Clear Sky Science · nl
LoRA-verbeterde Whisper voor hulpbronefficiënt heliox-spraakherkenning
Waarom stemmen onder water vreemd klinken
Wanneer duikers diep onder de zee leven en werken, ademen ze vaak een mengsel van helium en zuurstof in plaats van normale lucht. Dat houdt hen veilig, maar het laat hun stemmen klinken als tekenfilmfiguren—hoog, nasaal en moeilijk te verstaan. In de krappe, risicovolle wereld van saturatieduiken, waar mensen dagen of weken in drukkamers verblijven, kan elke miscommunicatie via de intercom zowel de veiligheid als het slagen van de missie bedreigen. Deze studie pakt een eenvoudige maar vitale vraag aan: hoe krijgen we computers betrouwbare verstaanbaarheid van deze vreemd klinkende heliox-stemmen zodat communicatie helder en betrouwbaar blijft?
De uitdaging van praten onder de zee
Diepzeesaturatieduiken wordt gebruikt voor taken zoals onderwaterbouw, redding en hulpbronnenonderzoek. Duikers leven in metalen kamers die op druk worden gebracht om overeen te komen met de dieptes waarop ze werken, en ademen een helium–zuurstof gasmengsel dat bekendstaat als Heliox. De lage dichtheid van helium verandert hoe geluid door het vocale kanaal reist: spraak wordt piepend, met verschoven resonanties en vervaagde medeklinkers, en het constante gebrom van ventilatoren voegt zware achtergrondruis toe. Standaard spraakherkenningssystemen, getraind op alledaagse stemmen in lucht, presteren slecht in deze omgeving. Ze horen woorden verkeerd, worstelen met technische jargon en falen vaak helemaal wanneer de akoestische omstandigheden het extreemst zijn.
Een realistische dataset van diepduikstemmen opbouwen
Om dit probleem in realistische omstandigheden te bestuderen, namen de onderzoekers spraak van duikers op binnen een echte schipgebaseerde saturatiesysteem. Ze legden audio vast onder twee werkomstandigheden: het equivalent van 12 meter en 25 meter onder water, elk met zorgvuldig gecontroleerde helium- en zuurstofniveaus. Microfoons waren aangesloten op de intercom van de kamer, waardoor echte achtergrondgeluiden en echo’s bewaard bleven. Omdat opnemen onder deze omstandigheden moeilijk en duur is, leverde elke duiker slechts een paar minuten rauwe spraak. Om het computermodel genoeg materiaal te geven om van te leren, vergrootte het team de trainingsdata tienvoudig met eenvoudige technieken: het rekken en comprimeren van spreektempo, het knippen en opnieuw samenvoegen van segmenten, en het mengen van zeebodemgeluid op verschillende niveaus. Cruciaal was dat verschillende duikers werden gebruikt voor training en test, zodat de resultaten echte generalisatie laten zien en geen memorisatie.
Een AI leren zich aan te passen zonder vanaf nul te beginnen
In plaats van een nieuw systeem helemaal opnieuw te bouwen, begonnen de auteurs met Whisper, een groot open-source spraakherkenningsmodel dat al op enorme hoeveelheden meertalige audio was getraind. Het directe toepassen van dit model op Heliox-spraak leidde echter tot zeer hoge foutpercentages, wat laat zien hoe anders heliumstemmen zijn ten opzichte van normale spraak. Het volledig opnieuw trainen van Whisper op de niche Heliox-data zou verspilling en duur zijn, dus het team gebruikte een techniek genaamd low-rank adaptation (LoRA). Simpel gezegd voegt LoRA een zeer kleine "zijlaag" toe aan belangrijke delen van het model terwijl het originele netwerk bevroren blijft. Alleen deze kleine set extra parameters wordt afgestemd op de gespecialiseerde diepzeerecordings, waardoor de trainingsinspanning daalt tot ongeveer een halve procent van het volledige model terwijl de brede taalkennis behouden blijft.
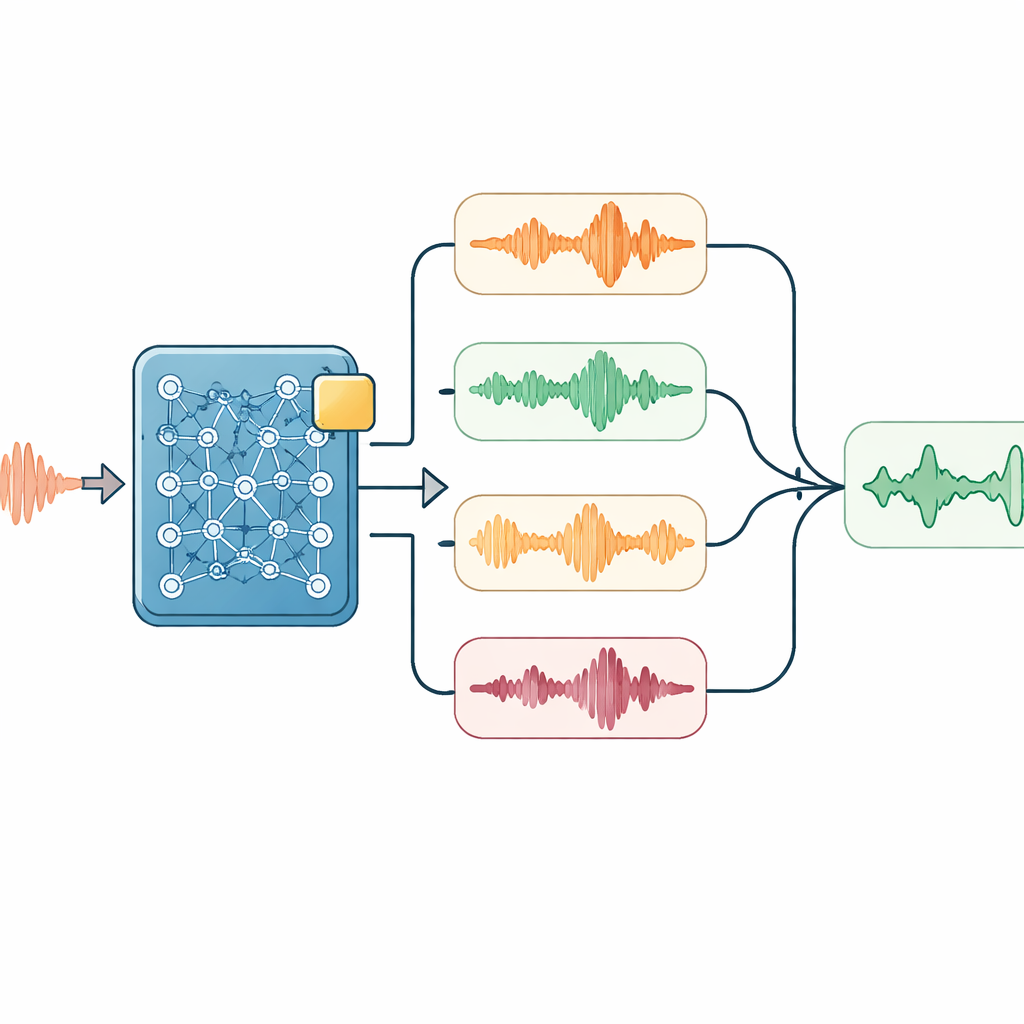
Slim luisteren tijdens decodering
Bovenop dit aangepaste model lagen de onderzoekers verschillende lichte trucs die alleen worden toegepast wanneer het systeem luistert en opschrijft wat het hoort. Eén module stuurt het systeem zachtjes in de richting van belangrijke technische woorden—zoals naamgevingen van apparatuur—wanneer de audio suggereert dat ze aanwezig zouden kunnen zijn. Een andere draait de audio op licht verschillende snelheden en vergelijkt de resulterende transcripties, wat helpt om eigenaardigheden in spreektempo glad te strijken. Een eenvoudig taalmodel her-scoort vervolgens alle kandidaat-transcripties, waarbij wordt afgewogen hoe goed ze passen bij de geluiden, hoe vaak hotwords voorkomen en hoe natuurlijk de tekenreeks in het Mandarijn eruitziet. Voor lange gesprekken voedt het systeem ook zijn recente output terug in het volgende segment als prompt, wat helpt om op onderwerp te blijven en te voorkomen dat zinnen op ongemakkelijke punten worden afgebroken.
Wat de resultaten betekenen voor de veiligheid van duikers
Tests op de 12-meter en 25-meter opnamen tonen aan dat deze aanpak de herkenning van heliumspraak dramatisch verbetert. Het kant-en-klare Whisper-model herkende een groot deel van de karakters verkeerd, maar de LoRA-afgestemde versie verminderde fouten met bijna een orde van grootte terwijl slechts een fractie van de parameters werd getraind en de runtime praktisch bleef op standaardservers. De toegevoegde decoderingstappen—vooral de taalgebaseerde her-rangschikking—verminderden fouten verder met weinig extra vertraging, hoewel meer agressieve trucs zoals test-time augmentatie vooral nuttig waren wanneer latentie minder kritisch was. Het werk toont aan dat met slimme adaptatie en decodering bestaande grote spraakmodellen kunnen worden omgevormd tot nauwkeurige, hulpbronefficiënte "oren" voor duikers in vijandige diepzeenomgevingen, waardoor het voor teams boven- en onderwater makkelijker wordt elkaar te verstaan wanneer het er echt toe doet.
Bronvermelding: Mao, W., Gu, H., He, J. et al. LoRA-enhanced whisper for resource-efficient heliox speech recognition. Sci Rep 16, 14080 (2026). https://doi.org/10.1038/s41598-026-38201-7
Trefwoorden: onderwaterspraak, heliumstem, spraakherkenning, saturatieduiken, LoRA-adaptatie