Clear Sky Science · es
Un conjunto de datos integral de cohortes europeas de cáncer colorrectal
Por qué importa un depósito compartido de datos sobre cáncer
El cáncer colorrectal es uno de los cánceres más mortales del mundo, y sin embargo los médicos todavía tienen dificultades para predecir qué pacientes tendrán un buen pronóstico y quién necesita tratamiento adicional. Este artículo describe un importante esfuerzo europeo por reunir información detallada de más de diez mil pacientes en un único recurso cuidadosamente verificado. Al armonizar historiales hospitalarios, muestras tisulares, imágenes de microscopio y datos de ADN procedentes de muchos países, el proyecto crea una base potente para el diagnóstico temprano, terapias más inteligentes y nuevas herramientas asistidas por ordenador para el cuidado del cáncer.
Un esfuerzo paneuropeo contra un cáncer común
El cáncer colorrectal se desarrolla de forma lenta, a menudo durante años, lo que lo convierte en un objetivo idóneo para la detección y la prevención. Las pruebas actuales van desde chequeos sencillos basados en heces hasta procedimientos más invasivos como la endoscopia, y los médicos también analizan cambios genéticos y otros “biomarcadores” para orientar el tratamiento. Sin embargo, solo unos pocos biomarcadores están firmemente establecidos en la práctica clínica, y quedan muchas preguntas abiertas, por ejemplo cuál es el mejor tratamiento para pacientes en estadios intermedios de la enfermedad. Para abordar estas lagunas, la Infraestructura de Investigación de Biobancos y Recursos Biomoleculares (BBMRI-ERIC) coordinó 26 biobancos en 12 países europeos para construir una cohorte compartida de cáncer colorrectal que incluye 10.780 pacientes, todos con información central estandarizada y muestras biológicas vinculadas.
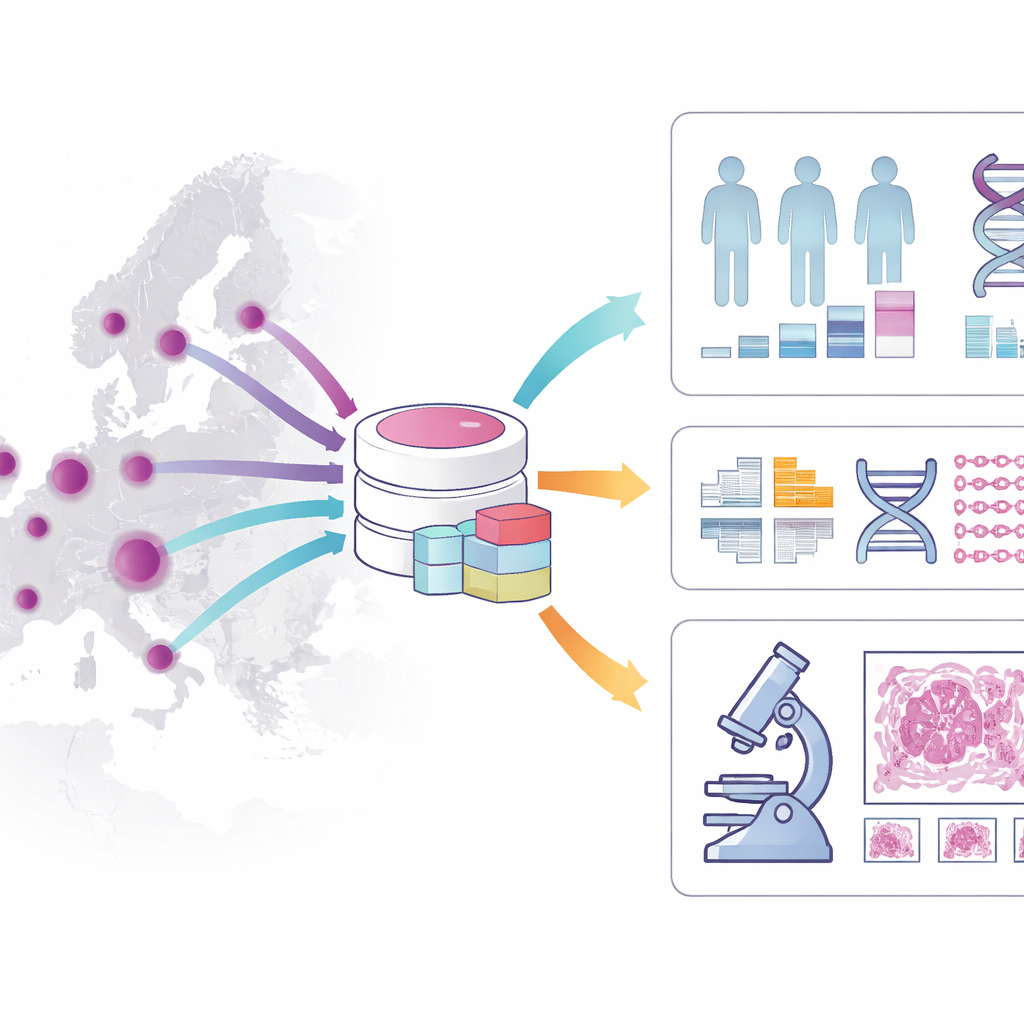
¿Qué contiene exactamente la cohorte?
La cohorte captura una imagen rica del recorrido de cada paciente. Incluye edad, sexo, detalles del diagnóstico, factores de riesgo, tratamientos recibidos y supervivencia a largo plazo, con especial atención a pacientes seguidos durante al menos cinco años. Almacena información sobre la apariencia del tumor al microscopio, el estadio de la enfermedad y características moleculares clave, como ciertas mutaciones génicas y problemas en la reparación del ADN. Más allá de estos datos clínicos, el conjunto de datos está vinculado a muestras tisulares conservadas en biobancos hospitalarios, a más de tres mil láminas digitales de alta resolución de tumores de colon y a datos de secuenciación del genoma completo de cientos de pacientes. En conjunto, estas capas permiten conectar lo que ven los patólogos, lo que revela el ADN y cómo evolucionan realmente los pacientes con el tiempo.
Convertir registros fragmentados en un recurso coherente
Construir un recurso así distó mucho de ser sencillo. Cada biobanco almacenaba originalmente la información en sus propios formatos, a menudo en hojas de cálculo sencillas, y seguía distintas normas y estándares técnicos locales. Los equipos del proyecto diseñaron un modelo de datos común mediante discusiones repetidas entre médicos, patólogos, expertos en TI y personal de biobancos, acordando qué piezas de información eran esenciales y cómo debían definirse. Después crearon herramientas de software para convertir las diversas tablas locales a un único formato estructurado y para mapear los datos a estándares sanitarios ampliamente usados. Al expresar la misma información en formatos como openEHR, OMOP y FHIR, la cohorte se vuelve comprensible para muchos sistemas hospitalarios y plataformas de investigación, aumentando su alcance y posibilidad de reutilización.
Mantener los datos precisos, privados y útiles
Puesto que los datos procedían de la atención rutinaria y de muchas instituciones, la calidad y la privacidad fueron preocupaciones centrales. Cada registro se despojó de identificadores personales directos antes de la transferencia, sustituyendo a cada paciente por un identificador codificado que solo el biobanco original puede vincular de nuevo a una persona. Comprobaciones automáticas verifican si las fechas, las edades, los estadios tumorales y los tratamientos son plausibles y consistentes; las entradas sospechosas, como una cirugía registrada después de una fecha de defunción, generan retroalimentación al biobanco contribuyente para su corrección. El artículo también describe un procedimiento estructurado de acceso: investigadores de cualquier parte del mundo pueden solicitar el uso de la cohorte, pero un comité dedicado revisa cada petición para la aprobación ética, la minimización de datos y la alineación con el propósito de la cohorte. Los biobancos conservan el derecho de objetar si el intercambio entrara en conflicto con la normativa local o las reglas de consentimiento.
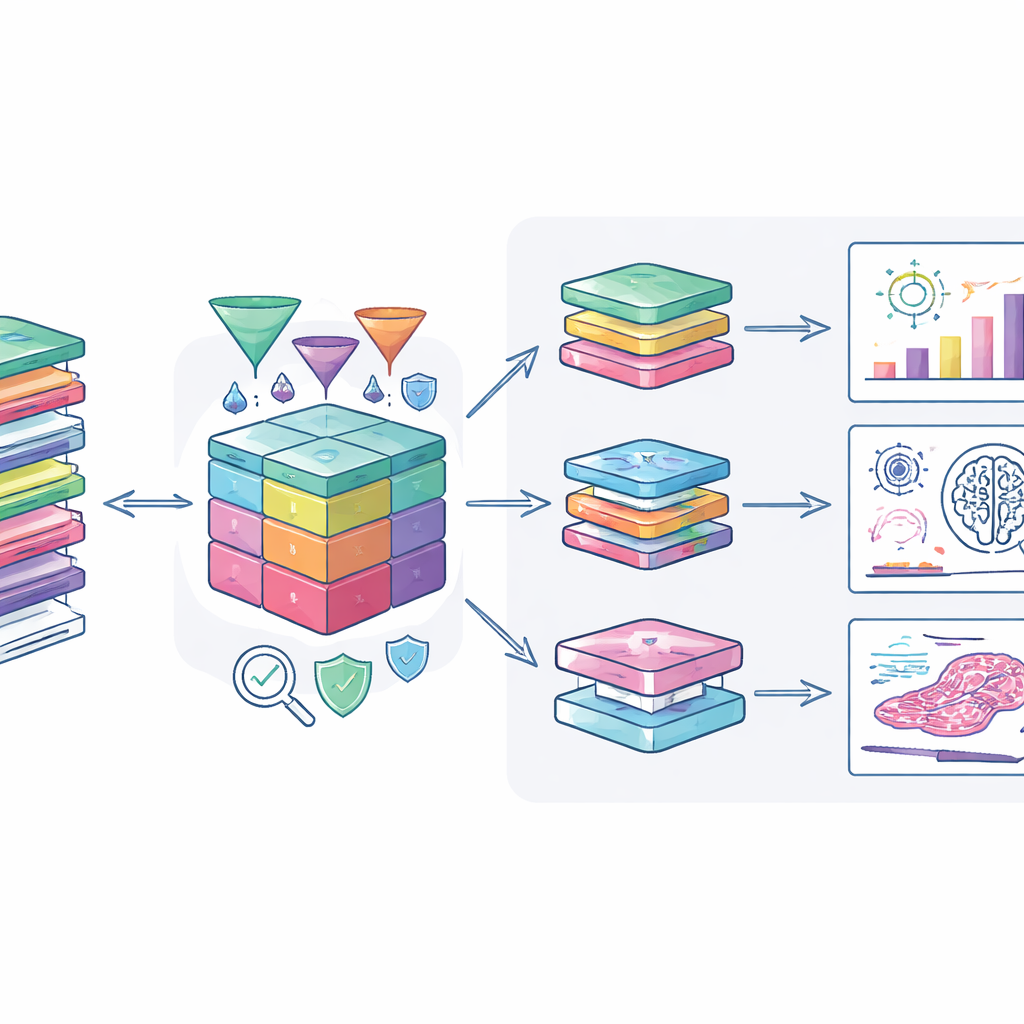
Cómo pueden los investigadores aprovechar esto
Los autores han conectado el conjunto de datos a herramientas de análisis modernas para que los usuarios aprobados puedan explorarlo de forma segura. Un portal web especializado permite la visualización combinada de datos clínicos, cambios genéticos e imágenes de patología digital, apoyando estudios que van desde la búsqueda de nuevos biomarcadores hasta el entrenamiento de sistemas de inteligencia artificial para reconocer patrones tumorales. Sistemas de transferencia segura y cifrado protegen los datos cuando se trasladan a los entornos informáticos de los investigadores. El equipo también anima a los investigadores a devolver los resultados derivados, como nuevas puntuaciones de riesgo o métodos de anonimización, de modo que la cohorte gane valor de forma continua.
Qué supone esto para los pacientes y la medicina
Para el lector no especializado, el mensaje principal es que este proyecto ha creado una “biblioteca de referencia” compartida y de alta calidad de casos reales de cáncer colorrectal en toda Europa. En lugar de que cada hospital trabaje con conjuntos de datos pequeños y aislados, los científicos pueden ahora estudiar patrones en miles de pacientes, comprobar hallazgos en poblaciones diversas y probar nuevas herramientas diagnósticas de forma robusta. Si bien la cohorte en sí no ofrece una prueba o fármaco nuevo único, sienta las bases para una detección más temprana, tratamientos más personalizados y un mejor uso de la inteligencia artificial en patología. En términos prácticos, este tipo de intercambio de datos gobernado con cuidado puede acelerar descubrimientos que algún día ayuden a los médicos a decidir quién necesita realmente quimioterapia, quién puede evitarla de forma segura y cómo detectar tumores peligrosos antes de que se diseminen.
Cita: Holub, P., Törnwall, O., Garcia Alvarez, E. et al. A comprehensive European Colorectal Cancer Cohort dataset. Sci Data 13, 662 (2026). https://doi.org/10.1038/s41597-026-06822-2
Palabras clave: cáncer colorrectal, datos de biobanco, patología digital, cohorte genómica, compartición de datos médicos