Clear Sky Science · pl
Kompleksowy europejski zestaw danych kohorty raka jelita grubego
Dlaczego wspólna pula danych o nowotworach ma znaczenie
Rak jelita grubego jest jednym z najgroźniejszych nowotworów na świecie, a mimo to lekarze wciąż mają trudności z przewidywaniem, którzy pacjenci będą się dobrze rokować, a którzy potrzebują dodatkowego leczenia. Niniejszy artykuł opisuje duże europejskie przedsięwzięcie polegające na zgromadzeniu szczegółowych informacji od ponad dziesięciu tysięcy pacjentów w jednym, starannie sprawdzonym zasobie. Poprzez harmonizację kartotek szpitalnych, próbek tkankowych, zdjęć mikroskopowych i danych DNA z wielu krajów, projekt tworzy solidną podstawę do wcześniejszej diagnostyki, lepszych terapii i nowych narzędzi wspomagających opiekę onkologiczną opartej na komputerach.
Paneuropejski wysiłek przeciw wspólnemu nowotworowi
Rak jelita grubego rozwija się powoli, często przez lata, co czyni go idealnym celem badań przesiewowych i działań zapobiegawczych. Obecne testy obejmują proste badania kału oraz bardziej inwazyjne zabiegi, takie jak endoskopia; lekarze analizują też zmiany genetyczne i inne „biomarkery” w celu ukierunkowania leczenia. Jednak w praktyce klinicznej stosunkowo niewiele biomarkerów jest dobrze ugruntowanych, a wciąż pozostaje wiele otwartych pytań, np. jak najlepiej leczyć pacjentów ze stadium pośrednim choroby. Aby wypełnić te luki, Infrastruktura Badawcza ds. Biobanków i Zasobów Biomolekularnych (BBMRI-ERIC) skoordynowała 26 biobanków w 12 krajach europejskich, tworząc wspólną kohortę raka jelita grubego obejmującą 10 780 pacjentów, wszyscy z ustandaryzowanymi danymi podstawowymi i powiązanymi próbkami biologicznymi.
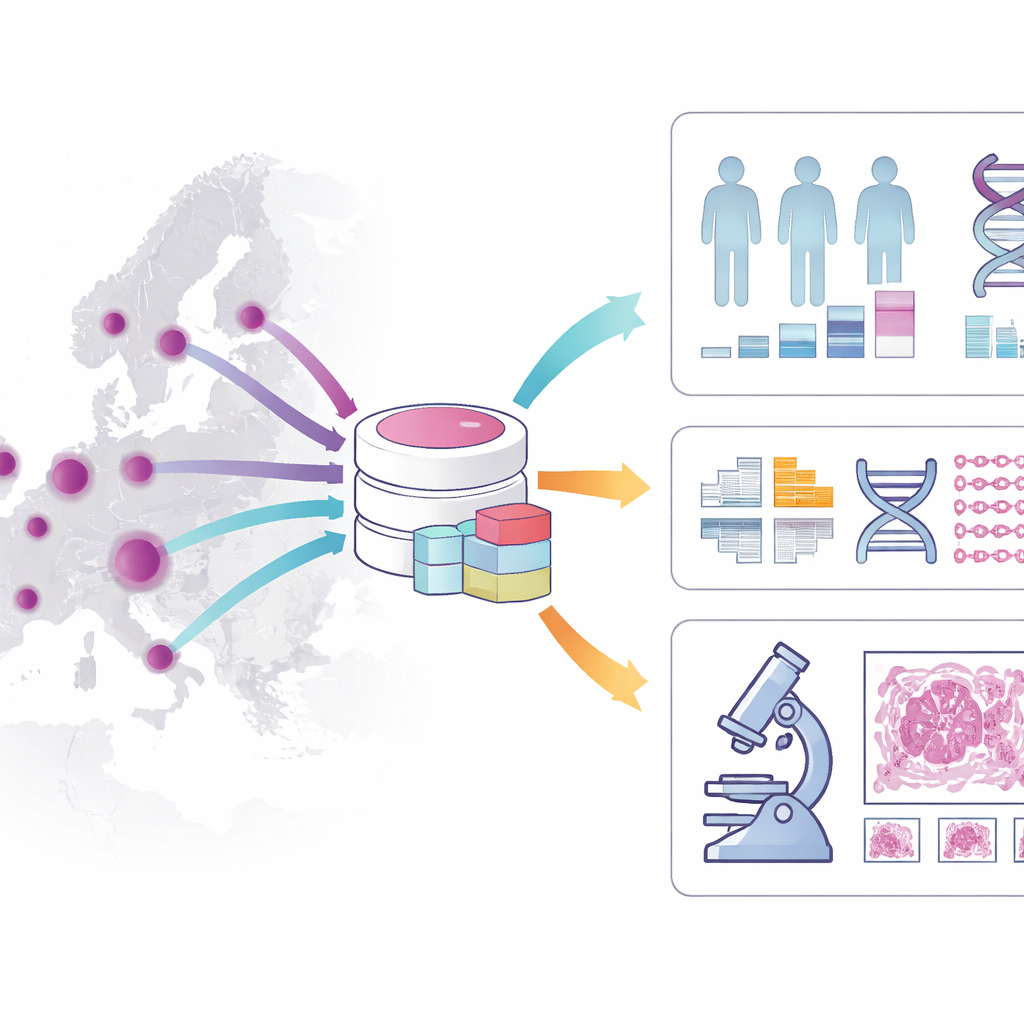
Co dokładnie zawiera kohorta?
Kohorta odzwierciedla wielowymiarowy obraz przebiegu choroby u każdego pacjenta. Zawiera wiek, płeć, szczegóły rozpoznania, czynniki ryzyka, zastosowane leczenie oraz długoterminowe przeżycie, ze szczególnym uwzględnieniem pacjentów obserwowanych przez co najmniej pięć lat. Przechowuje informacje o wyglądzie guza w mikroskopie, stadium choroby oraz kluczowych cechach molekularnych, takich jak określone mutacje genowe i zaburzenia naprawy DNA. Poza tymi danymi klinicznymi zestaw łączy się z próbkami tkankowymi przechowywanymi w biobankach szpitalnych, ponad trzema tysiącami wysokorozdzielczych skanów cyfrowych nowotworów okrężnicy oraz sekwencjonowaniem całego genomu dla setek pacjentów. Te warstwy danych razem umożliwiają powiązanie obrazu patologicznego, informacji z DNA i rzeczywistych wyników leczenia w czasie.
Przekształcanie rozproszonych zapisów w spójny zasób
Budowa takiego zasobu nie była prosta. Każdy biobank początkowo przechowywał informacje w własnych formatach, często jako proste arkusze kalkulacyjne, i stosował różne lokalne reguły oraz standardy techniczne. Zespoły projektowe opracowały wspólny model danych poprzez wielokrotne dyskusje między lekarzami, patologami, specjalistami IT i personelem biobanków, uzgadniając, które elementy informacji są niezbędne i jak je definiować. Następnie stworzyli narzędzia programowe do konwersji zróżnicowanych lokalnych tabel do jednego, ustrukturyzowanego formatu oraz do mapowania danych na powszechnie używane standardy opieki zdrowotnej. Wyrażając te same informacje w formatach takich jak openEHR, OMOP i FHIR, kohorta staje się zrozumiała dla wielu systemów szpitalnych i platform badawczych, co zwiększa jej zasięg i możliwość ponownego użycia.
Utrzymanie dokładności, prywatności i użyteczności danych
Ponieważ dane pochodziły z rutynowej opieki i wielu instytucji, jakość i prywatność były kwestiami kluczowymi. Każdy rekord został pozbawiony bezpośrednich identyfikatorów osobowych przed transferem, a każdy pacjent został zastąpiony kodowanym identyfikatorem, który tylko oryginalny biobank może powiązać z konkretną osobą. Automatyczne kontrole sprawdzają, czy daty, wiek, stadia guza i zastosowane leczenia są prawdopodobne i spójne; podejrzane wpisy, na przykład operacja mająca miejsce po zgłoszonej dacie zgonu, powodują przekazanie informacji zwrotnej do biobanku w celu korekty. Artykuł opisuje również sformalizowaną procedurę dostępu: badacze z całego świata mogą składać wnioski o korzystanie z kohorty, ale dedykowany komitet ocenia każdy wniosek pod kątem zatwierdzenia etycznego, minimalizacji danych i zgodności z celem kohorty. Biobanki zachowują prawo sprzeciwu, jeśli udostępnienie byłoby sprzeczne z lokalnymi przepisami prawnymi lub warunkami zgody.
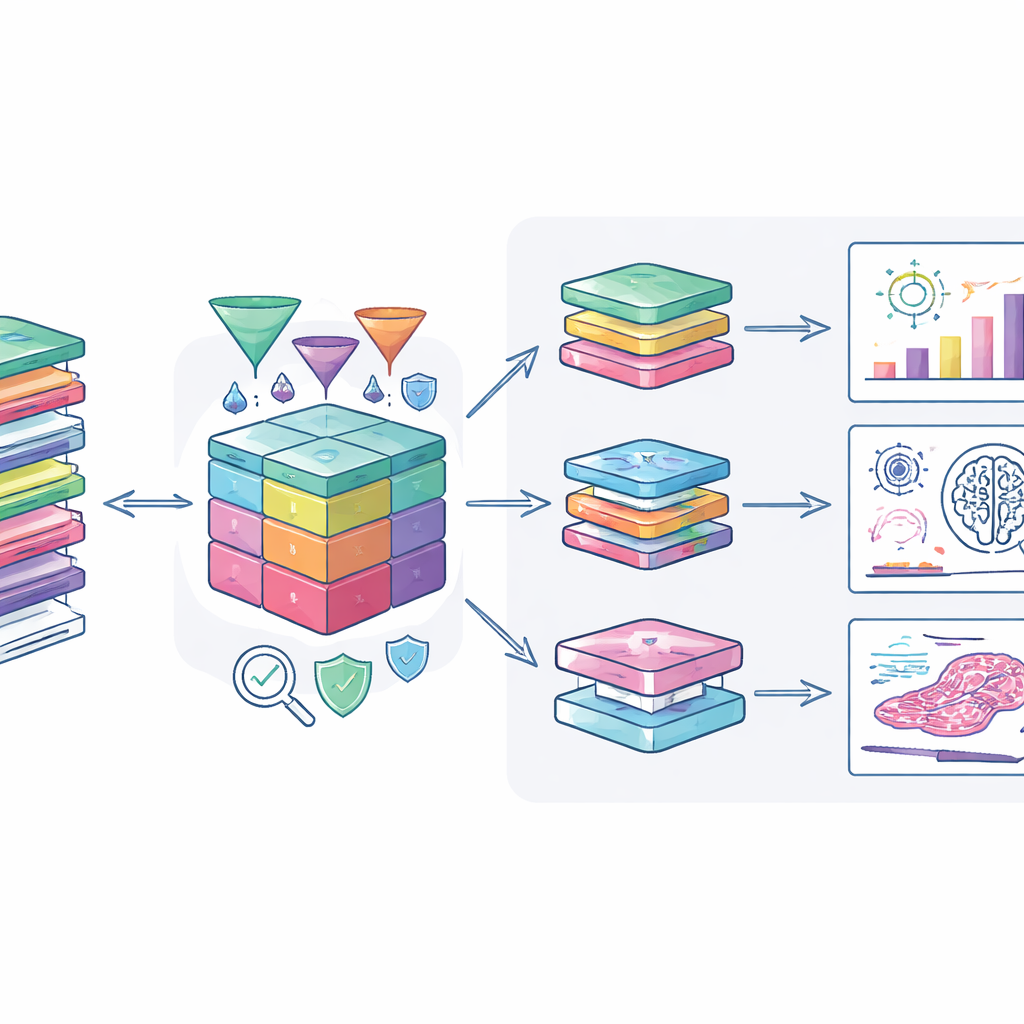
Jak naukowcy mogą to wykorzystać
Autorzy powiązali zestaw danych z nowoczesnymi narzędziami analitycznymi, tak by zatwierdzeni użytkownicy mogli bezpiecznie go eksplorować. Specjalny portal internetowy umożliwia jednoczesne przeglądanie danych klinicznych, zmian genetycznych i obrazów patologii cyfrowej, wspierając badania od poszukiwania nowych biomarkerów po trenowanie systemów sztucznej inteligencji do rozpoznawania wzorców nowotworowych. Systemy bezpiecznego transferu i szyfrowanie chronią dane podczas ich przenoszenia do środowisk obliczeniowych badaczy. Zespół zachęca również badaczy do zwracania pochodnych wyników, takich jak nowe wskaźniki ryzyka czy metody anonimizacji, aby kohorta stale zwiększała swoją wartość.
Co to oznacza dla pacjentów i medycyny
Dla czytelników niebędących specjalistami kluczowym przekazem jest to, że projekt stworzył wspólną, wysokiej jakości „bibliotekę referencyjną” rzeczywistych przypadków raka jelita grubego z całej Europy. Zamiast każdego szpitala pracującego na małych, izolowanych zbiorach danych, naukowcy mogą teraz badać wzorce obejmujące tysiące pacjentów, weryfikować wyniki na różnych populacjach i testować nowe narzędzia diagnostyczne w sposób solidny. Chociaż sama kohorta nie dostarcza jednego nowego testu czy leku, stanowi fundament dla wcześniejszego wykrywania, bardziej dopasowanych terapii i lepszego wykorzystania sztucznej inteligencji w patologii. W praktycznym wymiarze taka starannie zarządzana wymiana danych może przyspieszyć odkrycia, które w przyszłości pomogą lekarzom zdecydować, kto naprawdę potrzebuje chemioterapii, kto może jej bezpiecznie uniknąć i jak wykryć groźne guzy zanim się rozprzestrzenią.
Cytowanie: Holub, P., Törnwall, O., Garcia Alvarez, E. et al. A comprehensive European Colorectal Cancer Cohort dataset. Sci Data 13, 662 (2026). https://doi.org/10.1038/s41597-026-06822-2
Słowa kluczowe: rak jelita grubego, dane biobankowe, patologia cyfrowa, kohorta genomowa, udostępnianie danych medycznych