Clear Sky Science · ru
Whisper с LoRA для ресурсно-эффективного речевого распознавания в гелиоксной среде
Почему под водой голоса звучат странно
Когда дайверы живут и работают глубоко под водой, они часто дышат смесью гелия и кислорода вместо обычного воздуха. Это сохраняет их в безопасности, но делает голоса похожими на мультяшные — высокими, носовыми и плохо разборчивыми. В условиях сатурационного погружения, где люди проводят дни или недели в камерных пространствах под давлением, любое недопонимание по переговорной связи может поставить под угрозу и безопасность, и выполнение задач. В этом исследовании решается простая, но важная задача: как заставить компьютеры точно понимать эти необычно звучащие гелионовые голоса, чтобы связь оставалась ясной и надежной?
Сложности разговора под водой
Сатурационное погружение на больших глубинах применяется для работ по подводному строительству, спасению и разведке ресурсов. Дайверы живут в металлических камерах, давление в которых соответствует глубинам работ, дыша смесью гелий–кислород, известной как гелиокс. Низкая плотность гелия меняет распространение звука в речевом тракте: речь становится визгливой, резонансы сдвигаются, согласные размазываются, а постоянный шум вентиляции добавляет сильный фон. Стандартные системы распознавания речи, обученные на обычных голосах в воздухе, работают плохо в таких условиях. Они неверно распознают слова, испытывают трудности с технической терминологией и часто полностью сдаются в самых экстремальных акустических ситуациях.
Создание реалистичного набора голосов для глубоководных погружений
Чтобы изучить проблему в реальных условиях, исследователи записывали речь дайверов внутри настоящей установленной на судне сатурационной системы. Аудио фиксировали в двух рабочих состояниях: эквивалент 12 метров и 25 метров под водой, с тщательно контролируемыми уровнями гелия и кислорода. Микрофоны были подключены к переговорной системе камеры, что сохранило реальные фоновые шумы и эхо. Поскольку запись в таких условиях сложна и дорога, каждый дайвер давал только несколько минут сырой речи. Чтобы дать модели достаточно данных для обучения, команда увеличила тренировочный набор в десять раз с помощью простых приёмов: растяжение и сжатие скорости речи, разрезание и комбинирование фрагментов, а также смешивание с шумом морского дна на разных уровнях. Важно, что для обучения и тестирования использовались разные дайверы, чтобы результаты отражали истинную обобщаемость, а не запоминание.
Обучение ИИ адаптироваться без переподготовки с нуля
Вместо создания новой системы с нуля авторы взяли Whisper — крупную открытую модель распознавания речи, уже обученную на огромных объёмах многоязычного аудио. Прямое применение этой модели к гелиоксной речи показало очень высокий уровень ошибок, что подчёркивает, насколько гелиевые голоса отличаются от обычных. Полная переобучка Whisper на узких гелиоксных данных была бы расточительной и дорогостоящей, поэтому команда применила методику низкоранговой адаптации (LoRA). Проще говоря, LoRA добавляет очень небольшой «боковой слой» в ключевые части модели, фиксируя оригинальную сеть. Настраивается только этот крошечный набор дополнительных параметров на специализированных глубоководных записях, что сокращает усилия обучения примерно до полпроцента от полного обучения при сохранении широких языковых знаний модели.
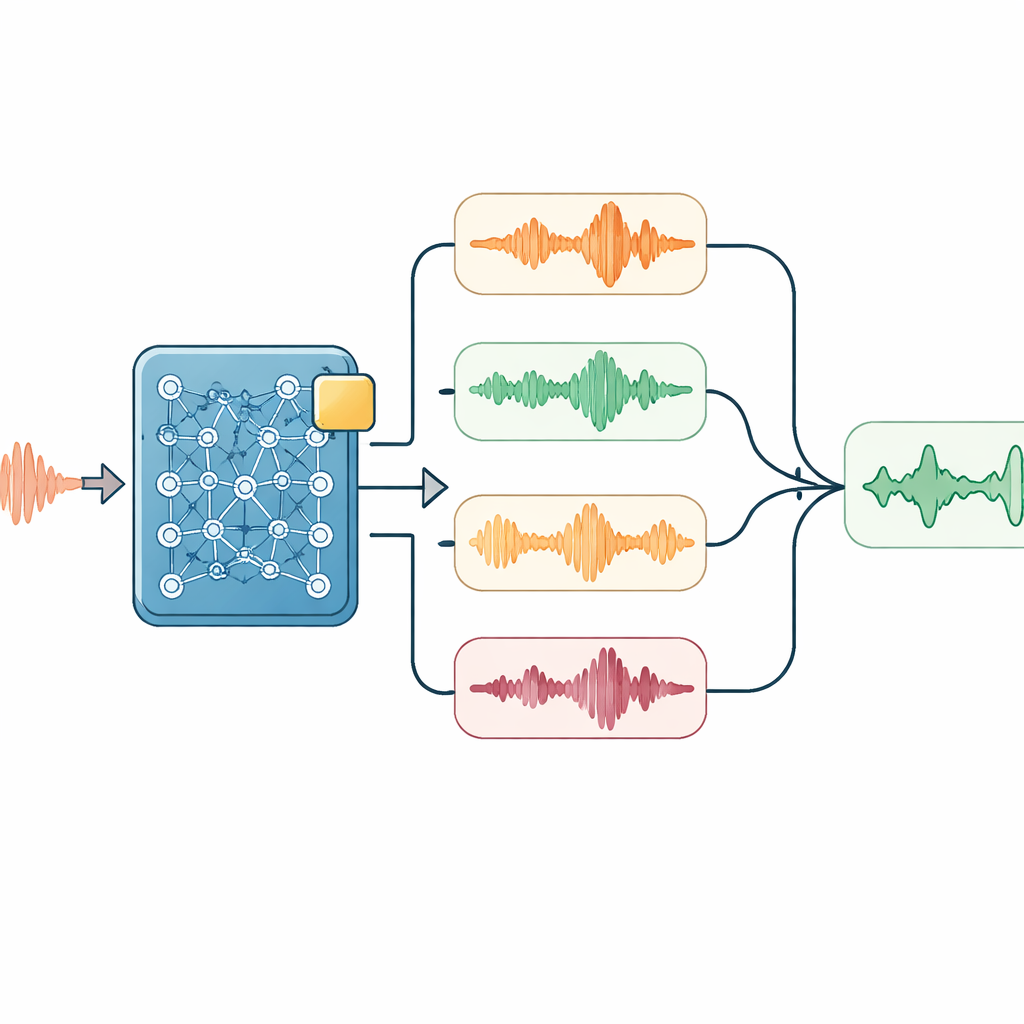
Умное прослушивание во время декодирования
Поверх адаптированной модели исследователи применили несколько лёгких приёмов, используемых только на этапе прослушивания и транскрибирования. Один модуль мягко смещает решения системы в пользу важных технических слов — например, имён оборудования — когда аудио указывает на их возможное присутствие. Другой запускает аудио с слегка изменёнными скоростями и сравнивает полученные расшифровки, что помогает сгладить особенности темпа речи. Простой языковой модельный компонент затем повторно оценивает все кандидатные транскрипции, взвешивая соответствие звукам, частоту появления ключевых слов и естественность последовательности символов на китайском языке. Для длинных разговоров система также подаёт своё недавнее выводы обратно в следующий сегмент как подсказку, помогая сохранять тему и избегать разрывов предложений в неудобных местах.
Что результаты значат для безопасности дайверов
Тесты на записях с глубины 12 и 25 метров показывают, что такой подход значительно улучшает распознавание гелионовой речи. Штатная модель Whisper ошибалась при распознавании большого числа символов, но версия, настроенная с помощью LoRA, сократила ошибки почти в десяток раз, обучая при этом лишь крошечную долю параметров и сохраняя практическое время выполнения на стандартных серверах. Дополнительные шаги декодирования — особенно перестановка по языковой модели — ещё сильнее уменьшали число ошибок с незначительной задержкой, тогда как более агрессивные приёмы, такие как тестовое расширение данных во время работы, были полезны главным образом при невысоких требованиях к задержке. Работа демонстрирует, что при умной адаптации и декодировании существующие крупные речевые модели можно превратить в точные и ресурсно-эффективные «уши» для дайверов в враждебной глубинной среде, облегчая взаимопонимание экипажей над и под поверхностью в критические моменты.
Цитирование: Mao, W., Gu, H., He, J. et al. LoRA-enhanced whisper for resource-efficient heliox speech recognition. Sci Rep 16, 14080 (2026). https://doi.org/10.1038/s41598-026-38201-7
Ключевые слова: подводная речь, гелионовый голос, распознавание речи, сатурационное погружение, адаптация LoRA