Clear Sky Science · zh
用于资源高效氦氧语音识别的 LoRA 强化 Whisper
为什么水下的声音会变得奇怪
当潜水员在深海生活和工作时,他们通常吸入氦气与氧气的混合气体,而不是普通空气。这能保障安全,但也会让他们的声音听起来像卡通人物——音高变高、鼻音重且难以听清。在高压的饱和潜水环境中,人员可能在加压舱里停留数天或数周,任何对讲机中的误解都可能威胁到安全和任务成败。本研究着眼于一个简单但关键的问题:如何让计算机正确识别这些听起来奇怪的氦声,确保通信清晰可靠?
水下通话的挑战
深海饱和潜水用于水下施工、救援和资源勘探等工作。潜水员居住在与工作深度相匹配的金属加压舱中,呼吸一种称为 Heliox 的氦氧混合气体。氦气低密度改变了声音在声道中的传播方式:语音变得尖细,谐振峰移动,辅音变模糊,且通风风扇的持续嗡鸣带来强烈背景噪声。标准的语音识别系统在普通空气语音上训练,面对这种情形表现很差。它们经常听错词,难以识别专业术语,在声学条件极端时甚至完全失效。
构建逼真的深潜语音数据集
为以真实场景研究这一问题,研究者在一套安装在船上的实际饱和系统内录制了潜水员的语音。他们在两种工作条件下采集音频:相当于水下 12 米和 25 米深度,每种条件下氦氧比例都严格控制。麦克风连接到舱内对讲系统,保留了真实的背景噪声和回声。由于在这些条件下录音既困难又昂贵,每名潜水员仅提供了几分钟的原始语音。为让模型有足够的数据学习,团队用简易手段将训练数据扩增了十倍:拉伸和压缩语速、切割并重组片段、以及按不同强度混入海底噪声。关键是训练与测试使用了不同的潜水员,确保结果反映真实的泛化能力而非记忆化。
教会 AI 在不重头训练的情况下适配
作者没有从头构建新系统,而是以 Whisper 为起点——这是一个已经在海量多语言音频上训练好的开源大模型。直接把该模型应用到 Heliox 语音上,会产生很高的错误率,说明氦声与普通语音差别巨大。对 Whisper 进行全面重训练以适应小众的 Heliox 数据既浪费又昂贵,因此团队采用了一种称为低秩适配(LoRA)的技术。简单来说,LoRA 在模型关键部分添加一小段“旁路层”,同时冻结原始网络。仅对这小部分额外参数进行微调,用于专门的深海录音,使训练开销降到完整模型的约千分之五十,同时保留模型广泛的语言知识。
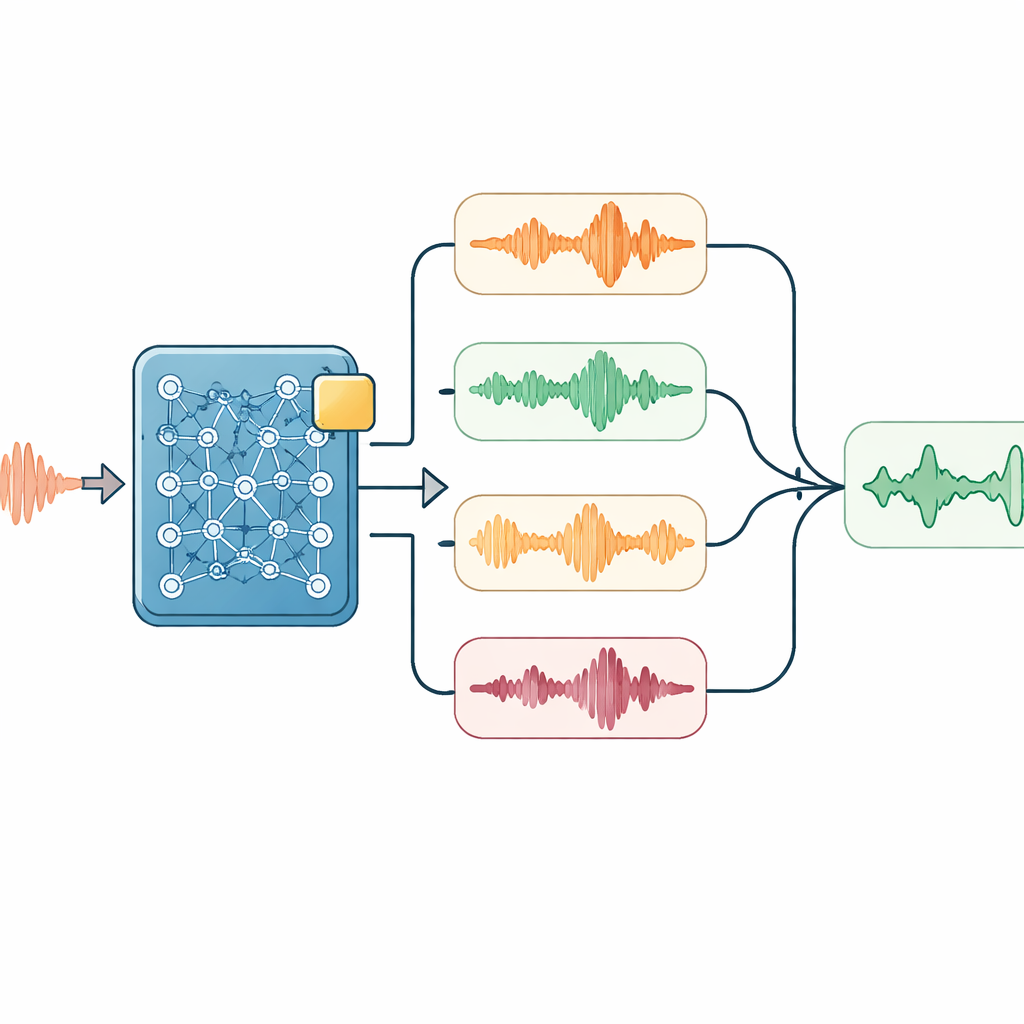
在解码时进行聪明的聆听
在这个适配后的模型之上,研究者叠加了若干只在系统“听写”时使用的轻量策略。其中一个模块在音频提示可能出现重要技术词(如设备名称)时,轻微偏向这些词。另一个模块以略微不同的播放速度运行音频并比较得到的转写,帮助弥合语速差异带来的问题。随后一个简单的语言模型对所有候选转写进行重评分,平衡与声音的匹配度、热词出现频率以及汉字序列的自然性。对于长段对话,系统还会将近期输出作为提示反馈到下一段,帮助保持主题连贯并避免在不合适的地方断句。
结果对潜水员安全的意义
在 12 米和 25 米录音上的测试表明,该方法显著提升了氦声的识别率。现成的 Whisper 模型错误率很高,但经过 LoRA 调整的版本将错误减少近一个数量级,同时只训练了极少量参数,并能在标准服务器上保持实用的运行时性能。附加的解码步骤——尤其是基于语言的重排序——在几乎不增加延迟的情况下进一步减少了错误,尽管诸如测试时增强之类更激进的技巧主要在对延迟要求不高时才更有帮助。这项工作表明,通过巧妙的适配和解码策略,现有大型语音模型可以被改造为对深海环境中潜水员来说既准确又资源高效的“听觉”工具,让水上与水下团队在关键时刻更容易互相理解。
引用: Mao, W., Gu, H., He, J. et al. LoRA-enhanced whisper for resource-efficient heliox speech recognition. Sci Rep 16, 14080 (2026). https://doi.org/10.1038/s41598-026-38201-7
关键词: 水下语音, 氦气音色, 语音识别, 饱和潜水, LoRA 适配