Clear Sky Science · nl
Een uitgebreide Europese cohortdataset voor colorectale kanker
Waarom een gedeelde dataset voor kanker van belang is
Colorectale kanker behoort tot de dodelijkste vormen van kanker wereldwijd, maar artsen vinden het nog steeds moeilijk te voorspellen welke patiënten het goed zullen doen en wie extra behandeling nodig heeft. Dit artikel beschrijft een omvangrijke Europese inspanning om gedetailleerde informatie van meer dan tienduizend patiënten te bundelen in één zorgvuldig gecontroleerde bron. Door ziekenhuisgegevens, weefselmonsters, microscoopbeelden en DNA‑gegevens uit meerdere landen te harmoniseren, biedt het project een krachtige basis voor vroegere diagnose, slimmere therapieën en nieuwe computerondersteunde hulpmiddelen voor kankerzorg.
Een pan‑Europese inspanning tegen een veelvoorkomende kanker
Colorectale kanker ontwikkelt zich langzaam, vaak over jaren, waardoor screening en preventie realistische opties zijn. Huidige tests variëren van eenvoudige ontlastingonderzoeken tot meer ingrijpende procedures zoals endoscopie, en artsen kijken ook naar genetische veranderingen en andere “biomarkers” om de behandeling te sturen. Toch zijn slechts enkele biomarkers in de kliniek stevig vastgesteld en blijven veel vragen open, bijvoorbeeld hoe patiënten met tussenliggende ziektestadia het beste behandeld kunnen worden. Om deze lacunes aan te pakken coördineerde de Biobanking and Biomolecular Resources Research Infrastructure (BBMRI‑ERIC) 26 biobanken in 12 Europese landen om een gedeeld colorectaalkankercohort op te bouwen met 10.780 patiënten, allemaal met gestandaardiseerde kerninformatie en gekoppelde biologische monsters.
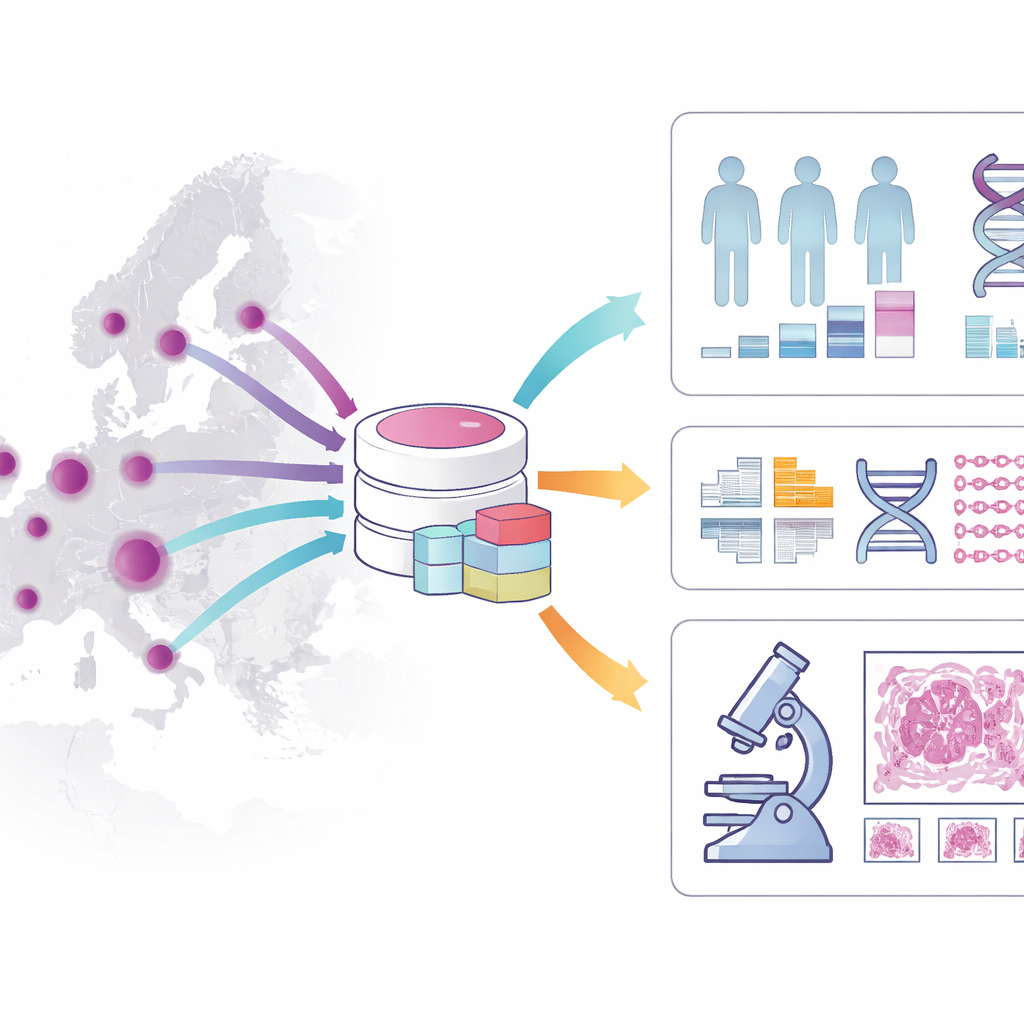
Wat zit er precies in het cohort?
Het cohort schetst een gedetailleerd beeld van het traject van elke patiënt. Het bevat leeftijd, geslacht, diagnoserapporten, risicofactoren, ontvangen behandelingen en de lange termijn overleving, met speciale aandacht voor patiënten die minstens vijf jaar werden gevolgd. Het slaat informatie op over het uiterlijk van de tumor onder de microscoop, het ziektestadium en sleutelkenmerken op moleculair niveau, zoals bepaalde genmutaties en problemen met DNA‑herstel. Naast deze klinische gegevens is de dataset gekoppeld aan weefselmonsters die in ziekenhuisbiobanken zijn bewaard, meer dan drieduizend digitale high‑resolution slides van colontumoren en whole‑genome sequencing‑gegevens van honderden patiënten. Deze lagen samen maken het mogelijk te verbinden wat pathologen zien, wat het DNA onthult en hoe patiënten in de loop van de tijd daadwerkelijk presteren.
Gefragmenteerde dossiers omzetten in één samenhangende bron
Het opbouwen van zo’n bron was allesbehalve eenvoudig. Elke biobank bewaarde aanvankelijk informatie in eigen formaten, vaak als simpele spreadsheets, en volgde verschillende lokale regels en technische standaarden. De projectteams ontwierpen een gemeenschappelijk datamodel via herhaalde discussies tussen artsen, pathologen, IT‑experts en biobankpersoneel, waarbij ze overeenkwamen welke informatie essentieel is en hoe die gedefinieerd moest worden. Vervolgens ontwikkelden ze softwaretools om de uiteenlopende lokale tabellen naar één gestructureerd formaat te converteren en de gegevens te mappen naar algemeen gebruikte zorgstandaarden. Door dezelfde informatie uit te drukken in formaten zoals openEHR, OMOP en FHIR, wordt het cohort begrijpelijk voor veel ziekenhuis-systemen en onderzoeksplatforms, wat de reikwijdte en hergebruik vergroot.
Gegevens nauwkeurig, privé en bruikbaar houden
Aangezien de gegevens uit routinematige zorg en veel instellingen afkomstig waren, stonden kwaliteit en privacy centraal. Elk record werd ontdaan van directe persoonlijke identificatoren voordat het werd overgedragen, waarbij elke patiënt werd vervangen door een gecodeerde ID die alleen de oorspronkelijke biobank aan een persoon kan koppelen. Geautomatiseerde controles toetsen of data zoals datums, leeftijden, tumorstadia en behandelingen plausibel en consistent zijn; verdachte invoer, zoals een operatie na een geregistreerde overlijdensdatum, leidt tot terugkoppeling aan de bijdragende biobank voor correctie. Het artikel beschrijft ook een gestructureerde toegangprocedure: onderzoekers wereldwijd kunnen een aanvraag indienen om het cohort te gebruiken, maar een toegewijd comité beoordeelt elke aanvraag op ethische goedkeuring, dataminimalisatie en afstemming op het doel van het cohort. Biobanken behouden het recht bezwaar te maken als delen in strijd zou zijn met lokale wet‑ of toestemmingsregels.
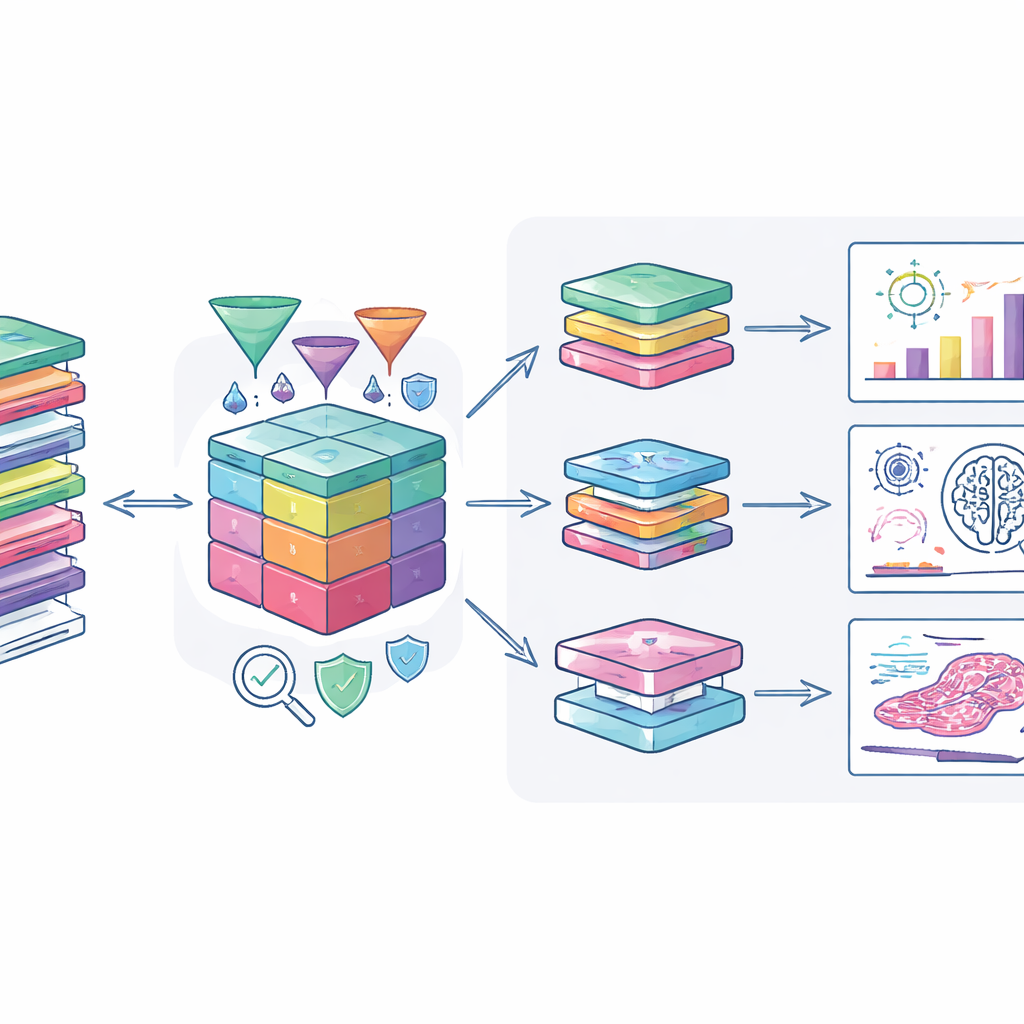
Hoe onderzoekers dit kunnen benutten
De auteurs hebben de dataset gekoppeld aan moderne analysetools zodat goedgekeurde gebruikers er veilig in kunnen werken. Een gespecialiseerd webportaal maakt gecombineerde weergave van klinische gegevens, genetische veranderingen en digitale pathologiebeelden mogelijk, en ondersteunt studies die variëren van het zoeken naar nieuwe biomarkers tot het trainen van kunstmatige‑intelligentiesystemen om tumorpatteneren te herkennen. Beveiligde overdrachtsystemen en encryptie beschermen gegevens wanneer ze naar de rekenomgevingen van onderzoekers worden verplaatst. Het team moedigt onderzoekers ook aan afgeleide resultaten terug te geven, zoals nieuwe risico‑scores of anonimisatiemethoden, zodat het cohort continu aan waarde wint.
Wat dit betekent voor patiënten en de geneeskunde
Voor niet‑specialisten is de kernboodschap dat dit project een gedeelde, hoogwaardige “referentiebibliotheek” van echte colorectale kankergevallen in heel Europa heeft opgeleverd. In plaats van dat elk ziekenhuis met kleine, geïsoleerde datasets werkt, kunnen wetenschappers nu patronen bestuderen over duizenden patiënten, bevindingen toetsen in diverse populaties en nieuwe diagnostische hulpmiddelen robuust testen. Hoewel het cohort zelf geen enkel nieuw test of medicijn oplevert, legt het de basis voor vroege opsporing, meer gerichte behandelingen en beter gebruik van kunstmatige intelligentie in de pathologie. In praktische zin kan dit type zorgvuldig gereguleerd delen van gegevens ontdekkingen versnellen die artsen op termijn kunnen helpen beslissen wie echt chemotherapie nodig heeft, wie die veilig kan vermijden en hoe gevaarlijke tumoren te herkennen voordat ze uitzaaien.
Bronvermelding: Holub, P., Törnwall, O., Garcia Alvarez, E. et al. A comprehensive European Colorectal Cancer Cohort dataset. Sci Data 13, 662 (2026). https://doi.org/10.1038/s41597-026-06822-2
Trefwoorden: colorectale kanker, biobankgegevens, digitale pathologie, genomische cohort, delen van medische gegevens