Clear Sky Science · en
LoRA-enhanced whisper for resource-efficient heliox speech recognition
Why underwater voices turn strange
When divers live and work deep under the sea, they often breathe a mix of helium and oxygen instead of normal air. This keeps them safe, but it makes their voices sound like cartoon characters—high, nasal, and hard to understand. In the tight, risky world of saturation diving, where people spend days or weeks in pressurized chambers, any misunderstanding over the intercom can threaten both safety and mission success. This study tackles a simple but vital question: how can we get computers to accurately understand these strange-sounding helium voices so that communication stays clear and reliable?
The challenge of talking under the sea
Deep-sea saturation diving is used for tasks such as underwater construction, rescue, and resource exploration. Divers live in metal chambers pressurized to match the depths where they work, breathing a helium–oxygen gas mix known as Heliox. Helium’s low density changes how sound travels through the vocal tract: speech becomes squeaky, with shifted resonance and blurred consonants, and the constant hum of ventilation fans adds heavy background noise. Standard speech recognition systems, trained on everyday voices in air, perform poorly in this setting. They mis-hear words, struggle with technical jargon, and often fail outright when the acoustic conditions are most extreme.
Building a realistic deep-diving voice dataset
To study this problem in a real-world way, the researchers recorded divers’ speech inside an actual ship-mounted saturation system. They captured audio at two working conditions: the equivalent of 12 meters and 25 meters underwater, each with carefully controlled helium and oxygen levels. Microphones were connected to the chamber’s intercom, preserving real background noise and echo. Because recording under these conditions is difficult and expensive, each diver contributed only a few minutes of raw speech. To give the computer model enough material to learn from, the team expanded the training data tenfold using simple tricks: stretching and compressing speaking rate, chopping and recombining segments, and mixing in seabed noise at different levels. Crucially, different divers were used for training and testing so that results would reflect true generalization, not memorization.
Teaching an AI to adapt without starting from scratch
Rather than build a new system from the ground up, the authors started with Whisper, a large open-source speech recognition model already trained on massive amounts of multilingual audio. Directly applying this model to Heliox speech, however, led to very high error rates, showing just how different helium voices are from normal speech. Fully retraining Whisper on the niche Heliox data would be wasteful and costly, so the team turned to a technique called low-rank adaptation (LoRA). In simple terms, LoRA adds a very small “side layer” to key parts of the model while freezing the original network. Only this tiny set of extra parameters is tuned on the specialized deep-sea recordings, cutting training effort to about half a percent of the full model while preserving its broad language knowledge.
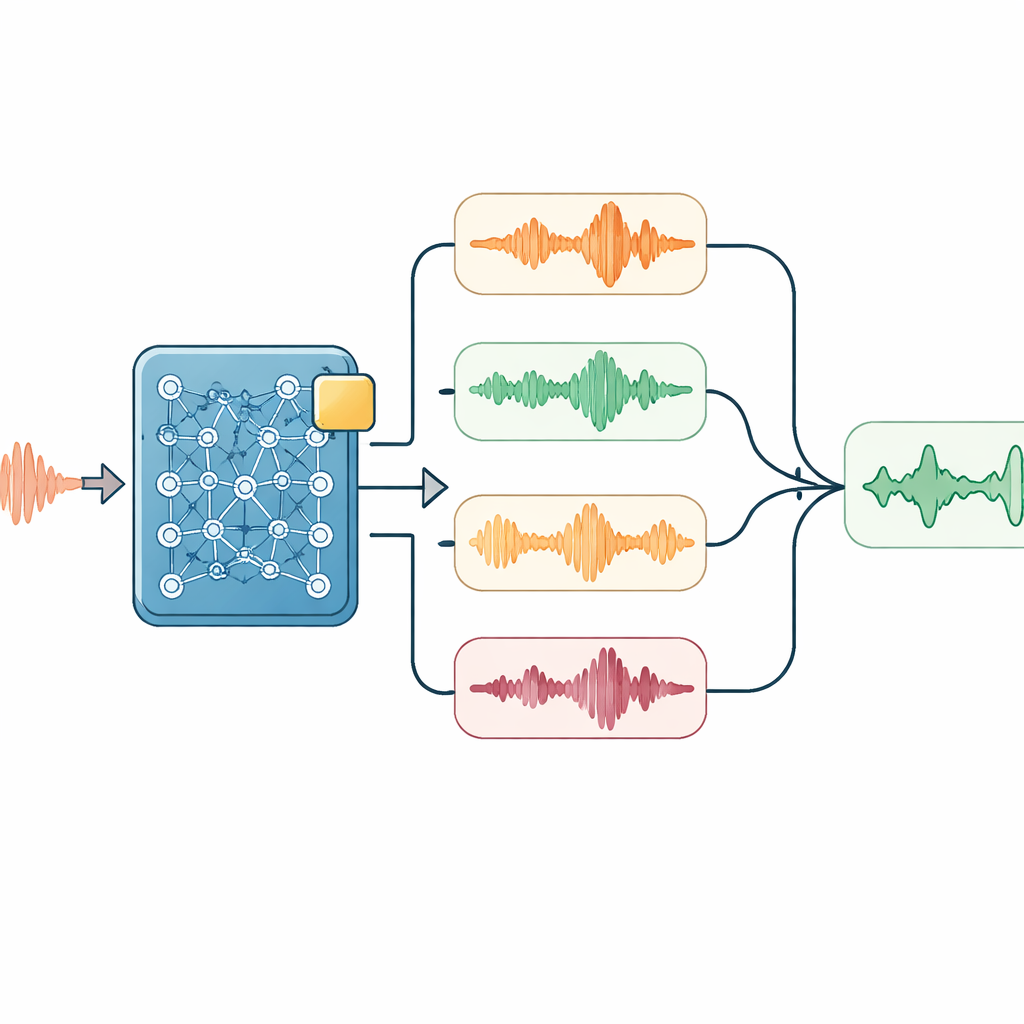
Smart listening at decoding time
On top of this adapted model, the researchers layered several lightweight tricks used only when the system listens and writes down what it hears. One module gently nudges the system to favor important technical words—like equipment names—whenever the audio suggests they might be present. Another runs the audio at slightly different speeds and compares the resulting transcripts, helping smooth over quirks in speaking rate. A simple language model then re-scores all candidate transcriptions, balancing how well they fit the sounds, how often hotwords appear, and how natural the character sequence looks in Mandarin. For long conversations, the system also feeds its recent output back into the next segment as a prompt, helping it stay on topic and avoid breaking sentences at awkward points.
What the results mean for diver safety
Tests on the 12-meter and 25-meter recordings show that this approach dramatically improves recognition of helium speech. The off-the-shelf Whisper model mis-recognized a large fraction of characters, but the LoRA-tuned version cut errors by nearly an order of magnitude while training only a sliver of the parameters and keeping runtime practical on standard servers. The added decoding steps—especially the language-based re-ranking—further trimmed mistakes with little extra delay, though more aggressive tricks like test-time augmentation were helpful mainly when latency was less critical. The work demonstrates that with clever adaptation and decoding, existing large speech models can be reshaped into accurate, resource-efficient “ears” for divers in hostile deep-sea environments, making it easier for crews above and below the surface to understand each other when it matters most.
Citation: Mao, W., Gu, H., He, J. et al. LoRA-enhanced whisper for resource-efficient heliox speech recognition. Sci Rep 16, 14080 (2026). https://doi.org/10.1038/s41598-026-38201-7
Keywords: underwater speech, helium voice, speech recognition, saturation diving, LoRA adaptation