Clear Sky Science · fr
Un jeu de données européen exhaustif sur la cohorte du cancer colorectal
Pourquoi une base de données cancer partagée est importante
Le cancer colorectal fait partie des cancers les plus meurtriers au monde, et pourtant les médecins peinent encore à prédire quels patients s’en sortiront bien et qui nécessitera des traitements supplémentaires. Cet article décrit un important effort européen visant à rassembler des informations détaillées de plus de dix mille patients dans une ressource unique et soigneusement contrôlée. En harmonisant les dossiers hospitaliers, les échantillons de tissus, les images microscopiques et les données d’ADN provenant de nombreux pays, le projet crée une base puissante pour un diagnostic plus précoce, des thérapies plus intelligentes et de nouveaux outils assistés par ordinateur pour la prise en charge du cancer.
Un effort paneuropéen contre un cancer répandu
Le cancer colorectal se développe lentement, souvent sur plusieurs années, ce qui en fait une cible privilégiée pour le dépistage et la prévention. Les tests actuels vont de simples contrôles des selles à des procédures plus invasives comme l’endoscopie, et les médecins examinent également les modifications génétiques et d’autres « biomarqueurs » pour orienter le traitement. Pourtant, seuls quelques biomarqueurs sont solidement établis en pratique clinique, et de nombreuses questions demeurent, comme la meilleure façon de traiter les patients aux stades intermédiaires de la maladie. Pour combler ces lacunes, l’infrastructure BBMRI-ERIC (Biobanking and Biomolecular Resources Research Infrastructure) a coordonné 26 biobanques dans 12 pays européens pour constituer une cohorte partagée de cancer colorectal regroupant 10 780 patients, tous dotés d’informations de base standardisées et d’échantillons biologiques associés.
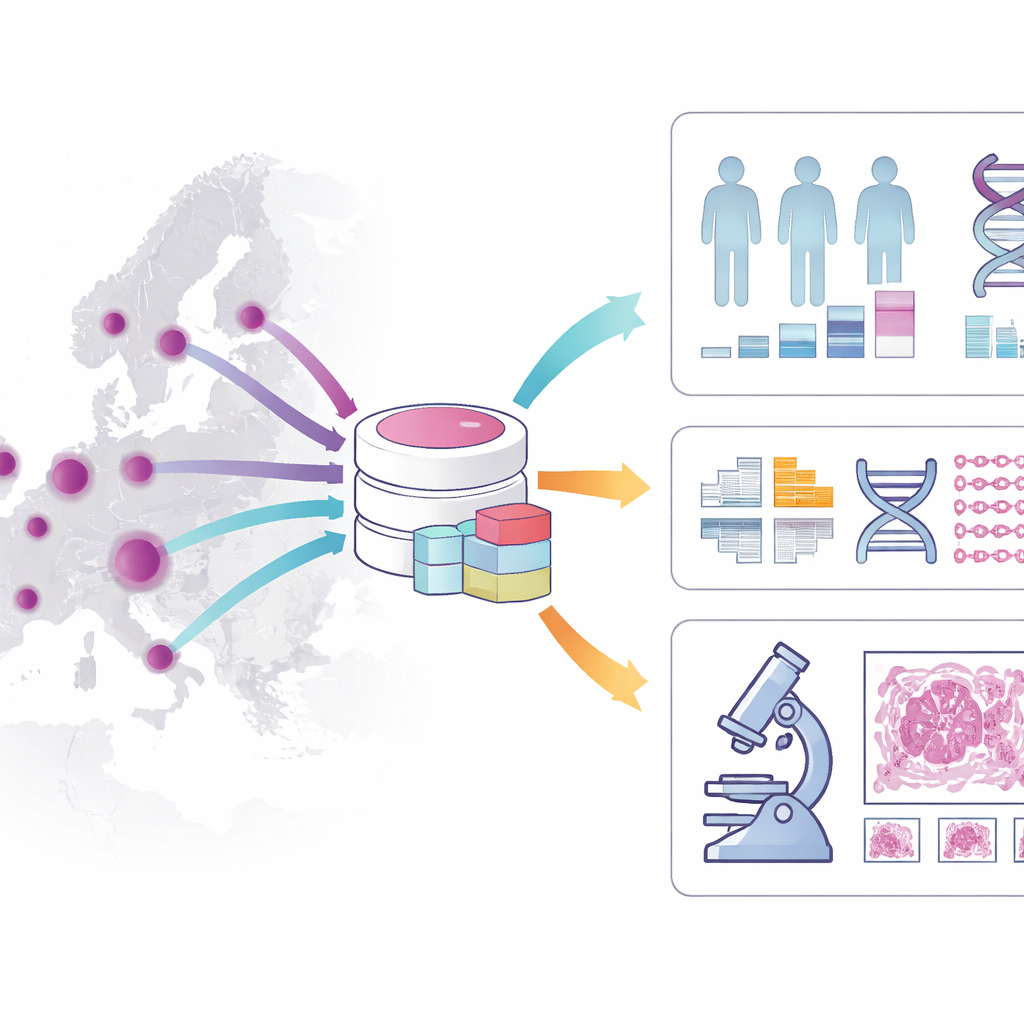
Que contient exactement la cohorte ?
La cohorte restitue un portrait détaillé du parcours de chaque patient. Elle inclut l’âge, le sexe, les détails du diagnostic, les facteurs de risque, les traitements reçus et la survie à long terme, en mettant l’accent sur les patients suivis pendant au moins cinq ans. Elle conserve des informations sur l’aspect tumoral au microscope, le stade de la maladie et des caractéristiques moléculaires clés telles que certaines mutations de gènes et des anomalies de réparation de l’ADN. Au-delà de ces éléments cliniques, l’ensemble de données est lié à des échantillons tissulaires conservés dans des biobanques hospitalières, à plus de trois mille lames numériques haute résolution de tumeurs du côlon et à des données de séquençage génomique complet pour des centaines de patients. Ces couches associées permettent de relier ce que voient les pathologistes, ce que révèle l’ADN et l’évolution réelle des patients au fil du temps.
Transformer des dossiers fragmentés en une ressource cohérente
Construire une telle ressource a été loin d’être simple. Chaque biobanque conservait initialement l’information dans ses propres formats, souvent sous forme de feuilles de calcul, et appliquait des règles et standards techniques locaux différents. Les équipes du projet ont conçu un modèle de données commun à l’issue de discussions répétées entre cliniciens, pathologistes, experts informatiques et personnels de biobanque, se mettant d’accord sur les éléments essentiels et leur définition. Elles ont ensuite créé des outils logiciels pour convertir les différents tableaux locaux en un format unique et structuré et pour cartographier les données vers des standards de santé largement utilisés. En exprimant les mêmes informations dans des formats tels qu’openEHR, OMOP et FHIR, la cohorte devient compréhensible par de nombreux systèmes hospitaliers et plates‑formes de recherche, ce qui augmente sa portée et sa réutilisation.
Maintenir la qualité, la confidentialité et l’utilité des données
Étant donné que les données provenaient de soins de routine et de nombreuses institutions, la qualité et la confidentialité ont été des enjeux centraux. Chaque dossier a été dépouillé des identifiants personnels directs avant transfert, chaque patient étant remplacé par un identifiant codé que seule la biobanque d’origine peut rattacher à une personne. Des contrôles automatisés vérifient que les dates, âges, stades tumoraux et traitements sont plausibles et cohérents ; les entrées suspectes, comme une intervention chirurgicale située après une date de décès déclarée, entraînent un retour d’information à la biobanque contributrice pour correction. L’article décrit également une procédure d’accès structurée : des chercheurs du monde entier peuvent demander l’utilisation de la cohorte, mais un comité dédié examine chaque requête pour l’approbation éthique, la minimisation des données et la conformité à l’objet de la cohorte. Les biobanques conservent le droit de s’opposer si le partage entre en conflit avec les règles légales locales ou le consentement des participants.
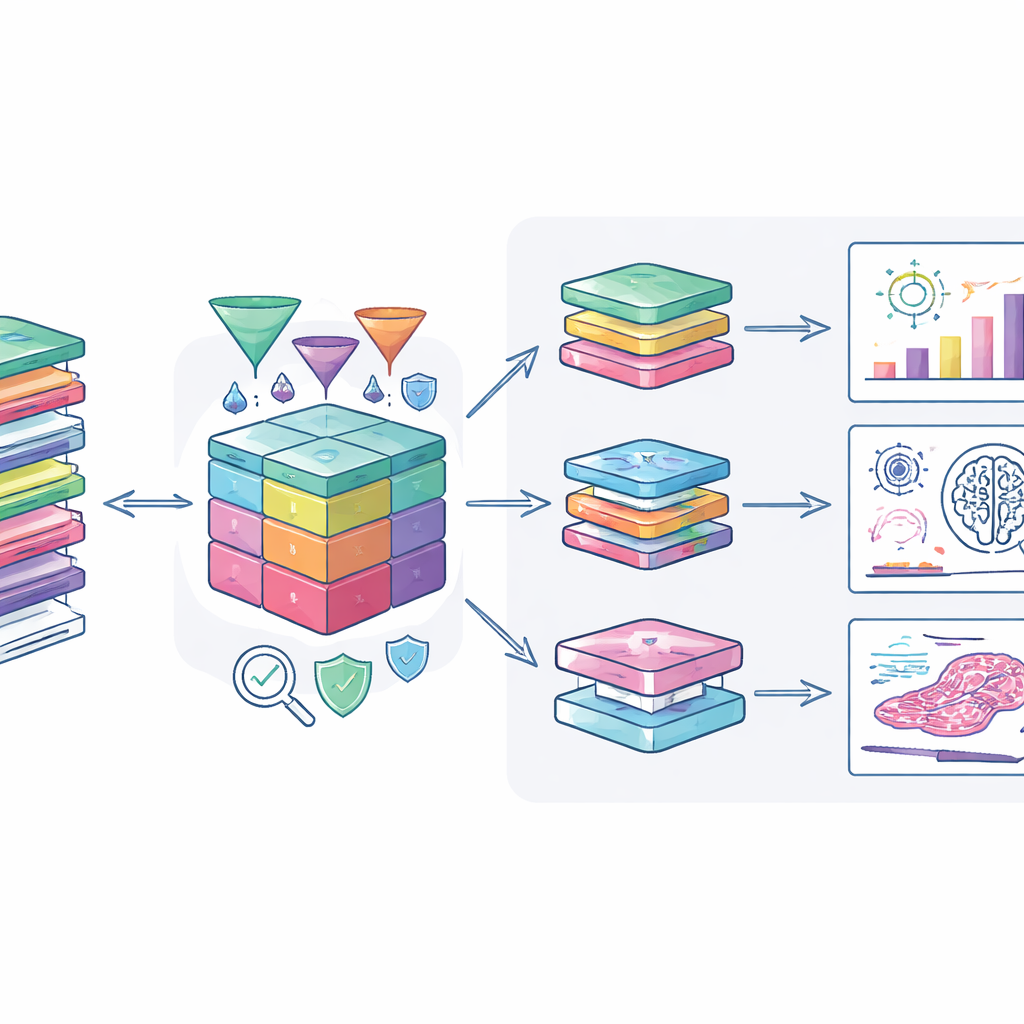
Comment les chercheurs peuvent l’exploiter
Les auteurs ont connecté le jeu de données à des outils d’analyse modernes afin que les utilisateurs autorisés puissent l’explorer en toute sécurité. Un portail web spécialisé permet la consultation combinée des données cliniques, des altérations génétiques et des images de pathologie numérique, soutenant des études allant de la recherche de nouveaux biomarqueurs à l’entraînement de systèmes d’intelligence artificielle pour reconnaître des motifs tumoraux. Des systèmes de transfert sécurisés et le chiffrement protègent les données lorsqu’elles sont déplacées vers les environnements informatiques des chercheurs. L’équipe encourage également les investigateurs à renvoyer les résultats dérivés, tels que de nouveaux scores de risque ou des méthodes d’anonymisation, afin que la cohorte gagne continuellement en valeur.
Ce que cela signifie pour les patients et la médecine
Pour le grand public, le message essentiel est que ce projet a créé une « bibliothèque de référence » partagée et de haute qualité de cas réels de cancer colorectal à l’échelle européenne. Plutôt que chaque hôpital travaille sur de petits jeux de données isolés, les scientifiques peuvent désormais étudier des tendances sur des milliers de patients, vérifier des résultats sur des populations diverses et tester de nouveaux outils diagnostiques de manière robuste. Si la cohorte elle‑même n’apporte pas un test ou un médicament unique, elle jette les bases d’une détection plus précoce, de traitements mieux ciblés et d’un meilleur usage de l’intelligence artificielle en pathologie. En termes concrets, ce type de partage de données gouverné avec soin peut accélérer les découvertes qui aideront un jour les médecins à décider qui a réellement besoin d’une chimiothérapie, qui peut l’éviter en toute sécurité et comment détecter des tumeurs dangereuses avant qu’elles ne se propagent.
Citation: Holub, P., Törnwall, O., Garcia Alvarez, E. et al. A comprehensive European Colorectal Cancer Cohort dataset. Sci Data 13, 662 (2026). https://doi.org/10.1038/s41597-026-06822-2
Mots-clés: cancer colorectal, données de biobanque, pathologie numérique, cohorte génomique, partage de données médicales