Clear Sky Science · de
Mit LoRA verbessertes Whisper für ressourceneffiziente Heliox-Spracherkennung
Warum Stimmen unter Wasser seltsam klingen
Wenn Taucher tief unter der Meeresoberfläche leben und arbeiten, atmen sie oft eine Mischung aus Helium und Sauerstoff statt normaler Luft. Das schützt sie, verändert aber ihre Stimmen zu cartoonhaften Lauten – hoch, nasal und schwer verständlich. In der beengten, risikoreichen Welt des Sättigungstauchens, in der Menschen Tage oder Wochen in druckbeaufschlagten Kammern verbringen, kann jedes Missverständnis über das Interkom die Sicherheit und den Erfolg einer Mission gefährden. Diese Studie geht einer einfachen, aber wichtigen Frage nach: Wie bringen wir Computer dazu, diese ungewöhnlich klingenden Heliumstimmen zuverlässig zu verstehen, damit die Kommunikation klar und verlässlich bleibt?
Die Herausforderung beim Sprechen unter der See
Das Tiefsee-Sättigungstauchen wird für Aufgaben wie Unterwasserbau, Rettungseinsätze und Ressourcenerkundung eingesetzt. Taucher leben in metallenen Kammern, die auf den Druck der Arbeitstiefen eingestellt sind, und atmen ein Helium–Sauerstoff-Gemisch, bekannt als Heliox. Heliums geringe Dichte verändert, wie sich Schall im Vokaltrakt ausbreitet: Sprache wird piepsig, Resonanzen verschieben sich, Konsonanten werden verschwommener, und das konstante Brummen von Belüftungsventilatoren legt lauten Hintergrundlärm über das Signal. Standard-Spracherkennungssysteme, die auf alltäglichen Stimmen in Luft trainiert sind, versagen in diesem Umfeld oft. Sie hören Wörter falsch, haben Probleme mit Fachjargon und fallen bei extremen akustischen Bedingungen häufig komplett aus.
Aufbau eines realistischen Datensatzes für Tiefseestimmen
Um das Problem realitätsnah zu untersuchen, zeichneten die Forschenden die Sprache von Tauchern innerhalb eines tatsächlichen, schiffsbasierten Sättigungssystems auf. Sie erfassten Audio unter zwei Arbeitsbedingungen: der Äquivalenttiefe von 12 Metern und 25 Metern, jeweils mit sorgfältig kontrollierten Helium- und Sauerstoffanteilen. Mikrofone waren an das Interkom der Kammer angeschlossen, sodass echter Hintergrundlärm und Echo erhalten blieben. Da Aufnahmen unter solchen Bedingungen schwierig und teuer sind, lieferte jeder Taucher nur wenige Minuten Rohmaterial. Damit das Computermodell genug Lernmaterial bekam, verzehnfachte das Team die Trainingsdaten mit einfachen Verfahren: Dehnen und Stauchen der Sprechgeschwindigkeit, Zerteilen und Neukombinieren von Segmenten sowie Einmischen von Meeresbodenlärm in unterschiedlichen Pegeln. Entscheidend war, dass verschiedene Taucher für Training und Test verwendet wurden, damit die Ergebnisse echte Generalisierung und nicht nur Auswendiglernen widerspiegeln.
Dem KI-Modell Anpassung beibringen, ohne bei null anzufangen
Statt ein neues System von Grund auf neu zu entwickeln, begannen die Autorinnen und Autoren mit Whisper, einem großen Open-Source-Spracherkennungsmodell, das bereits auf massiven Mengen multilingualer Audiodaten trainiert ist. Die direkte Anwendung dieses Modells auf Heliox-Stimmen führte jedoch zu sehr hohen Fehlerquoten, was zeigt, wie anders Heliumstimmen im Vergleich zur normalen Sprache sind. Whisper vollständig auf die Nischen-Heliox-Daten neu zu trainieren wäre aufwändig und teuer, daher nutzte das Team eine Technik namens Low-Rank Adaptation (LoRA). Vereinfacht gesagt fügt LoRA den wichtigen Teilen des Modells eine sehr kleine „Nebenebene“ hinzu, während das ursprüngliche Netzwerk eingefroren bleibt. Nur dieser winzige Satz zusätzlicher Parameter wird auf den spezialisierten Tiefseeaufnahmen angepasst, wodurch der Trainingsaufwand auf etwa ein halbes Prozent des gesamten Modells schrumpft, während das breite Sprachwissen erhalten bleibt.
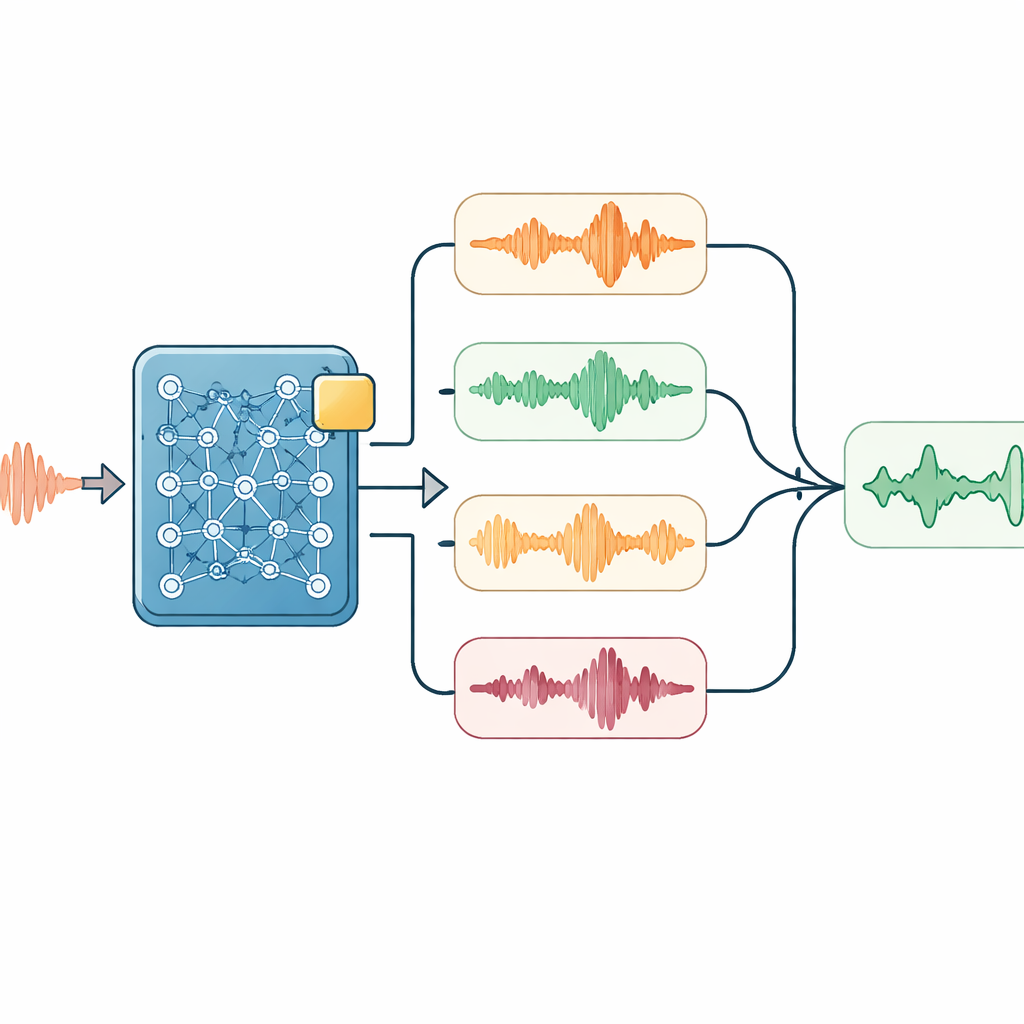
Intelligentes Zuhören zur Decodierzeit
Auf dieses angepasste Modell legten die Forschenden mehrere leichte Verfahren, die nur beim Zuhören und Transkribieren angewendet werden. Ein Modul drängt das System dezent dazu, bei Hinweisen im Audio wichtige technische Begriffe – etwa Gerätenamen – zu bevorzugen. Ein anderes verarbeitet das Audio mit leicht unterschiedlichen Geschwindigkeiten und vergleicht die resultierenden Transkripte, was hilft, Eigenarten der Sprechgeschwindigkeit zu glätten. Ein einfaches Sprachmodell bewertet anschließend alle Kandidatentranskriptionen neu und balanciert ab, wie gut sie zu den Lauten passen, wie häufig Schlüsselwörter erscheinen und wie natürlich die Zeichenfolge im Mandarin wirkt. Bei längeren Gesprächen speist das System zudem seine kürzliche Ausgabe als Hinweis in das nächste Segment zurück, wodurch es im Thema bleibt und unglückliche Satzabbrüche vermeidet.
Was die Ergebnisse für die Sicherheit der Taucher bedeuten
Tests an den Aufnahmen aus 12 und 25 Metern zeigen, dass dieser Ansatz die Erkennung von Heliumstimmen dramatisch verbessert. Das unveränderte Whisper-Modell erkannte einen großen Anteil der Zeichen falsch, doch die LoRA-abgestimmte Version reduzierte die Fehler nahezu um eine Größenordnung, obwohl nur ein Bruchteil der Parameter trainiert und die Laufzeit auf Standardservern praktikabel blieb. Die zusätzlichen Decodierschritte – besonders die sprachbasierte Neu-Rangierung – verringerten die Fehler weiter bei nur geringer Verzögerung, wobei aggressivere Methoden wie Testzeit-Augmentation hauptsächlich dann halfen, wenn Latenz weniger kritisch war. Die Arbeit zeigt, dass sich mit kluger Anpassung und Decodierung bestehende große Sprachmodelle zu genauen, ressourceneffizienten „Ohren“ für Taucher in feindlichen Tiefseeumgebungen formen lassen, sodass Besatzungen über und unter Wasser in kritischen Momenten besser miteinander verständigen können.
Zitation: Mao, W., Gu, H., He, J. et al. LoRA-enhanced whisper for resource-efficient heliox speech recognition. Sci Rep 16, 14080 (2026). https://doi.org/10.1038/s41598-026-38201-7
Schlüsselwörter: Unterwassersprache, Heliumstimme, Spracherkennung, Sättigungstauchen, LoRA-Anpassung