Clear Sky Science · en
A comprehensive European Colorectal Cancer Cohort dataset
Why a Shared Cancer Data Pool Matters
Colorectal cancer is one of the world’s deadliest cancers, yet doctors still struggle to predict which patients will do well and who needs extra treatment. This article describes a major European effort to bring together detailed information from more than ten thousand patients into a single, carefully checked resource. By harmonizing hospital records, tissue samples, microscope images, and DNA data from many countries, the project creates a powerful foundation for earlier diagnosis, smarter therapies, and new computer‑aided tools for cancer care.
A Pan-European Effort Against a Common Cancer
Colorectal cancer develops slowly, often over years, which makes it a prime target for screening and prevention. Today’s tests range from simple stool-based checks to more invasive procedures such as endoscopy, and doctors also look at genetic changes and other “biomarkers” to guide treatment. Yet only a few biomarkers are firmly established in clinics, and many open questions remain, such as how best to treat patients with intermediate disease stages. To tackle these gaps, the Biobanking and Biomolecular Resources Research Infrastructure (BBMRI-ERIC) coordinated 26 biobanks in 12 European countries to build a shared colorectal cancer cohort including 10,780 patients, all with standardized core information and linked biological samples.
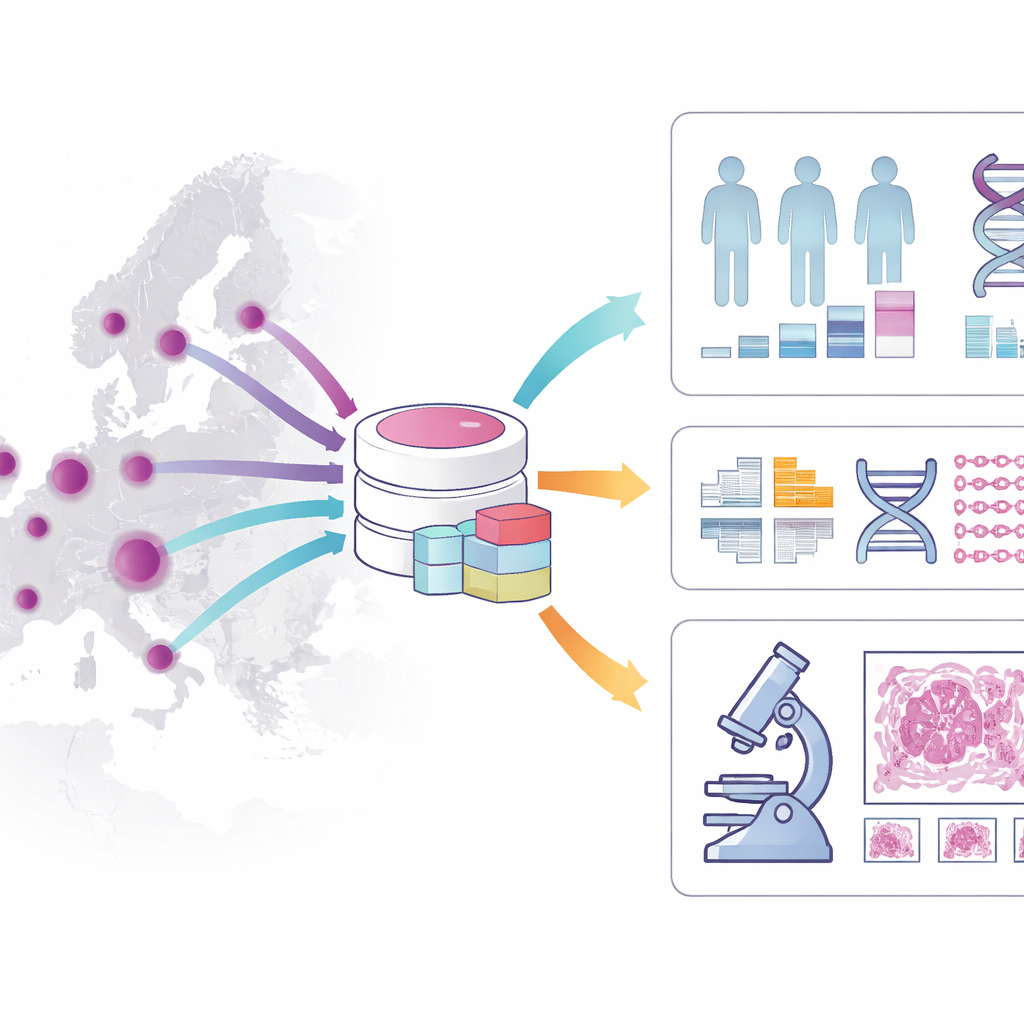
What Exactly Is in the Cohort?
The cohort captures a rich picture of each patient’s journey. It includes age, sex, diagnosis details, risk factors, treatments received, and long-term survival, with a focus on patients followed for at least five years. It stores information about tumor appearance under the microscope, disease stage, and key molecular features such as certain gene mutations and DNA repair problems. Beyond these clinical details, the dataset links to tissue samples preserved in hospital biobanks, over three thousand high‑resolution digital slides of colon tumors, and whole‑genome sequencing data for hundreds of patients. Together, these layers make it possible to connect what pathologists see, what the DNA reveals, and how patients actually fare over time.
Turning Fragmented Records into One Coherent Resource
Building such a resource was far from straightforward. Each biobank originally stored information in its own formats, often as simple spreadsheets, and followed different local rules and technical standards. The project teams designed a common data model through repeated discussions among doctors, pathologists, IT experts, and biobank staff, agreeing on which pieces of information were essential and how they should be defined. They then created software tools to convert the diverse local tables into a single, structured format and to map the data onto widely used healthcare standards. By expressing the same information in formats such as openEHR, OMOP, and FHIR, the cohort becomes understandable to many hospital systems and research platforms, increasing its reach and reuse.
Keeping Data Accurate, Private, and Useful
Because data came from routine care and many institutions, quality and privacy were central concerns. Every record was stripped of direct personal identifiers before transfer, with each patient replaced by a coded ID that only the original biobank can link back to a person. Automated checks test whether dates, ages, tumor stages, and treatments are plausible and consistent; suspicious entries, like surgery happening after a reported date of death, trigger feedback to the contributing biobank for correction. The article also describes a structured access procedure: researchers anywhere in the world can apply to use the cohort, but a dedicated committee reviews each request for ethical approval, data minimization, and alignment with the cohort’s purpose. Biobanks retain the right to object if sharing would conflict with local legal or consent rules.
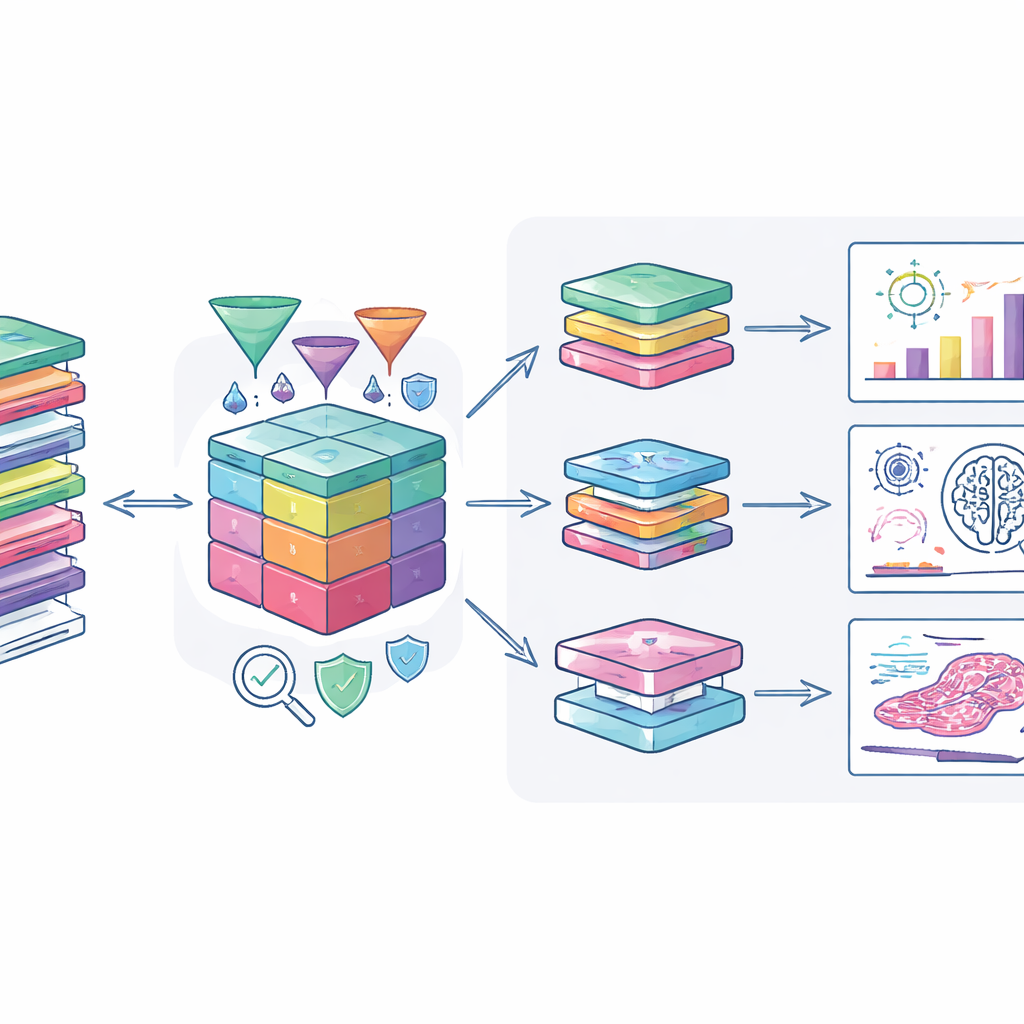
How Researchers Can Put This to Work
The authors have connected the dataset to modern analysis tools so that approved users can explore it securely. A specialized web portal allows combined viewing of clinical data, genetic changes, and digital pathology images, supporting studies that range from searching for new biomarkers to training artificial intelligence systems to recognize tumor patterns. Secure transfer systems and encryption protect data when it is moved to researchers’ own computing environments. The team also encourages investigators to return derived results, such as new risk scores or anonymization methods, so that the cohort continuously gains value.
What This Means for Patients and Medicine
For lay readers, the key message is that this project has created a shared, high‑quality “reference library” of real colorectal cancer cases across Europe. Instead of each hospital working with small, isolated datasets, scientists can now study patterns across thousands of patients, check findings against diverse populations, and test new diagnostic tools in a robust way. While the cohort itself does not deliver a single new test or drug, it lays the groundwork for earlier detection, more tailored treatments, and better use of artificial intelligence in pathology. In practical terms, this kind of carefully governed data sharing can speed up discoveries that may one day help doctors decide who truly needs chemotherapy, who can safely avoid it, and how to catch dangerous tumors before they spread.
Citation: Holub, P., Törnwall, O., Garcia Alvarez, E. et al. A comprehensive European Colorectal Cancer Cohort dataset. Sci Data 13, 662 (2026). https://doi.org/10.1038/s41597-026-06822-2
Keywords: colorectal cancer, biobank data, digital pathology, genomic cohort, medical data sharing