Clear Sky Science · de
Ein umfassendes europäisches Kolorektalkarzinom-Kohortendatensatz
Warum ein gemeinsamer Krebs-Datenpool wichtig ist
Das Kolorektalkarzinom gehört zu den tödlichsten Krebsarten weltweit, doch Ärztinnen und Ärzte haben weiterhin Schwierigkeiten vorherzusagen, welche Patienten gut zurechtkommen und wer zusätzliche Therapie benötigt. Dieser Beitrag beschreibt eine große europäische Initiative, die detaillierte Informationen von mehr als zehntausend Patientinnen und Patienten in einer einzigen, sorgfältig geprüften Ressource zusammenführt. Durch die Harmonisierung von Krankenakten, Gewebeproben, Mikroskopbildern und DNA‑Daten aus vielen Ländern schafft das Projekt eine leistungsfähige Grundlage für frühere Diagnosen, gezieltere Therapien und neue computerunterstützte Werkzeuge für die Krebsversorgung.
Ein gesamteuropäischer Einsatz gegen einen häufigen Krebs
Das Kolorektalkarzinom entwickelt sich langsam, oft über Jahre, weshalb es sich besonders für Screening und Prävention eignet. Heute reichen die Tests von einfachen Stuhluntersuchungen bis zu invasiveren Verfahren wie Endoskopie; Ärztinnen und Ärzte berücksichtigen zudem genetische Veränderungen und andere „Biomarker“, um die Behandlung zu steuern. Dennoch sind nur wenige Biomarker klinisch gefestigt, und viele Fragen bleiben offen, etwa wie Patienten mit intermediären Krankheitsstadien am besten behandelt werden sollten. Um diese Lücken anzugehen, koordinierte die Biobanking and Biomolecular Resources Research Infrastructure (BBMRI-ERIC) 26 Biobanken in 12 europäischen Ländern, um eine gemeinsame Kolorektalkarzinom-Kohorte mit insgesamt 10.780 Patientinnen und Patienten aufzubauen — alle mit standardisierten Kerndaten und verknüpften biologischen Proben.
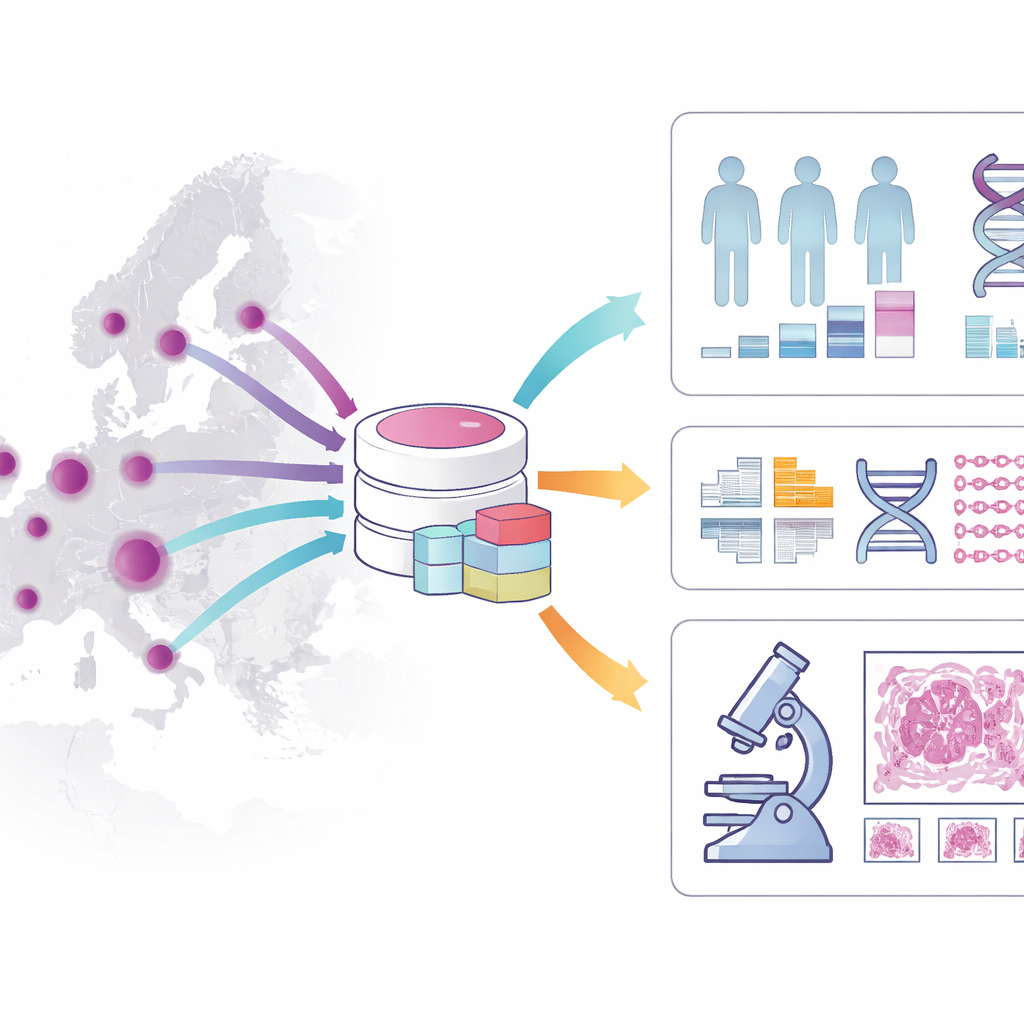
Was genau enthält die Kohorte?
Die Kohorte zeichnet ein facettenreiches Bild der Krankheitsverläufe. Sie umfasst Alter, Geschlecht, Diagnosedetails, Risikofaktoren, erhaltene Behandlungen und Langzeitüberleben, mit Schwerpunkt auf Patientinnen und Patienten, die mindestens fünf Jahre nachverfolgt wurden. Sie speichert Informationen zur makroskopischen und mikroskopischen Tumoroptik, zum Erkrankungsstadium und zu wichtigen molekularen Merkmalen wie bestimmten Genmutationen und Defekten der DNA-Reparatur. Über diese klinischen Details hinaus verknüpft der Datensatz Gewebeproben aus Krankenhaus-Biobanken, mehr als dreitausend hochauflösende digitale Schnitte von Darmtumoren und Ganzgenomsequenzdaten für Hunderte von Patienten. Zusammengenommen ermöglichen diese Ebenen, zu verbinden, was Pathologinnen und Pathologen sehen, was die DNA offenbart und wie sich Patientinnen und Patienten tatsächlich im Zeitverlauf entwickeln.
Aus fragmentierten Aufzeichnungen eine konsistente Ressource machen
Der Aufbau einer solchen Ressource war alles andere als trivial. Jede Biobank speicherte ursprünglich Informationen in eigenen Formaten, häufig in einfachen Tabellen, und folgte unterschiedlichen lokalen Regeln und technischen Standards. Die Projektteams entwarfen ein gemeinsames Datenmodell durch wiederholte Diskussionen zwischen Ärztinnen und Ärzten, Pathologinnen und Pathologen, IT‑Expertinnen und -Experten sowie Biobank‑Mitarbeitenden und einigten sich darauf, welche Informationen wesentlich sind und wie sie definiert werden sollten. Anschließend entwickelten sie Softwarewerkzeuge, um die vielfältigen lokalen Tabellen in ein einheitliches, strukturiertes Format zu überführen und die Daten auf weit verbreitete Gesundheitsstandards zu mappen. Indem dieselben Informationen in Formaten wie openEHR, OMOP und FHIR ausgedrückt werden, wird die Kohorte für viele Krankenhaus‑Systeme und Forschungsplattformen verständlich und damit nutzbarer und wiederverwendbar.
Daten genau, privat und nutzbar halten
Da die Daten aus der Routineversorgung und zahlreichen Einrichtungen stammten, hatten Qualität und Datenschutz oberste Priorität. Jeder Datensatz wurde vor der Übertragung von direkten persönlichen Identifikatoren befreit; jede Patientin und jeder Patient wurde durch eine codierte ID ersetzt, die nur die ursprüngliche Biobank wieder einer Person zuordnen kann. Automatisierte Prüfungen kontrollieren, ob Daten wie Zeitpunkte, Alter, Tumorstadien und Behandlungen plausibel und konsistent sind; auffällige Einträge, etwa eine Operation nach dem angegebenen Todesdatum, lösen Rückmeldungen an die beitragende Biobank zur Korrektur aus. Der Artikel beschreibt außerdem ein strukturiertes Zugangsverfahren: Forschende weltweit können die Nutzung der Kohorte beantragen, aber ein eigenes Gremium prüft jede Anfrage hinsichtlich ethischer Genehmigung, Datenminimierung und der Übereinstimmung mit dem Zweck der Kohorte. Die Biobanken behalten das Recht, Einwände zu erheben, wenn das Teilen mit lokalen Rechts- oder Einwilligungsregelungen kollidieren würde.
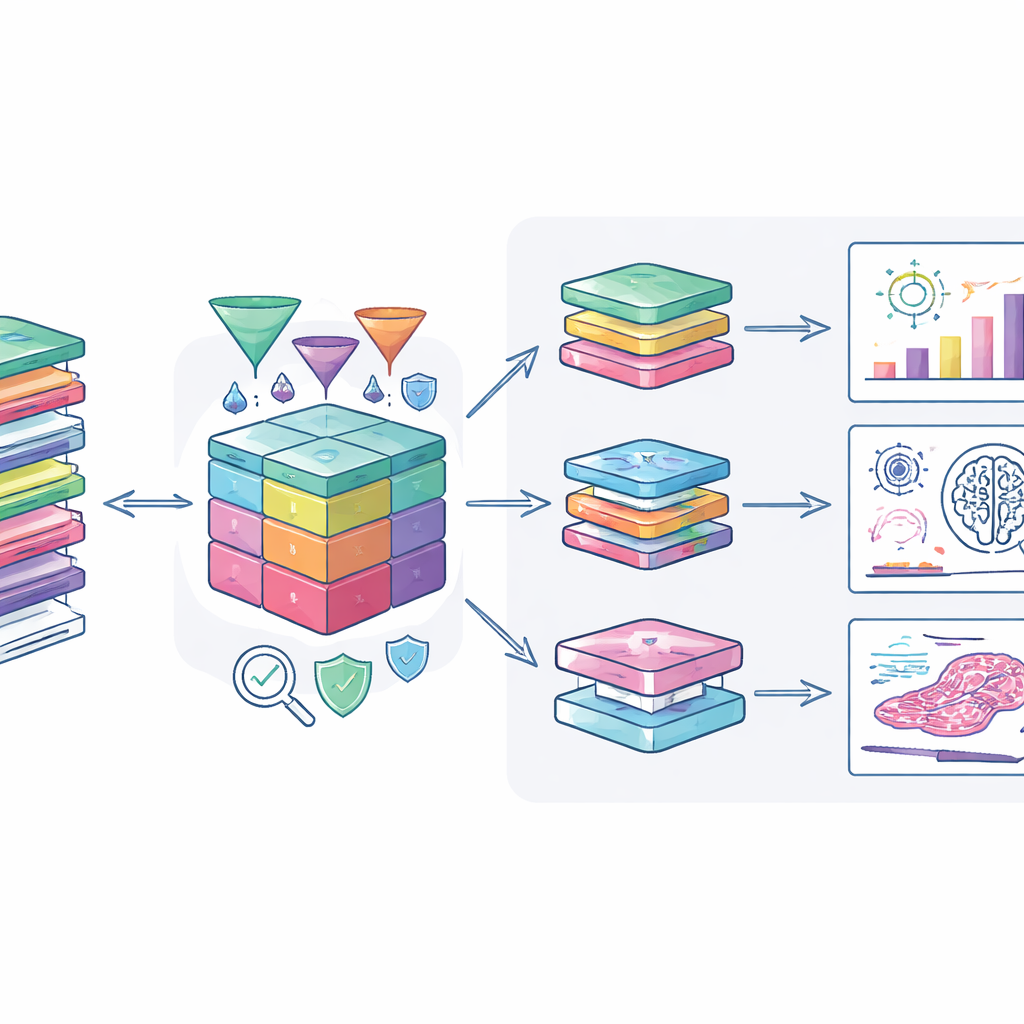
Wie Forschende das nutzen können
Die Autorinnen und Autoren haben den Datensatz an moderne Analysewerkzeuge angeschlossen, sodass genehmigte Nutzerinnen und Nutzer ihn sicher erkunden können. Ein spezialisiertes Webportal erlaubt die kombinierte Ansicht klinischer Daten, genetischer Veränderungen und digitaler Pathologie-Bilder und unterstützt Studien, die von der Suche nach neuen Biomarkern bis zum Training künstlicher Intelligenz zur Erkennung von Tumormustern reichen. Sichere Übertragungssysteme und Verschlüsselung schützen die Daten beim Transfer in die Rechenumgebungen der Forschenden. Das Team ermutigt darüber hinaus dazu, abgeleitete Ergebnisse, etwa neue Risikoscores oder Anonymisierungsmethoden, zurückzugeben, sodass die Kohorte fortlaufend an Wert gewinnt.
Was das für Patientinnen, Patienten und die Medizin bedeutet
Für eine interessierte Leserschaft lautet die Kernbotschaft: Dieses Projekt hat eine gemeinsame, hochwertige „Referenzbibliothek“ realer Kolorektalkarzinom-Fälle in ganz Europa geschaffen. Anstatt dass jedes Krankenhaus mit kleinen, isolierten Datensätzen arbeitet, können Wissenschaftlerinnen und Wissenschaftler nun Muster über Tausende von Patientinnen und Patienten hinweg analysieren, Befunde an diversen Populationen prüfen und neue Diagnosewerkzeuge robust testen. Zwar liefert die Kohorte selbst keinen einzelnen neuen Test oder Wirkstoff, doch sie legt das Fundament für frühere Erkennung, individuellere Therapien und bessere Nutzung von künstlicher Intelligenz in der Pathologie. Praktisch kann eine derart sorgfältig geregelte Datenfreigabe die Entdeckungen beschleunigen, die eines Tages Ärztinnen und Ärzten helfen könnten zu entscheiden, wer wirklich eine Chemotherapie braucht, wer sicher darauf verzichten kann und wie gefährliche Tumoren aufgefangen werden, bevor sie streuen.
Zitation: Holub, P., Törnwall, O., Garcia Alvarez, E. et al. A comprehensive European Colorectal Cancer Cohort dataset. Sci Data 13, 662 (2026). https://doi.org/10.1038/s41597-026-06822-2
Schlüsselwörter: Kolorektalkarzinom, Biobankdaten, digitale Pathologie, genomische Kohorte, Medizindatenaustausch