Clear Sky Science · zh
一个全面的欧洲结直肠癌队列数据集
为何共享癌症数据池至关重要
结直肠癌是全球致死率较高的癌症之一,但临床医生仍难以准确预测哪些患者预后良好、哪些需要额外治疗。本文介绍了一项重要的欧洲计划,将来自一万多名患者的详尽信息汇集为一个经过严格核验的资源。通过统一不同国家的病历、组织样本、显微镜图像和DNA数据,该项目为更早的诊断、更智能的治疗方案以及用于癌症护理的新型计算机辅助工具奠定了强有力的基础。
针对常见癌症的泛欧洲协作
结直肠癌通常发展缓慢,常常需要数年时间,这使其成为筛查和预防的主要目标。目前的检测方法从简单的大便检测到更具侵入性的内镜检查不等,医生也会参考基因变化和其他“生物标志物”来指导治疗。然而,临床上得到充分验证的生物标志物仍然有限,许多问题尚未解决,例如对处于中间病期患者的最佳治疗方式。为填补这些空白,生物样本库与生物分子资源研究基础设施(BBMRI-ERIC)协调了12个欧洲国家的26个生物样本库,建立了一个包含10,780名患者的共享结直肠癌队列,所有患者均具有标准化的核心信息并与生物样本相连。
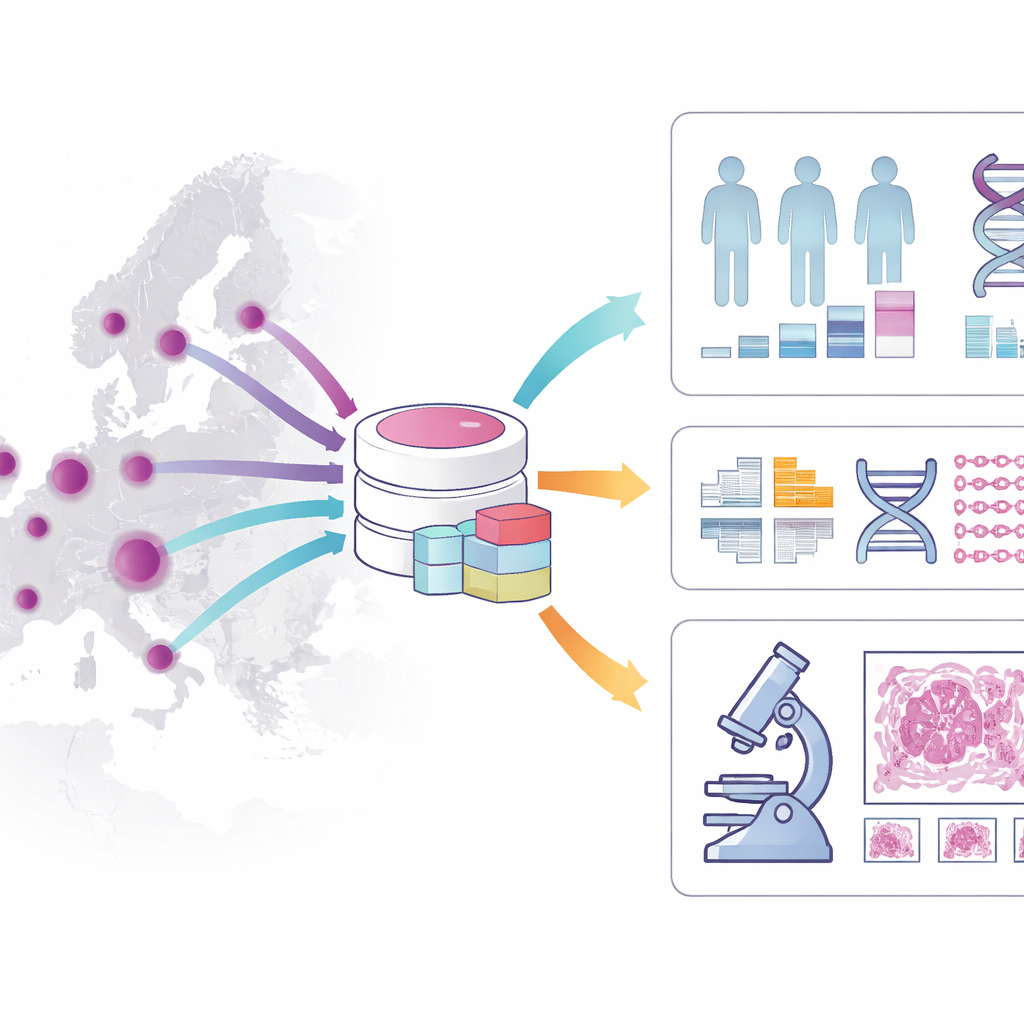
该队列究竟包含哪些内容?
该队列描绘了每位患者就诊过程的丰富信息。它包括年龄、性别、诊断详情、风险因素、所接受的治疗以及长期生存情况,重点是随访至少五年的患者。它记录了肿瘤在显微镜下的形态、疾病分期以及关键的分子特征,例如某些基因突变和DNA修复缺陷。除了这些临床细节外,数据集还关联了医院生物样本库保存的组织样本、三千多张高分辨率的结肠肿瘤数字切片图像以及数百名患者的全基因组测序数据。多层次的数据使研究者能够将病理学所见、DNA揭示的信息与患者的实际结局联系起来。
将碎片化记录整合为一致资源
构建这样的资源并非易事。每个生物样本库最初以各自的格式存储信息,常以简单的电子表格形式存在,并遵循不同的本地规则和技术标准。项目团队通过医生、病理学家、IT专家和样本库人员之间反复讨论,设计出一个通用数据模型,确定哪些信息是必要的以及它们应如何定义。随后他们开发了软件工具,将多样的本地表格转换为统一的结构化格式,并将数据映射到广泛使用的医疗标准。通过以 openEHR、OMOP 和 FHIR 等格式表达相同信息,队列变得对多家医院系统和研究平台可理解,从而扩大了其覆盖面和可复用性。
保证数据准确、隐私与可用性
由于数据来自日常医疗和众多机构,数据质量与隐私成为核心关注点。每条记录在传输前都去除了直接个人标识信息,每位患者由一个只有原始生物样本库能追溯回个人的编码ID替代。自动化校验会检测日期、年龄、肿瘤分期和治疗等信息是否合理且一致;可疑条目(例如报告的死亡日期之前发生手术)会触发反馈,要求提供数据的样本库进行更正。文章还描述了结构化的访问程序:全球的研究人员可以申请使用该队列,但专门委员会会审查每个请求,考虑伦理批准、数据最小化原则以及是否与队列用途相符。如果共享与当地法律或知情同意规则冲突,生物样本库保留反对的权利。
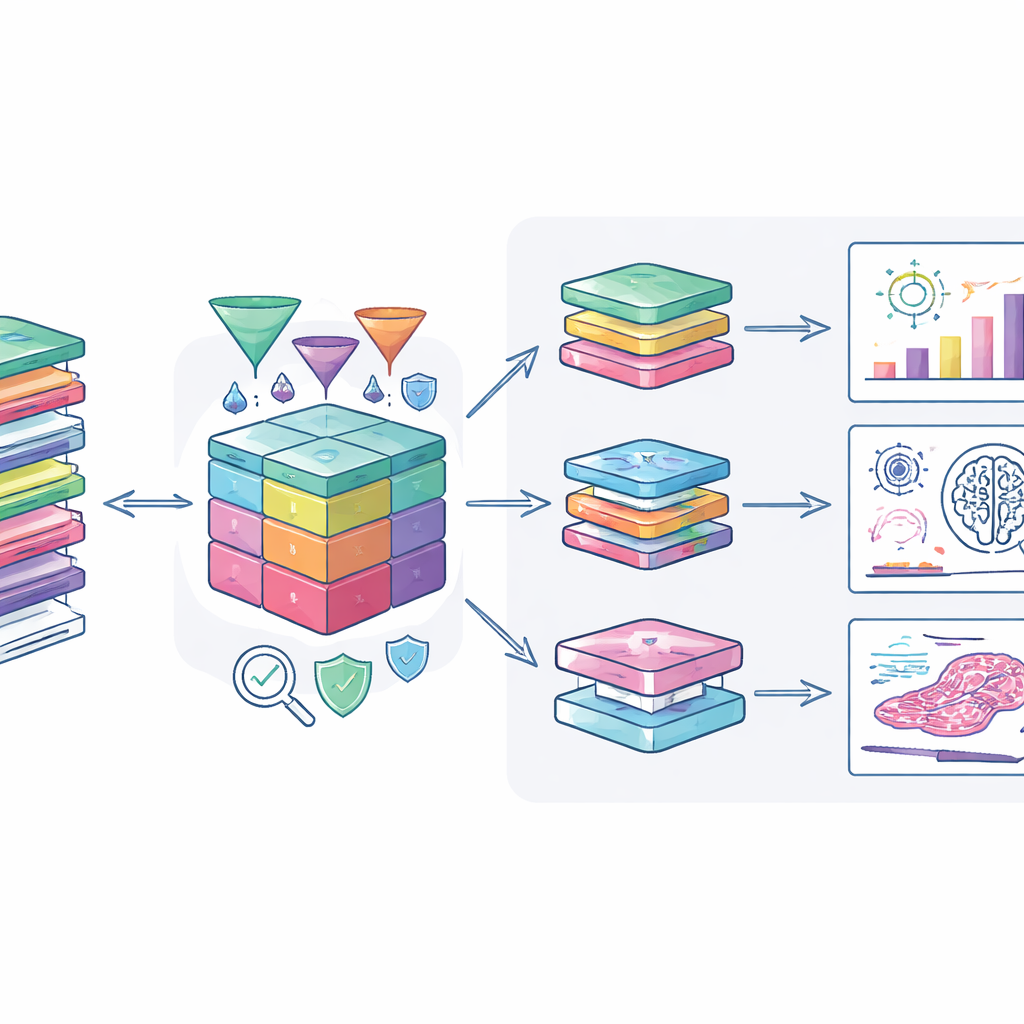
研究人员如何利用该资源
作者已将数据集连接到现代分析工具,使获批用户能够安全地探索数据。一个专门的网络门户支持对临床数据、基因改变和数字病理图像的联合查看,支持从寻找新生物标志物到训练人工智能识别肿瘤模式的各种研究。安全传输系统和加密技术在数据移动到研究人员自身计算环境时予以保护。团队还鼓励研究者返还派生结果,例如新的风险评分或匿名化方法,以便队列持续增值。
这对患者与医学意味着什么
对非专业读者来说,关键信息是该项目创建了一个共享的、高质量的“参考库”,涵盖了来自全欧洲的真实结直肠癌病例。与每家医院各自为战、依赖小型孤立数据集相比,科学家现在可以研究数千名患者的模式,在不同人群中验证发现,并以更稳健的方式测试新的诊断工具。虽然该队列本身并不产生单一的新检测或药物,但它为更早的发现、更个性化的治疗以及病理学中人工智能的更好应用奠定了基础。在实际层面上,这类经过精心治理的数据共享可以加速那些未来可能帮助医生判断谁真正需要化疗、谁可以安全避免化疗以及如何在肿瘤扩散前发现危险病变的发现。
引用: Holub, P., Törnwall, O., Garcia Alvarez, E. et al. A comprehensive European Colorectal Cancer Cohort dataset. Sci Data 13, 662 (2026). https://doi.org/10.1038/s41597-026-06822-2
关键词: 结直肠癌, 生物样本库数据, 数字病理学, 基因组队列, 医学数据共享