Clear Sky Science · fr
Apprentissage profond guidé par l’anatomie contextuelle pour une segmentation précise de la fovéa dans les images du fond d’œil en rétinopathie diabétique
Voir le danger dans les yeux diabétiques
Pour des millions de personnes atteintes de diabète, une petite zone au centre même de la rétine — la fovéa — peut faire la différence entre une vision nette et une perte de vision permanente. Les médecins utilisent déjà des photographies en couleur de l’arrière de l’œil (images du fond d’œil) pour dépister la rétinopathie diabétique, une cause majeure de cécité évitable. Mais les outils automatisés actuels localisent principalement la fovéa sous la forme d’un point unique plutôt que d’en délimiter la zone réelle, ce dont les cliniciens ont besoin pour décider qui nécessite des injections, qui doit recevoir un traitement au laser et qui peut attendre en toute sécurité. Cette étude montre comment une nouvelle méthode d’intelligence artificielle (IA) basée sur les données peut apprendre à détecter la fovéa de manière plus proche du raisonnement d’un spécialiste, en tenant compte de l’ensemble du paysage anatomique de l’œil plutôt que de la fovéa seule. 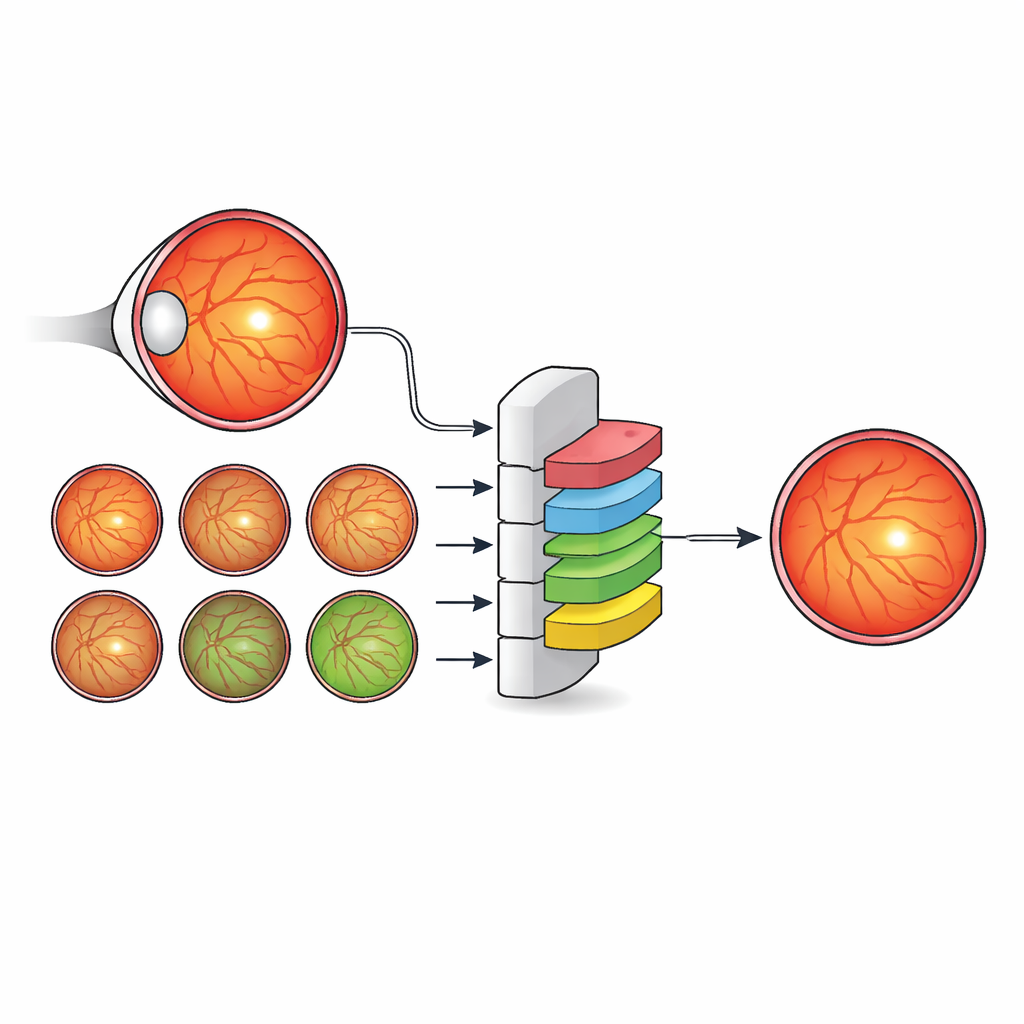
Pourquoi il est difficile de délimiter la fovéa
La fovéa est une petite dépression superficielle de la rétine qui nous fournit une vision centrale nette et une perception riche des couleurs. Sur les images du fond d’œil, ses contours sont flous, son apparence varie selon l’appareil photo, et la maladie peut encore les estomper. Les méthodes informatiques traditionnelles s’appuyaient sur des règles simples de luminosité et de géométrie, rapidement insuffisantes en présence de lésions ou d’une mauvaise qualité d’image. Les systèmes d’apprentissage profond récents ont amélioré la détection de la fovéa, mais ils traitent généralement chaque structure oculaire séparément ou reposent sur des architectures de réseau de plus en plus complexes. Ces deux approches négligent souvent une réalité clinique fondamentale : les ophtalmologistes ne recherchent pas la fovéa isolément — ils utilisent des repères comme le disque optique et le réseau vasculaire pour déduire où se situe la fovéa, même lorsqu’elle est difficile à voir.
Apprendre à l’IA à lire la carte routière de l’œil
Les auteurs proposent une stratégie différente : plutôt que d’inventer des architectures toujours plus complexes, ils enrichissent les annotations utilisées pour entraîner un modèle standard et efficace. Ils ont créé un nouveau jeu de données, IDRiD-RETA-FV, dans lequel des spécialistes de l’œil ont tracé au pixel près non seulement la fovéa, mais aussi le disque optique, les vaisseaux sanguins, la bordure de la rétine et l’arrière-plan. Deux ophtalmologistes ont suivi un protocole strict et sont parvenus à un accord quasi parfait sur ces marquages, fournissant un référentiel solide pour le système d’IA. Dans ce jeu de données, ils ont utilisé MNv4Fovea, un modèle de segmentation basé sur une architecture largement utilisée, mais entraîné pour segmenter toutes les structures anatomiques simultanément. En ajoutant progressivement plus de contexte aux annotations d’entraînement — d’abord seulement fovéa contre arrière-plan, puis en incluant le disque optique, ensuite la rétine, et enfin les vaisseaux — ils ont pu mesurer directement dans quelle mesure chaque élément anatomique aide le modèle à localiser la fovéa.
Comment le contexte et des augmentations astucieuses améliorent la précision
Les résultats montrent que le contexte compte énormément. Quand le modèle n’apprenait qu’à partir des étiquettes fovéa et arrière-plan, il identifiait correctement un peu plus d’un quart des pixels fovéaux. L’ajout simple du disque optique n’a apporté que des gains modestes. Mais dès que le contour de la rétine a été inclus, les performances ont nettement progressé, et l’ajout des vaisseaux a fait monter le rappel fovéal au-dessus de 90 %. Autrement dit, lorsque le modèle d’IA disposait de la même carte que les médecins — disque, vaisseaux et limite rétinienne — il devenait beaucoup meilleur pour délimiter la fovéa. Pour aider le système à fonctionner sur des images issues de caméras différentes, l’équipe a également développé une manière nouvelle de varier la couleur et la luminosité des images. Ils ont modélisé l’apparence d’autres jeux de données ophtalmiques publics à l’aide d’une loi statistique appelée loi des valeurs extrêmes généralisée (Generalized Extreme Value, GEV) et ont transformé les images d’entraînement pour imiter ces styles tout en préservant l’anatomie. Cette augmentation basée sur la GEV a presque doublé le taux de détections fovéales réussies comparée aux simples ajustements géométriques.
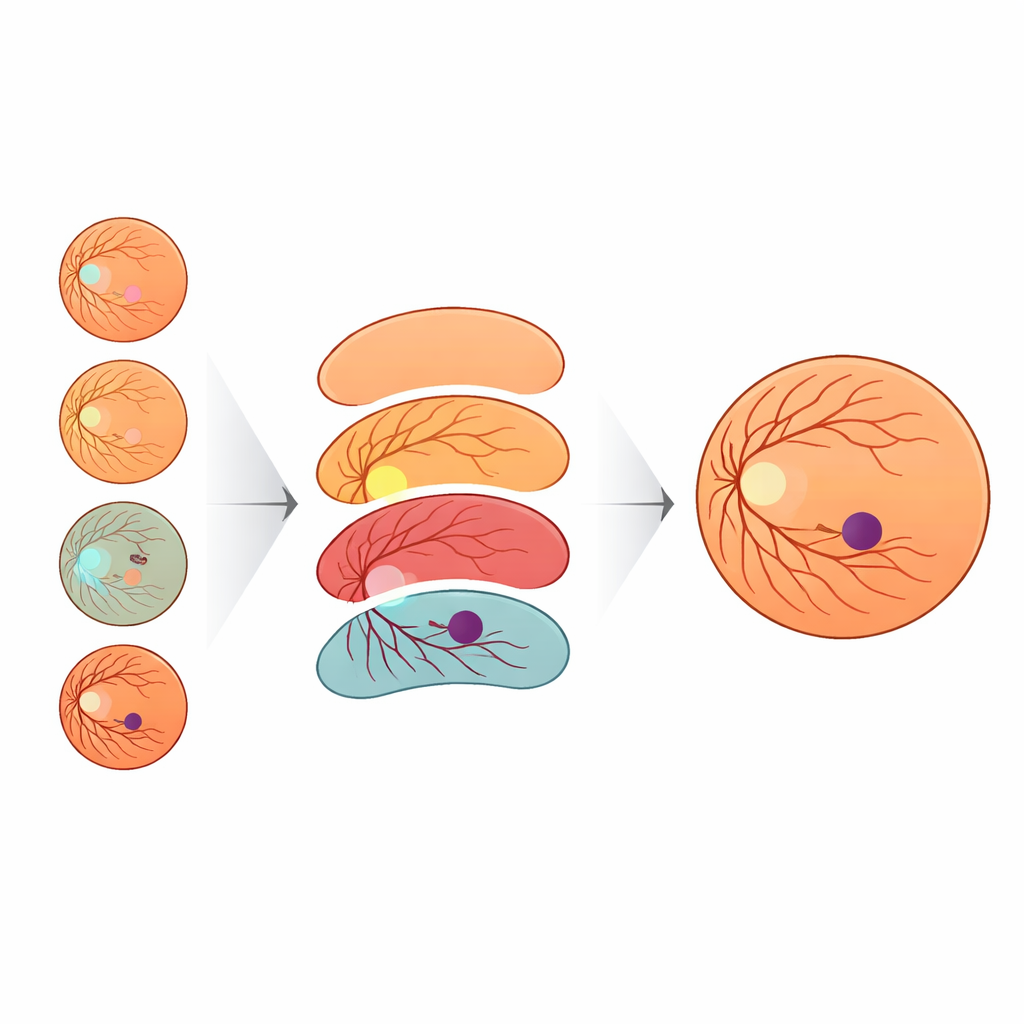
Preuve d’efficacité sur de nombreux jeux de données
MNv4Fovea a été testé à la fois sur le nouveau jeu de données annoté par des experts et sur plusieurs collections publiques bien connues d’images rétiniennes. Sur l’ensemble de test réservé d’IDRiD-RETA-FV, il a obtenu un fort recouvrement entre les régions fovéales prédites et réelles et a localisé le centre fovéal à quelques pixels près — détectant en pratique toujours la fovéa lorsqu’elle était présente. Sur des jeux de données externes tels que MESSIDOR, REFUGE, ARIA et MAPLES-DR, le modèle a égalé ou dépassé les méthodes de pointe en termes de proximité entre ses prédictions fovéales et les points de référence. Il est intéressant de noter que, dans certains cas, les scores numériques semblaient modestes parce que les jeux externes définissaient la « fovéa » différemment — par exemple en marquant une large zone maculaire plutôt que la petite fovéa clinique — mais l’examen par des spécialistes a montré que les prédictions du modèle étaient anatomiquement cohérentes et souvent plus proches de l’avis des experts que des annotations d’origine.
Ce que cela signifie pour les patients et les outils de demain
Pour les personnes vivant avec le diabète, l’étude met en lumière une voie vers des outils de dépistage plus fiables et largement déployables qui font plus que placer un point sur la rétine. En apprenant à partir du contexte anatomique complet — disque, vaisseaux et contour rétinien — plutôt qu’en comptant uniquement sur des astuces architecturales, MNv4Fovea peut cartographier précisément la région fovéale, une étape clé pour décider si un œdème ou des lésions sont suffisamment proches pour menacer la vision centrale. Les auteurs soutiennent que cette approche centrée sur les données et guidée par l’anatomie peut compléter les progrès futurs en conception de réseaux, et que des stratégies similaires pourraient bénéficier à de nombreux autres domaines de l’imagerie médicale où des structures subtiles doivent être repérées dans des paysages complexes et pathologiques.
Citation: Chankhachon, S., Kansomkeat, S., Bhurayanontachai, P. et al. Contextual anatomy-guided deep learning for accurate fovea segmentation in diabetic retinopathy fundus images. Sci Rep 16, 10388 (2026). https://doi.org/10.1038/s41598-026-40287-y
Mots-clés: rétinopathie diabétique, imagerie rétinienne, segmentation de la fovéa, apprentissage profond, analyse d’images médicales