Clear Sky Science · it
Whisper potenziato con LoRA per il riconoscimento vocale Heliox efficiente in risorse
Perché le voci sott'acqua suonano strane
Quando i sub vivono e lavorano in profondità, spesso respirano una miscela di elio e ossigeno invece dell'aria normale. Questo li protegge, ma rende le loro voci simili a personaggi dei cartoni: acute, nasali e difficili da comprendere. Nel contesto ristretto e rischioso dell'immersione in saturazione, dove le persone trascorrono giorni o settimane in camere pressurizzate, ogni incomprensione tramite l'interfono può mettere in pericolo sia la sicurezza che il successo della missione. Questo studio affronta una domanda semplice ma vitale: come possiamo far sì che i computer capiscano con precisione queste voci alterate dall'elio, in modo che la comunicazione resti chiara e affidabile?
La sfida di parlare sott'acqua
L'immersione in saturazione profonda viene impiegata per compiti come costruzioni subacquee, soccorso ed esplorazione di risorse. I sub vivono in camere metalliche pressurizzate per corrispondere alle profondità in cui lavorano, respirando una miscela elio–ossigeno nota come Heliox. La bassa densità dell'elio altera la propagazione del suono nel tratto vocale: il parlato diventa acuto, con risonanze spostate e consonanti sfocate, e il ronzio costante dei ventilatori aggiunge un forte rumore di fondo. I sistemi di riconoscimento vocale standard, addestrati su voci quotidiane in aria, funzionano male in questo contesto. Interpretano male le parole, hanno difficoltà con il gergo tecnico e spesso non funzionano affatto nelle condizioni acustiche più estreme.
Costruire un dataset realistico di voci da immersione profonda
Per studiare il problema in modo realistico, i ricercatori hanno registrato il parlato dei sub all’interno di un reale sistema di saturazione montato su una nave. Hanno acquisito audio in due condizioni operative: l’equivalente di 12 metri e 25 metri sott'acqua, ciascuna con livelli di elio e ossigeno controllati con cura. I microfoni erano collegati all’interfono della camera, preservando il rumore di fondo reale e gli echi. Poiché registrare in queste condizioni è difficile e costoso, ogni sub ha fornito solo pochi minuti di parlato grezzo. Per dare al modello materiale sufficiente per apprendere, il team ha moltiplicato i dati di addestramento per dieci usando semplici stratagemmi: rallentare o accelerare il parlato, tagliare e ricombinare segmenti e miscelare rumori del fondale marino a livelli diversi. È stato inoltre cruciale usare sub differenti per l’addestramento e per il test, in modo che i risultati riflettessero vera generalizzazione e non semplice memorizzazione.
Insegnare a un'IA ad adattarsi senza ricominciare da zero
Invece di costruire un nuovo sistema da zero, gli autori hanno iniziato con Whisper, un grande modello open-source di riconoscimento vocale già addestrato su enormi quantità di audio multilingue. Applicare direttamente questo modello al parlato Heliox, tuttavia, ha portato a tassi di errore molto elevati, dimostrando quanto le voci con elio si discostino dal parlato normale. Riaddestrare completamente Whisper sui dati specifici Heliox sarebbe stato dispendioso e costoso, così il team ha usato una tecnica chiamata adattamento a basso rango (LoRA). In termini semplici, LoRA aggiunge una piccola “sovrastruttura” a basso costo in punti chiave del modello mantenendo congelata la rete originale. Solo questo ridottissimo insieme di parametri viene ottimizzato sulle registrazioni profonde specializzate, riducendo l'impegno di addestramento a circa la metà di un percento del modello completo e preservando al contempo la sua ampia conoscenza linguistica.
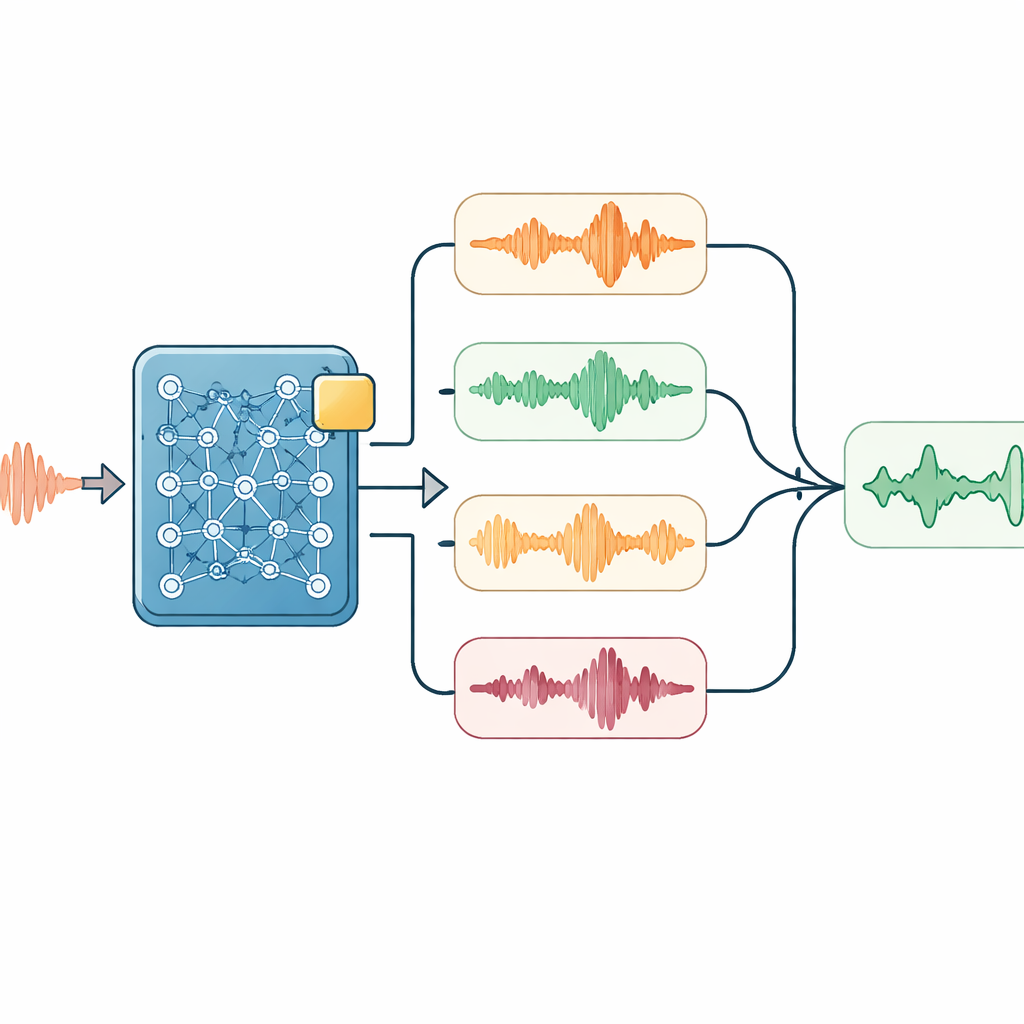
Ascolto intelligente in fase di decodifica
Sopra questo modello adattato, i ricercatori hanno applicato diversi trucchi leggeri usati solo quando il sistema ascolta e trascrive. Un modulo spinge delicatamente il sistema a preferire parole tecniche importanti — come nomi di apparecchiature — ogni volta che l’audio suggerisce la loro presenza. Un altro esegue l’audio a velocità leggermente diverse e confronta le trascrizioni ottenute, aiutando a compensare le variazioni di velocità di parola. Un semplice modello linguistico poi ririordina le trascrizioni candidate, bilanciando quanto bene corrispondono ai suoni, la frequenza di comparsa delle parole chiave e quanto naturale appare la sequenza di caratteri in mandarino. Per conversazioni lunghe, il sistema rialimenta anche le sue ultime trascrizioni nel segmento successivo come prompt, aiutandolo a restare sul tema ed evitare di spezzare frasi in punti scomodi.
Cosa significano i risultati per la sicurezza dei sommozzatori
I test sulle registrazioni a 12 e 25 metri mostrano che questo approccio migliora drasticamente il riconoscimento del parlato con elio. Il modello Whisper fuori dalla scatola interpretava male una grande frazione di caratteri, ma la versione sintonizzata con LoRA ha ridotto gli errori di quasi un ordine di grandezza addestrando solo una porzione minima dei parametri e mantenendo tempi di esecuzione pratici su server standard. I passaggi di decodifica aggiuntivi — in particolare il ri-ranking basato sul linguaggio — hanno ulteriormente ridotto gli errori con pochissimo ritardo aggiuntivo, anche se trucchi più aggressivi come l’augmentazione a test-time sono stati utili soprattutto quando la latenza era meno critica. Il lavoro dimostra che con adattamenti e tecniche di decodifica intelligenti, i grandi modelli vocali esistenti possono essere rimodellati in “orecchie” accurate ed efficienti in termini di risorse per i sommozzatori in ambienti ostili del profondo mare, facilitando la comprensione reciproca tra equipaggi sopra e sotto la superficie nei momenti che contano di più.
Citazione: Mao, W., Gu, H., He, J. et al. LoRA-enhanced whisper for resource-efficient heliox speech recognition. Sci Rep 16, 14080 (2026). https://doi.org/10.1038/s41598-026-38201-7
Parole chiave: voce subacquea, voce con elio, riconoscimento vocale, immersione in saturazione, adattamento LoRA