Landschaft des Auges achtet statt nur auf die Fovea selbst. 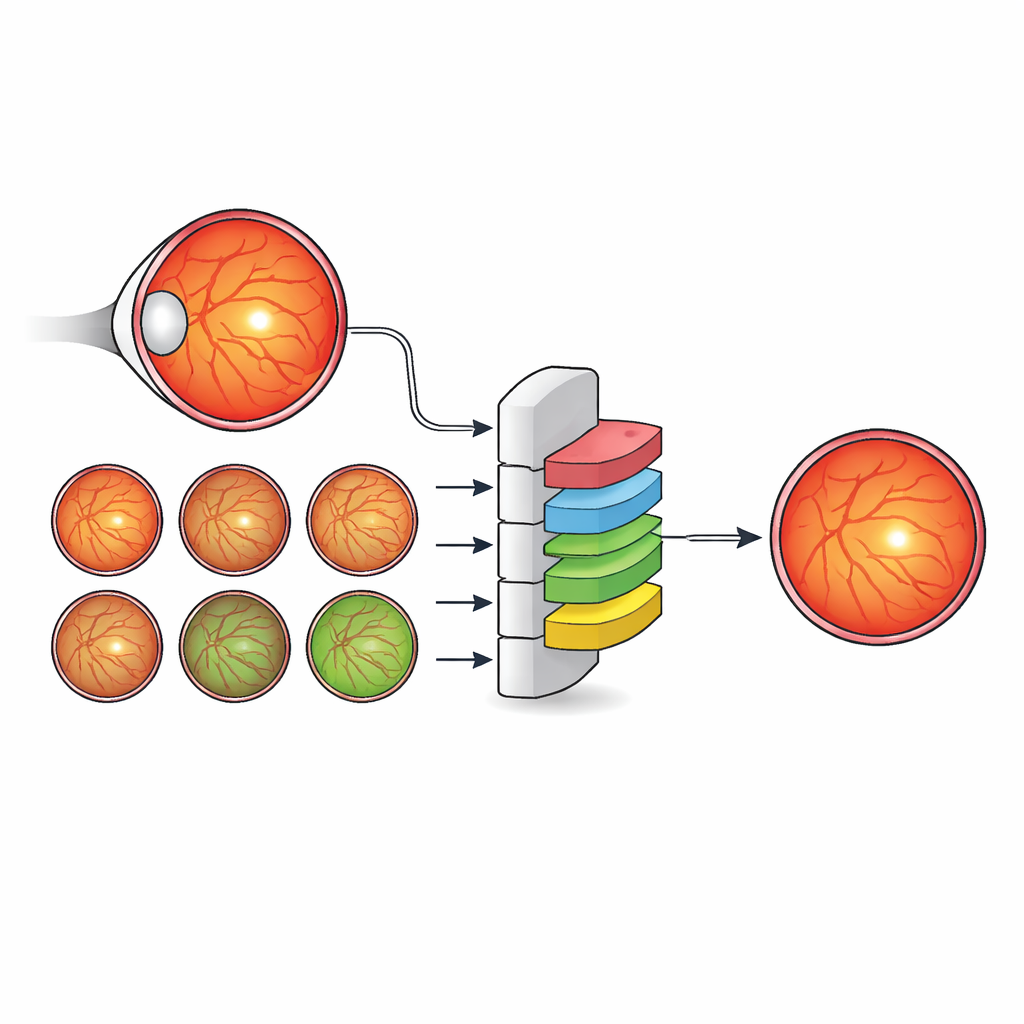
Warum die Fovea schwer abzugrenzen ist
Die Fovea ist eine winzige, flache Einsenkung in der Netzhaut, die uns scharfes zentrales Sehen und reichhaltige Farbwahrnehmung ermöglicht. Auf Fundusbildern sind ihre Ränder unscharf, ihr Erscheinungsbild variiert je nach Kamera, und Erkrankungen können sie weiter verschleiern. Traditionelle Computerverfahren stützten sich auf einfache Helligkeits- und Geometriereglen, die bei Läsionen oder schlechter Bildqualität schnell versagen. Neuere Deep-Learning-Systeme haben die Foveaerkennung verbessert, behandeln aber meist einzelne Augenstrukturen separat oder bauen auf zunehmend komplexere Netzwerkarchitekturen. Beide Ansätze übersehen oft eine grundlegende klinische Realität: Augenärzte suchen die Fovea nicht isoliert — sie nutzen Orientierungspunkte wie die Papille (Sehnervenkopf) und das Gefäßmuster, um zu erschließen, wo sich die Fovea befinden muss, selbst wenn sie schwer zu sehen ist.
Die KI das Augen-Navigationsschema lesen lehren
Die Autoren schlagen eine andere Strategie vor: Statt immer komplexere Netzwerke zu erfinden, ergänzen sie die Labels, mit denen ein standardisiertes, effizientes Modell trainiert wird. Sie erstellten einen neuen Datensatz, IDRiD-RETA-FV, in dem Augenfachärzte auf Pixelebene nicht nur die Fovea, sondern auch die Papille, die Blutgefäße, die gesamte Netzhaut und den Hintergrund sorgfältig markierten. Zwei Ophthalmologen folgten einem strikten Protokoll und erzielten nahezu perfekte Übereinstimmung bei diesen Markierungen, was eine robuste Referenz für das KI-System liefert. In diesen Datensatz integrierten sie MNv4Fovea, ein Segmentierungsmodell auf Basis einer weit verbreiteten Architektur, und trainierten es darauf, alle anatomischen Strukturen gleichzeitig zu segmentieren. Indem sie nach und nach mehr Kontext zu den Trainingslabels hinzufügten — zuerst nur Fovea versus Hintergrund, dann die Papille, dann die Netzhaut und schließlich die Gefäße — konnten sie direkt messen, wie sehr jede anatomische Komponente dem Modell hilft, die Fovea zu finden.
Wie Kontext und clevere Augmentation die Genauigkeit steigern
Die Ergebnisse zeigen: Kontext ist enorm wichtig. Lernt das Modell nur aus Fovea- und Hintergrund-Labels, identifiziert es etwas mehr als ein Viertel der fovealen Pixel korrekt. Die bloße Hinzunahme der Papille brachte nur mäßige Verbesserungen. Sobald jedoch die Netzhautkontur eingeschlossen wurde, stieg die Leistung deutlich, und mit den Gefäßen erhöhte sich die Fovea-Erkennung (Recall) auf über 90 Prozent. Anders ausgedrückt: Wenn das KI-Modell dieselbe Karte bekam, die Augenärzte verwenden — Papille, Gefäße und Netzhautgrenze — wurde es wesentlich besser darin, die Fovea zu begrenzen. Um das System über Bilder verschiedener Kameras robust zu machen, entwickelten die Forschenden außerdem eine neuartige Methode, Farbe und Helligkeit der Bilder zu variieren. Sie modellierten das Aussehen anderer öffentlicher Augendatensätze mit einer statistischen Verteilung, der Generalized Extreme Value (GEV)-Verteilung, und transformierten Trainingsbilder so, dass sie diese Stile nachahmten, dabei die Anatomie jedoch erhalten blieben. Diese GEV-basierte Augmentation verdoppelte nahezu die Rate erfolgreicher Fovea-Detektionen im Vergleich zu rein geometrischen Bildveränderungen.
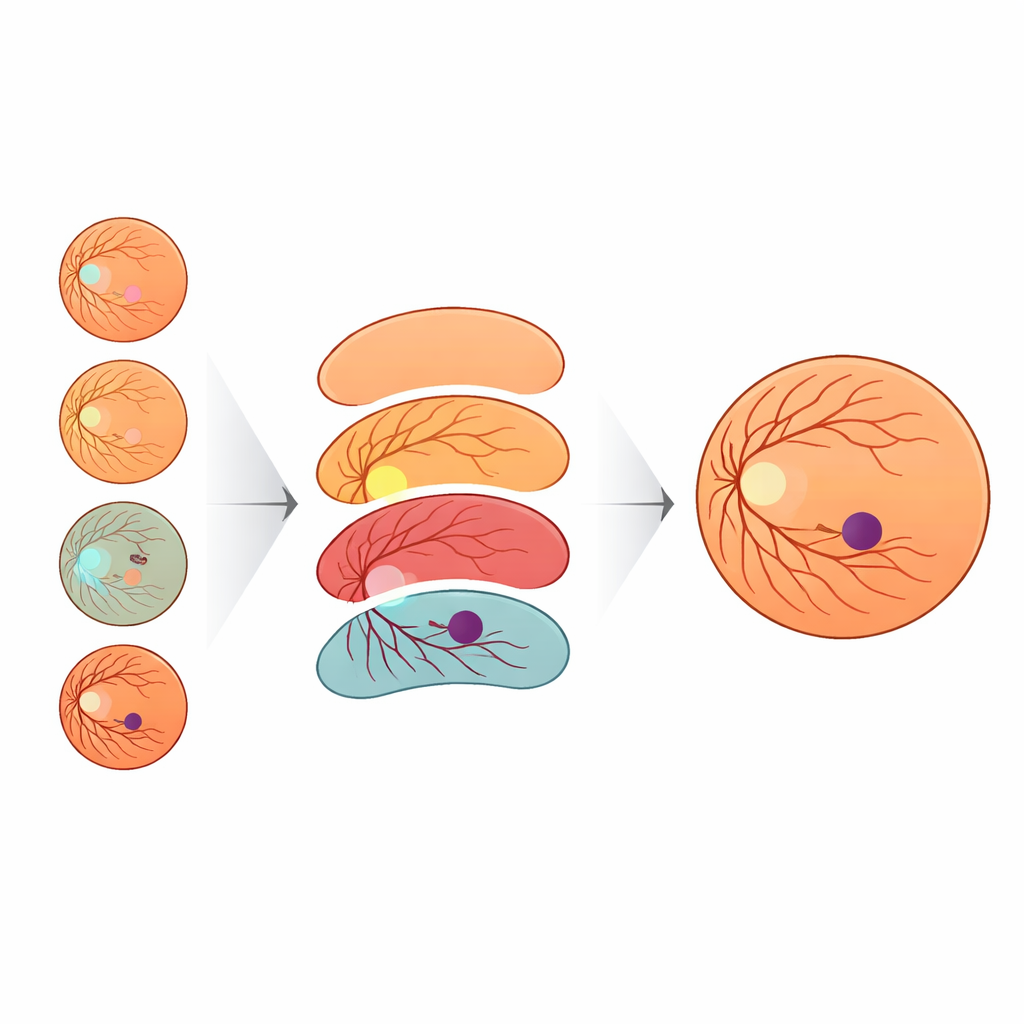
Nachgewiesene Wirksamkeit in vielen Datensätzen
MNv4Fovea wurde sowohl auf dem neuen, von Experten gelabelten Datensatz als auch auf mehreren bekannten öffentlichen Sammlungen retinaler Bilder getestet. Im hold-out Testsplit von IDRiD-RETA-FV erzielte es eine hohe Überlappung zwischen vorhergesagten und wahren fovealen Bereichen und lokalisierte das Foveazentrum bis auf wenige Pixel — im Grunde detektierte es die Fovea zuverlässig, wenn sie vorhanden war. Auf externen Datensätzen wie MESSIDOR, REFUGE, ARIA und MAPLES-DR erreichte das Modell vergleichbare oder bessere Ergebnisse gegenüber dem Stand der Technik hinsichtlich der Nähe seiner Foveavorhersagen zu Referenzpunkten. Interessanterweise wirkten sich die numerischen Werte in einigen Fällen moderat aus, weil die externen Datensätze „Fovea" unterschiedlich definierten — etwa durch Markierung einer breiten makulären Zone statt der winzigen klinischen Fovea — doch Expertenbewertungen zeigten, dass die Modellvorhersagen anatomisch sinnvoll waren und oft näher an der Fachmeinung lagen als an den ursprünglichen Labels.
Was das für Patientinnen, Patienten und künftige Werkzeuge bedeutet
Für Menschen mit Diabetes weist die Studie den Weg zu zuverlässigeren, breit einsetzbaren Screening-Werkzeugen, die mehr leisten, als nur einen Punkt auf der Netzhaut zu setzen. Indem MNv4Fovea aus dem vollständigen anatomischen Kontext lernt — Papille, Gefäße und Netzhautkontur — statt sich nur auf architektonische Tricks zu verlassen, kann es die foveale Region präzise abbilden, ein wichtiger Schritt, um zu entscheiden, ob Schwellungen oder Läsionen nahe genug sind, um das zentrale Sehen zu gefährden. Die Autoren argumentieren, dass dieser daten-zentrierte, anatomiegeführte Ansatz künftige Fortschritte in Netzwerkdesigns ergänzen kann und dass ähnliche Strategien vielen anderen Bereichen der medizinischen Bildgebung zugutekommen könnten, in denen subtile Strukturen in komplexen, erkrankten Landschaften gefunden werden müssen.
Zitation: Chankhachon, S., Kansomkeat, S., Bhurayanontachai, P. et al. Contextual anatomy-guided deep learning for accurate fovea segmentation in diabetic retinopathy fundus images. Sci Rep 16, 10388 (2026). https://doi.org/10.1038/s41598-026-40287-y
Schlüsselwörter: diabetische Retinopathie, retinale Bildgebung, Foveasegmentierung, Deep Learning, medizinische Bildanalyse