Clear Sky Science · es
Whisper mejorado con LoRA para reconocimiento de voz Heliox eficiente en recursos
Por qué las voces submarinas suenan extrañas
Cuando los buceadores viven y trabajan en profundidad bajo el mar, a menudo respiran una mezcla de helio y oxígeno en lugar del aire normal. Esto les mantiene a salvo, pero hace que sus voces suenen como personajes de dibujos animados: agudas, nasales y difíciles de entender. En el mundo cerrado y arriesgado de la inmersión por saturación, donde las personas pasan días o semanas en cámaras presurizadas, cualquier malentendido por el intercomunicador puede poner en peligro tanto la seguridad como el éxito de la misión. Este estudio aborda una cuestión simple pero vital: ¿cómo lograr que las máquinas entiendan con precisión estas voces extrañas para mantener la comunicación clara y fiable?
El reto de hablar bajo el mar
La inmersión por saturación en aguas profundas se utiliza para tareas como construcción submarina, rescate y exploración de recursos. Los buceadores viven en cámaras metálicas presurizadas para igualar las profundidades en las que trabajan, respirando una mezcla de helio y oxígeno conocida como Heliox. La baja densidad del helio altera cómo se propaga el sonido en el tracto vocal: el habla se vuelve chillona, con resonancias desplazadas y consonantes difusas, y el zumbido constante de los ventiladores de ventilación añade un fuerte ruido de fondo. Los sistemas estándar de reconocimiento de voz, entrenados con voces cotidianas en aire, rinden mal en este entorno. Confunden palabras, tienen problemas con la jerga técnica y a menudo fallan por completo cuando las condiciones acústicas son más extremas.
Construir un conjunto de datos realista de voces de buceo profundo
Para estudiar este problema de forma realista, los investigadores grabaron el habla de buceadores dentro de un sistema de saturación montado en un barco. Capturaron audio en dos condiciones de trabajo: el equivalente a 12 metros y 25 metros de profundidad, cada una con niveles de helio y oxígeno cuidadosamente controlados. Los micrófonos estaban conectados al intercomunicador de la cámara, preservando el ruido real de fondo y las reverberaciones. Dado que grabar en estas condiciones es difícil y caro, cada buceador aportó solo unos pocos minutos de habla en bruto. Para proporcionar al modelo computacional suficiente material para aprender, el equipo amplió los datos de entrenamiento diez veces usando trucos sencillos: alargar y comprimir la velocidad del habla, cortar y recombinar segmentos y mezclar ruido del lecho marino a distintos niveles. De forma crucial, se emplearon buceadores diferentes para el entrenamiento y las pruebas, de modo que los resultados reflejaran una verdadera generalización y no memorización.
Enseñar a una IA a adaptarse sin empezar desde cero
En lugar de construir un sistema nuevo desde cero, los autores partieron de Whisper, un gran modelo de reconocimiento de voz de código abierto ya entrenado con ingentes cantidades de audio multilingüe. Aplicar directamente este modelo al habla Heliox, sin embargo, condujo a tasas de error muy altas, lo que evidencia lo diferentes que son las voces con helio respecto al habla normal. Volver a entrenar por completo Whisper con los datos específicos de Heliox sería costoso y poco eficiente, por lo que el equipo recurrió a una técnica llamada adaptación de baja jerarquía (LoRA). En términos sencillos, LoRA añade una pequeña “capa lateral” en partes clave del modelo mientras se congela la red original. Solo este reducido conjunto de parámetros adicionales se ajusta con las grabaciones especializadas del fondo marino, reduciendo el esfuerzo de entrenamiento a aproximadamente medio por ciento del modelo completo y preservando al mismo tiempo su amplio conocimiento lingüístico.
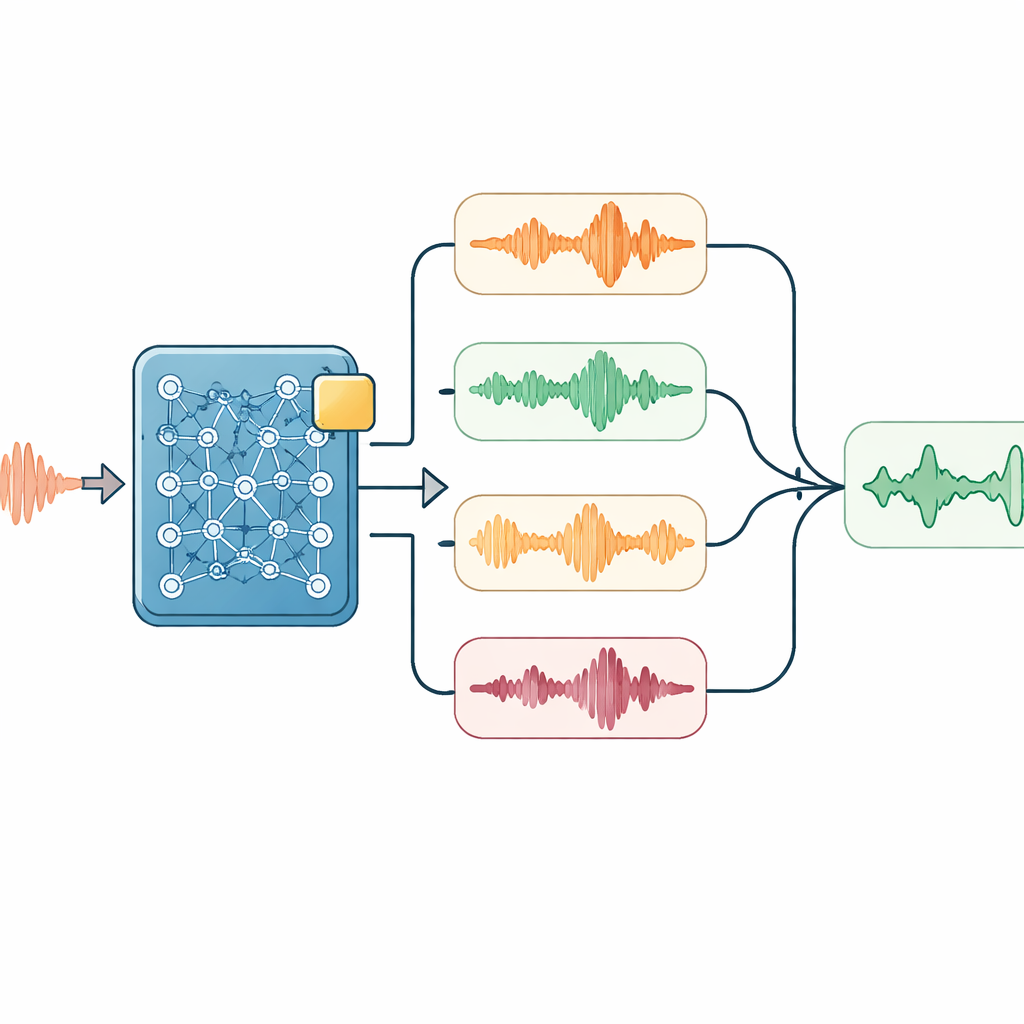
Escucha inteligente en el momento de la decodificación
Sobre este modelo adaptado, los investigadores añadieron varios trucos ligeros usados solo cuando el sistema escucha y transcribe. Un módulo orienta suavemente al sistema para favorecer palabras técnicas importantes—como nombres de equipos—si el audio sugiere que podrían estar presentes. Otro reproduce el audio a velocidades ligeramente diferentes y compara las transcripciones resultantes, ayudando a suavizar las peculiaridades de la tasa de habla. Un modelo de lenguaje sencillo vuelve a puntuar todas las transcripciones candidatas, equilibrando cuánto coinciden con los sonidos, la frecuencia de aparición de palabras clave y lo natural que resulta la secuencia de caracteres en mandarín. Para conversaciones largas, el sistema también reintroduce su salida reciente en el siguiente segmento como prompt, ayudando a mantener el tema y a evitar cortar frases en puntos incómodos.
Qué significan los resultados para la seguridad de los buceadores
Las pruebas con las grabaciones de 12 y 25 metros muestran que este enfoque mejora drásticamente el reconocimiento del habla con helio. El modelo Whisper sin adaptar confundía una gran fracción de caracteres, pero la versión ajustada con LoRA redujo los errores casi por un orden de magnitud mientras entrenaba solo una ínfima parte de los parámetros y mantenía tiempos de ejecución prácticos en servidores estándares. Los pasos adicionales de decodificación—especialmente la reordenación basada en el lenguaje—recortaron aún más los errores con poca latencia añadida, aunque trucos más agresivos como la aumentación en tiempo de prueba fueron útiles principalmente cuando la latencia era menos crítica. El trabajo demuestra que con adaptación y decodificación ingeniosas, los grandes modelos de voz existentes pueden convertirse en “oídos” precisos y eficientes en recursos para buceadores en entornos hostiles de aguas profundas, facilitando que las tripulaciones en superficie y en profundidad se entiendan cuando más importa.
Cita: Mao, W., Gu, H., He, J. et al. LoRA-enhanced whisper for resource-efficient heliox speech recognition. Sci Rep 16, 14080 (2026). https://doi.org/10.1038/s41598-026-38201-7
Palabras clave: voz submarina, voz con helio, reconocimiento de voz, inmersión por saturación, adaptación LoRA