Clear Sky Science · pl
Whisper z adaptacją LoRA do wydajnego rozpoznawania mowy w heloksie
Dlaczego głosy pod wodą brzmią dziwnie
Gdy nurkowie pracują głęboko pod powierzchnią, często oddychają mieszaniną helu i tlenu zamiast zwykłego powietrza. To zapewnia bezpieczeństwo, ale sprawia, że ich głosy brzmią jak postacie z kreskówki — wysokie, nosowe i trudne do zrozumienia. W ciasnym, ryzykownym świecie nurkowania saturacyjnego, gdzie ludzie spędzają dni lub tygodnie w komorach pod ciśnieniem, każde nieporozumienie przez interkom może zagrażać bezpieczeństwu i powodzeniu misji. Ten artykuł zajmuje się prostym, ale kluczowym pytaniem: jak sprawić, by komputery poprawnie rozumiały te nietypowe helowe głosy, tak aby komunikacja pozostała jasna i niezawodna?
Wyzwaniem jest mówienie pod wodą
Głębokie nurkowanie saturacyjne stosuje się przy zadaniach takich jak prace podwodne, akcje ratunkowe i poszukiwanie surowców. Nurkowie mieszkają w metalowych komorach dopasowanych ciśnieniem do głębokości pracy, oddychając mieszaniną helu i tlenu znaną jako heloks. Niska gęstość helu zmienia sposób, w jaki dźwięk rozchodzi się w drogach głosowych: mowa staje się piskliwa, rezonanse przesuwają się, a spółgłoski tracą wyrazistość, do tego dochodzi stały szum wentylatorów. Standardowe systemy rozpoznawania mowy, trenowane na zwykłych głosach w powietrzu, radzą sobie tu słabo. Błędnie rozpoznają słowa, mają problem ze specjalistycznym żargonem i często zawodzą, gdy warunki akustyczne są najbardziej ekstremalne.
Budowanie realistycznego zbioru głosów do nurkowania
Aby zbadać problem w realistycznych warunkach, badacze zarejestrowali głosy nurków wewnątrz rzeczywistego okrętowego systemu saturacyjnego. Nagrania wykonano w dwóch warunkach roboczych: odpowiadających 12 i 25 metrom pod wodą, z precyzyjnie kontrolowanymi poziomami helu i tlenu. Mikrofony podłączono do interkomu komory, zachowując rzeczywisty szum tła i pogłos. Ponieważ nagrywanie w takich warunkach jest trudne i kosztowne, każdy nurek dostarczył tylko kilka minut surowej mowy. Aby dać modelowi wystarczająco dużo materiału do nauki, zespół powiększył dane treningowe dziesięciokrotnie, stosując proste zabiegi: spowalnianie i przyspieszanie tempa mowy, cięcie i ponowne składanie fragmentów oraz doklejanie odgłosów dna morskiego na różnych poziomach głośności. Kluczowe było użycie różnych nurków do treningu i testów, aby wyniki odzwierciedlały rzeczywistą zdolność uogólniania, a nie zapamiętywanie.
Nauka adaptacji AI bez zaczynania od zera
Zamiast budować nowy system od podstaw, autorzy zaczęli od Whispera — dużego otwartego modelu rozpoznawania mowy przetrenowanego na ogromnych zbiorach wielojęzycznego audio. Bezpośrednie zastosowanie tego modelu do mowy heloksowej dało jednak bardzo wysoki poziom błędów, co pokazało, jak bardzo głosy helowe różnią się od zwykłej mowy. Pełne ponowne trenowanie Whispera na niszowych danych heloksowych byłoby marnotrawne i kosztowne, dlatego zespół sięgnął po technikę zwaną niskorankową adaptacją (LoRA). W prostych słowach, LoRA dodaje bardzo małą „warstwę boczną” do kluczowych części modelu, podczas gdy oryginalna sieć pozostaje zamrożona. Tylko ten niewielki zbiór dodatkowych parametrów jest dostrajany na specjalistycznych nagraniach z głębin, redukując wysiłek treningowy do około pół procenta pełnego modelu, przy zachowaniu jego szerokiej wiedzy językowej.
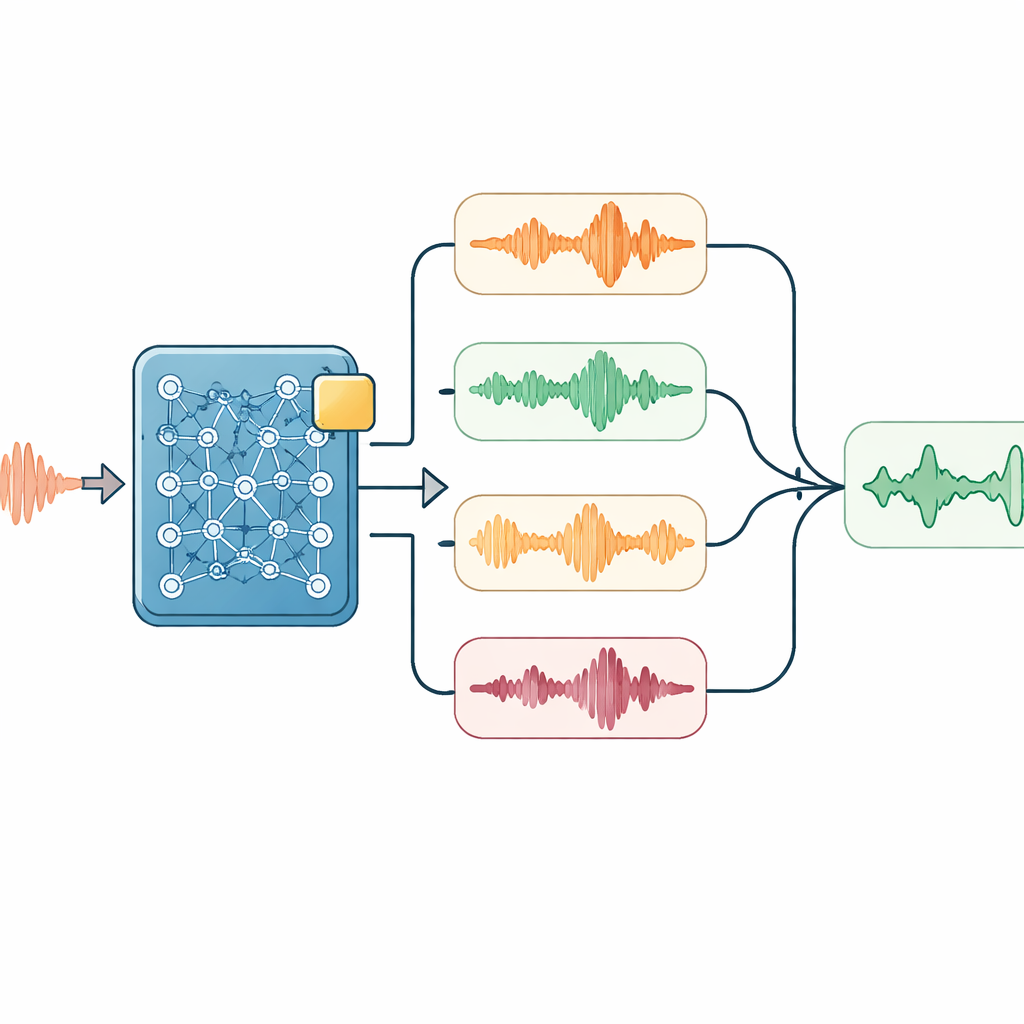
Sprytne słuchanie w trakcie dekodowania
Na bazie tego zaadaptowanego modelu badacze dodali kilka lekkich trików stosowanych jedynie podczas nasłuchu i zapisu rozpoznanej mowy. Jeden moduł delikatnie faworyzuje ważne słowa techniczne — na przykład nazwy urządzeń — gdy tylko dźwięk sugeruje ich obecność. Inny odtwarza audio w nieco różnych prędkościach i porównuje powstałe transkrypcje, co pomaga wygładzać różnice w tempie mowy. Prosty model językowy następnie ponownie punktuje wszystkie kandydatów transkrypcji, równoważąc dopasowanie do dźwięków, występowanie słów kluczowych oraz naturalność ciągu znaków w mandaryńskim. Dla dłuższych rozmów system wprowadza też swoje niedawne wyniki jako podpowiedź do następnego segmentu, co pomaga utrzymać kontekst i unikać łamania zdań w nieodpowiednich miejscach.
Co wyniki oznaczają dla bezpieczeństwa nurków
Testy na nagraniach z 12 i 25 metrów pokazują, że to podejście znacząco poprawia rozpoznawanie mowy heloksowej. Gotowy model Whisper błędnie rozpoznawał znaczną część znaków, ale wersja dostrojona z użyciem LoRA zmniejszyła liczbę błędów niemal rzędu wielkości, trenując przy tym tylko niewielki ułamek parametrów i zachowując praktyczny czas działania na standardowych serwerach. Dodatkowe kroki dekodowania — zwłaszcza ponowne ocenianie oparte na modelu językowym — dodatkowo redukowały pomyłki przy niewielkim wzroście opóźnienia, chociaż bardziej agresywne sztuczki, takie jak augmentacja w czasie testu, okazywały się przydatne głównie gdy opóźnienie nie było krytyczne. Praca pokazuje, że dzięki sprytnej adaptacji i dekodowaniu istniejące duże modele mowy można przekształcić w dokładne, oszczędne „uszy” dla nurków w wrogich warunkach głębin, ułatwiając załogom nad i pod powierzchnią porozumiewanie się wtedy, gdy ma to największe znaczenie.
Cytowanie: Mao, W., Gu, H., He, J. et al. LoRA-enhanced whisper for resource-efficient heliox speech recognition. Sci Rep 16, 14080 (2026). https://doi.org/10.1038/s41598-026-38201-7
Słowa kluczowe: mowa podwodna, głos helowy, rozpoznawanie mowy, nurkowanie saturacyjne, adaptacja LoRA