Clear Sky Science · sv
LoRA-förstärkt Whisper för resurssnål heliox-taligenkänning
Varför röster under vatten låter konstiga
När dykare bor och arbetar djupt under havsytan andas de ofta en blandning av helium och syre istället för vanlig luft. Det håller dem säkra, men gör att rösterna låter som tecknade figurer—höga, nasalare och svårare att förstå. I den trånga, riskfyllda världen av metningsdykning, där människor tillbringar dagar eller veckor i trycksatta kammare, kan missförstånd över intercomen hota både säkerhet och uppdragets framgång. Denna studie tar itu med en enkel men avgörande fråga: hur får vi datorer att korrekt förstå dessa ovanliga heliox-röster så att kommunikationen förblir tydlig och pålitlig?
Utmaningen att tala under havsytan
Djuphavsmetningsdykning används för uppgifter som undervattenskonstruktion, räddning och resursprospektering. Dykare bor i metalkammare som är trycksatta för att matcha de djup där de arbetar, och andas en helium–syre-blandning som kallas Heliox. Heliums låga densitet ändrar hur ljud fortplantas i talapparaten: talet blir pipigt, resonanser förskjuts och konsonanter suddas ut, samtidigt som det konstanta bruset från ventilationsfläktar lägger tung bakgrundsbrus. Standardmodeller för taligenkänning, tränade på vardagliga röster i luft, presterar dåligt i dessa miljöer. De feltolkar ord, har svårt med teknisk jargong och misslyckas ofta helt när de akustiska förhållandena är som mest extrema.
Bygga en realistisk datamängd för djuphavstal
För att studera problemet i verkliga förhållanden spelade forskarna in dykarnas tal inne i ett verkligt fartygsmonterat metningssystem. De fångade upp ljud under två arbetsförhållanden: motsvarande 12 respektive 25 meter under vattenytan, vardera med noggrant kontrollerade helium- och syrenivåer. Mikrofoner var kopplade till kammarens intercom, vilket bevarade verkligt bakgrundsbrus och eko. Eftersom inspelning under dessa förhållanden är knepigt och dyrt bidrog varje dykare bara med några minuters råtal. För att ge datorn tillräckligt med material att lära sig från utökade teamet träningsdata tiofaldigt med enkla trick: sträckning och komprimering av talhastighet, klippning och ihopmontering av segment, samt mixning med bottenljud på olika nivåer. Avgörande var att olika dykare användes för träning och test så att resultaten skulle återspegla verklig generalisering, inte memorering.
Att lära en AI att anpassa sig utan att börja om från början
I stället för att bygga ett nytt system från grunden startade författarna med Whisper, en stor öppen källkod-modell för taligenkänning redan tränad på enorma mängder flerspråkigt ljud. Att applicera denna modell direkt på Heliox-tal gav dock mycket höga felnivåer, vilket visar hur annorlunda heliumröster är jämfört med normalt tal. Att helt träna om Whisper på den nischade Heliox-datan vore slösaktigt och kostsamt, så teamet vände sig till en teknik som kallas low-rank adaptation (LoRA). Enkelt uttryckt lägger LoRA till ett mycket litet ”sidolager” på viktiga delar av modellen samtidigt som det ursprungliga nätverket fryses. Endast denna lilla uppsättning extra parametrar justeras på de specialiserade djuphavsinspelningarna, vilket minskar träninginsatsen till ungefär en halv procent av hela modellen samtidigt som dess breda språkkunskap bevaras.
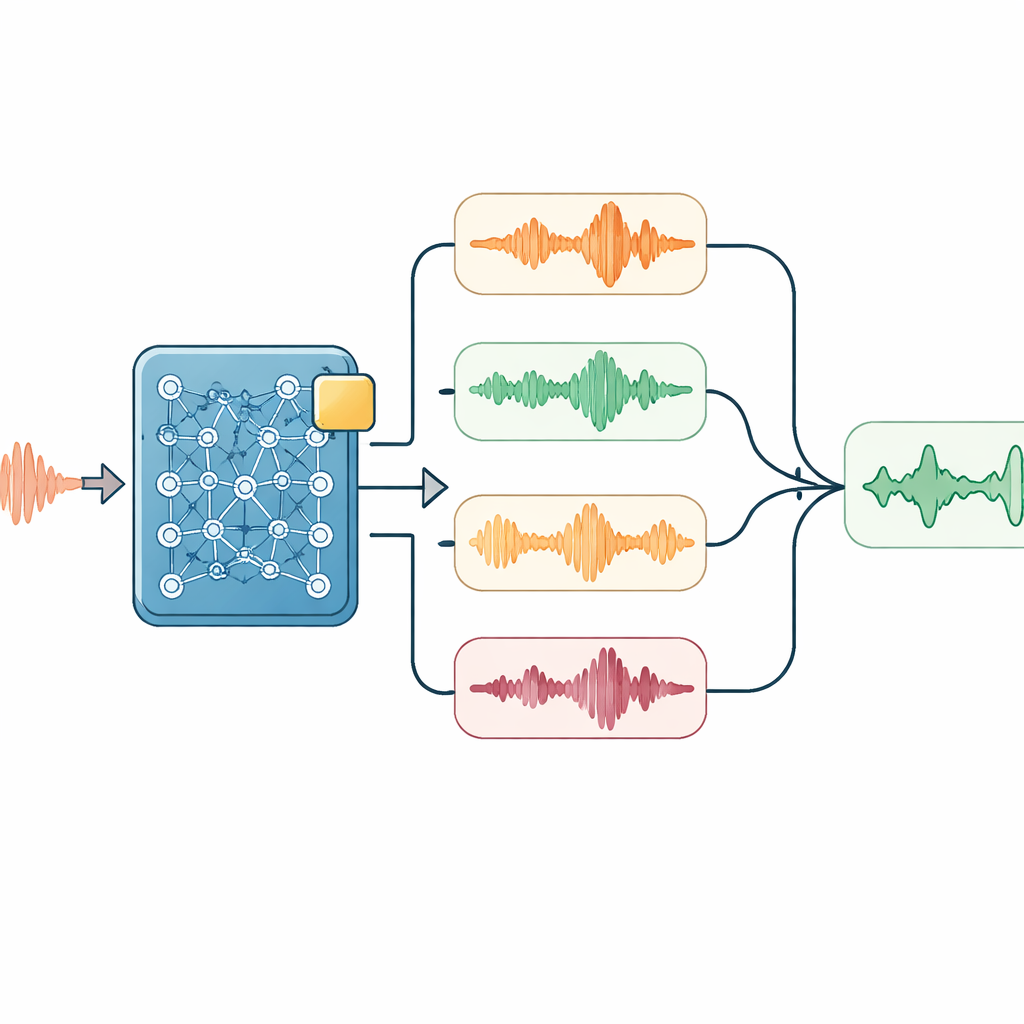
Smart lyssnande vid avkodning
Ovanpå denna anpassade modell lade forskarna flera lätta trick som används endast när systemet lyssnar och transkriberar. En modul skjuter försiktigt systemet mot att favorisera viktiga tekniska ord—som namn på utrustning—när ljudet antyder att de kan förekomma. En annan kör ljudet i något olika hastigheter och jämför de resulterande transkriptionerna, vilket hjälper till att jämna ut avvikelser i talhastighet. En enkel språkmodell ompoängsätter sedan alla kandidattranskriptioner, och väger hur väl de passar ljudet, hur ofta nyckelord förekommer och hur naturlig teckenföljden ser ut på mandarin. För långa samtal matar systemet också tillbaka sin senaste utskrift till nästa segment som en prompt, vilket hjälper det att hålla sig till ämnet och undvika att dela upp meningar på olämpliga ställen.
Vad resultaten betyder för dykarsäkerhet
Tester på inspelningarna från 12 och 25 meter visar att denna metod dramatiskt förbättrar igenkänningen av heliumtal. Den färdiga Whisper-modellen feligenkände en stor andel tecken, men den LoRA-finkalibrerade versionen minskade felen med nästan en tiopotens samtidigt som bara en bråkdel av parametrarna tränades och drifttiden hölls praktisk på vanliga servrar. De tillagda avkodningsstegen—särskilt språkbaserad omrankning—minskade ytterligare felen med liten extra fördröjning, även om mer aggressiva trick som test-tidsaugmentering var mest användbara när latens var mindre kritiskt. Arbetet visar att med smart anpassning och avkodning kan befintliga stora talmodeller formas om till noggranna, resurssnåla ”öron” för dykare i fientliga djuphavsmiljöer, vilket gör det lättare för besättningar ovan och under ytan att förstå varandra när det är som viktigast.
Citering: Mao, W., Gu, H., He, J. et al. LoRA-enhanced whisper for resource-efficient heliox speech recognition. Sci Rep 16, 14080 (2026). https://doi.org/10.1038/s41598-026-38201-7
Nyckelord: underwater speech, helium voice, speech recognition, saturation diving, LoRA adaptation