Clear Sky Science · sv
En omfattande europeisk kohortdatamängd för kolorektalcancer
Varför en gemensam databas för cancer är viktig
Kolorektalcancer är en av världens dödligaste cancerformer, men läkare har fortfarande svårt att förutsäga vilka patienter som kommer att klara sig bra och vilka som behöver extra behandling. Denna artikel beskriver en omfattande europeisk satsning för att samla detaljerad information från mer än tiotusen patienter i en enda, noggrant kontrollerad resurs. Genom att harmonisera journaluppgifter, vävnadsprover, mikroskopbilder och DNA-data från många länder skapar projektet en kraftfull grund för tidigare diagnostik, smartare terapier och nya datorstödda verktyg för cancervård.
En paneuropeisk insats mot en vanlig cancer
Kolorektalcancer utvecklas långsamt, ofta över flera år, vilket gör den till ett bra mål för screening och prevention. Dagens tester varierar från enkla avföringsbaserade kontroller till mer invasiva ingrepp som endoskopi, och läkare tittar också på genetiska förändringar och andra ”biomarkörer” för att styra behandling. Endast några få biomarkörer är dock fast etablerade i kliniken, och många frågor återstår, till exempel hur patienter i mellanliggande sjukdomsstadier bäst bör behandlas. För att hantera dessa luckor samordnade Biobanking and Biomolecular Resources Research Infrastructure (BBMRI-ERIC) 26 biobanker i 12 europeiska länder för att bygga en delad kohort för kolorektalcancer med 10 780 patienter, alla med standardiserad grundinformation och kopplade biologiska prover.
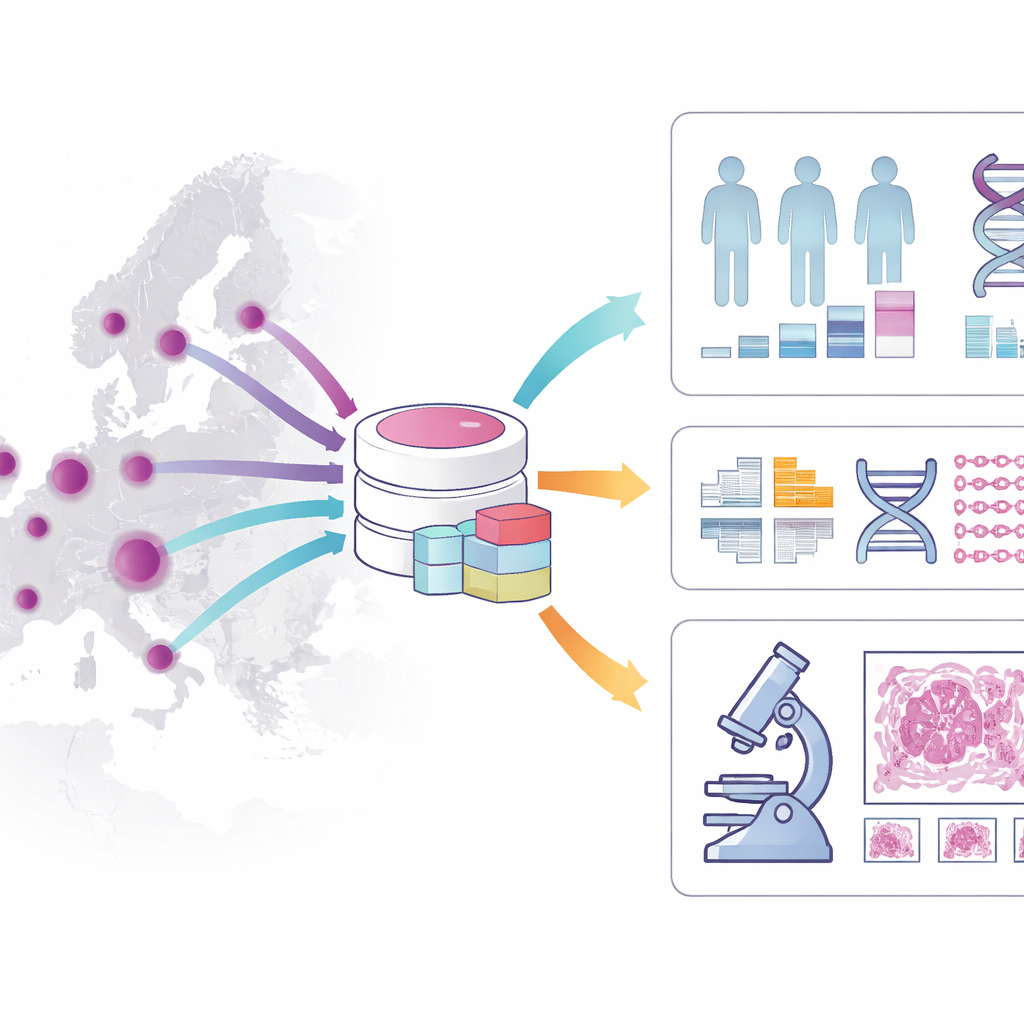
Vad innehåller kohorten?
Kohorten fångar en rik bild av varje patients sjukdomsförlopp. Den innehåller ålder, kön, diagnosdetaljer, riskfaktorer, erhållen behandling och långsiktig överlevnad, med fokus på patienter som följts i minst fem år. Den lagrar information om tumörens utseende i mikroskop, sjukdomsstadium och viktiga molekylära egenskaper såsom vissa genmutationer och problem i DNA-reparationsmekanismer. Utöver dessa kliniska uppgifter länkas datasetet till vävnadsprover bevarade i sjukhusbiobanker, över tremiljoners (?) högupplösta digitala snitt av kolonstumörer och helgenomsekvenseringsdata för hundratals patienter. Tillsammans gör dessa lager det möjligt att koppla vad patologer ser, vad DNA:t avslöjar och hur patienterna faktiskt klarar sig över tid.
Från splittrade register till en sammanhängande resurs
Att bygga en sådan resurs var långt ifrån enkelt. Varje biobank lagrade ursprungligen information i egna format, ofta som enkla kalkylblad, och följde olika lokala regler och tekniska standarder. Projektgrupperna utformade en gemensam datamodell genom upprepade diskussioner mellan läkare, patologer, IT-experter och biobankspersonal, där de enades om vilka informationsbitar som var väsentliga och hur de skulle definieras. De skapade sedan mjukvaruverktyg för att konvertera de olika lokala tabellerna till ett enda, strukturerat format och för att kartlägga data till allmänt använda vårdstandarder. Genom att uttrycka samma information i format som openEHR, OMOP och FHIR blir kohorten begriplig för många journalsystem och forskningsplattformar, vilket ökar dess räckvidd och återanvändbarhet.
Att hålla data korrekta, privata och användbara
Eftersom data kom från rutinvård och många institutioner var kvalitet och integritet centrala frågor. Varje post avpersonifierades från direkta personuppgifter innan överföring, där varje patient ersattes av ett kodat ID som endast den ursprungliga biobanken kan koppla tillbaka till en person. Automatiska kontroller testar om datum, åldrar, tumörstadier och behandlingar är rimliga och konsistenta; misstänkta poster, som operation angiven efter ett rapporterat dödsdatum, skickas tillbaka till bidragande biobank för korrigering. Artikeln beskriver också en strukturerad åtkomstprocedur: forskare var som helst i världen kan ansöka om att använda kohorten, men en särskild kommitté granskar varje begäran med avseende på etiskt godkännande, dataminimering och överensstämmelse med kohortens syfte. Biobanker behåller rätten att motsätta sig delning om det skulle strida mot lokala lagar eller samtyckesregler.
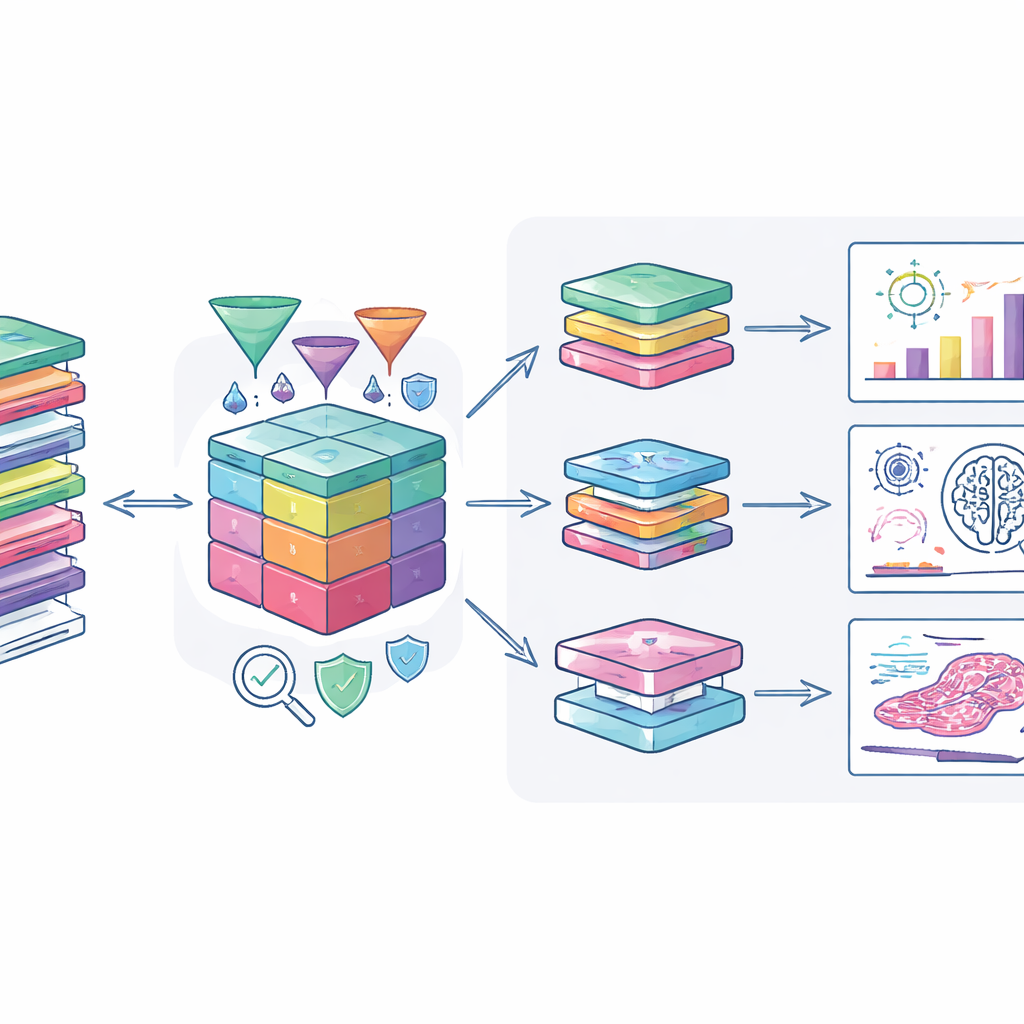
Hur forskare kan använda detta
Författarna har kopplat datasetet till moderna analysverktyg så att godkända användare kan utforska det på ett säkert sätt. En specialiserad webbportal tillåter kombinerad visning av kliniska data, genetiska förändringar och digitala patologibilder, vilket stöder studier från sökande efter nya biomarkörer till träning av artificiell intelligens för att känna igen tumörmönster. Säkra överföringssystem och kryptering skyddar data när de flyttas till forskares egna datorresurser. Teamet uppmuntrar också utredare att återföra framtagna resultat, såsom nya riskscore eller anonymiseringsmetoder, så att kohorten kontinuerligt ökar i värde.
Vad detta betyder för patienter och medicin
För allmänheten är huvudbudskapet att detta projekt har skapat ett delat, högkvalitativt ”referensbibliotek” av verkliga kolorektalcancerfall över Europa. Istället för att varje sjukhus arbetar med små, isolerade dataset kan forskare nu studera mönster över tusentals patienter, pröva fynd mot olika populationer och testa nya diagnostiska verktyg på ett robust sätt. Medan kohorten i sig inte levererar ett enskilt nytt test eller läkemedel, lägger den grunden för tidigare upptäckt, mer skräddarsydd behandling och bättre användning av artificiell intelligens i patologin. I praktiska termer kan denna typ av noggrant styrd datadelning snabba på upptäckter som en dag kan hjälpa läkare avgöra vem som verkligen behöver cytostatika, vem som säkert kan avstå från den och hur man upptäcker farliga tumörer innan de sprider sig.
Citering: Holub, P., Törnwall, O., Garcia Alvarez, E. et al. A comprehensive European Colorectal Cancer Cohort dataset. Sci Data 13, 662 (2026). https://doi.org/10.1038/s41597-026-06822-2
Nyckelord: kolorektalcancer, biobankdata, digital patologi, genomisk kohort, delning av medicinska data